
人类花了半个世纪,把文档从打字机搬到了Word;又花了二十年,将它们搬上云端。结果到了AI时代,真正的通用格式,却是一门诞生于2004年的纯文本语言——Markdown。
最近,Claude Code的工程师Thariq提出了一个有趣的观点:他已经不用Markdown了,HTML才是未来。这番言论引发了大量讨论。
▲ Claude Code工程师Thariq分享的用HTML替代Markdown的文章,在X平台上已获得千万次浏览
他在文章里指出,AI输出HTML格式,比输出Markdown文本是更好的形态。对AI而言,从Markdown转换到HTML几乎是无痛的,但对用户来说,体验却是实打实的提升。
这个观点甚至得到了Karpathy的转发。在他看来,音频是大语言模型最好的输入,视觉则是最好的输出。他畅想的未来路线里,HTML之后还会有交互动画、神经网络直接生成的视频,最终走向某种人机之间真正的感知融合。

在Vibe Coding和智能体(Agent)产品逐渐成为主流的背景下,HTML和Markdown对大多数AI玩家来说,早已不是陌生概念。
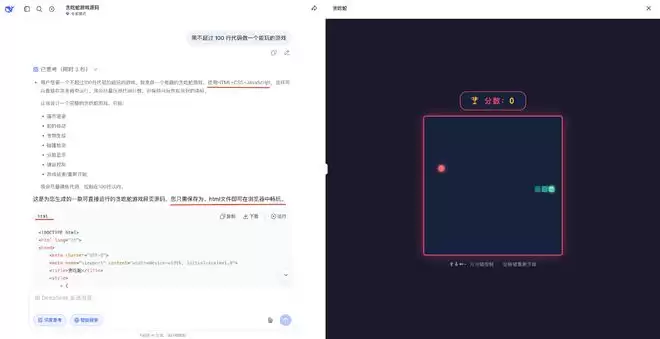
▲ 在DeepSeek中要求它做一个小游戏,它会直接给出一段可运行的HTML代码文件
比如,你想做一个小游戏,只需告诉ChatGPT:“帮我做一个贪吃蛇的单页HTML网页。”它就会生成一个后缀为.html的文档。双击打开,一个可交互、有动效、图文并茂的成果就在浏览器里跑起来了。
甚至在浏览器里,对任何一个网页按下Ctrl+S,保存下来的本地文件,也总是一个.html文档。
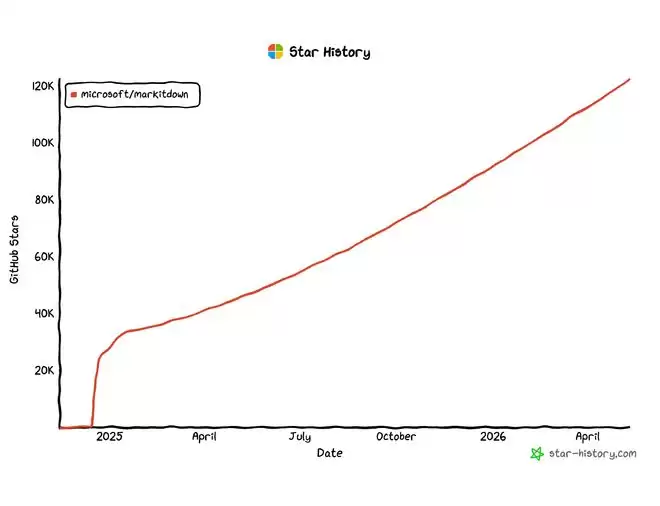
而Markdown,从AI需要获取网页上下文的年代起,就有大量工具将各类文档转换成它的格式。微软作为办公三件套的王者,拥有docx、pptx、xlsx等职场主流格式,早前也开源了一个将这些办公文档转为Markdown的项目,在GitHub上已收获超过12万颗星。
OpenClaw爆火之后,各种AGENT.md、SOUL.md、CLAUDE.md、MEMORY.md……乃至技能(Skills)工程中,每个技能也往往是一个Skill.md文档。从记忆保存到提示词与智能体的控制,Markdown格式几乎成了AI获取丰富上下文的不二之选。
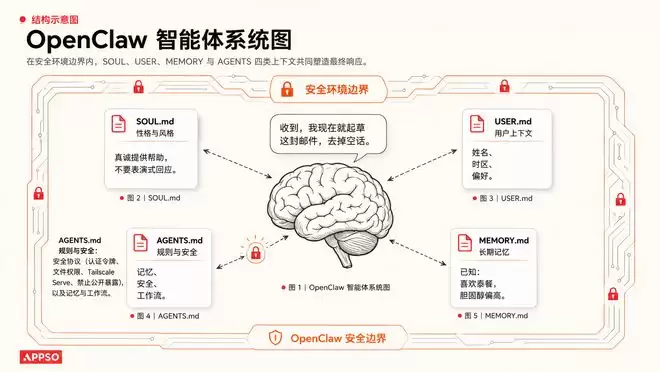
▲ OpenClaw智能体会通过多个不同的Markdown文件来搭建最终的工作区|图片由AI生成
相比之下,我们日常工作中最常用的PDF、DOC、PPT,反而在AI时代成了“最不受待见”的格式。
那么,现在冒出来的HTML又是怎么回事?它有机会取代Markdown,成为AI时代的新通用语言吗?
Markdown为什么最适合AI
先聊聊为什么Markdown能成为AI时代的“Word”。无论是AI的回答,还是我们投喂给AI的上下文,如今大多都以Markdown为主。
这门语言诞生于2004年,灵感来源于千禧年代初电子邮件的文本排版习惯——竖线分隔、80字符换行、星号表示强调。它的设计目标是“写起来像纯文本,渲染出来像HTML”。它足够简单,足够便携,不需要任何特殊工具,任何文本编辑器都能处理。

▲ Markdown语法速查表|图片由AI生成
这套设计哲学在博客时代堪称完美。2008年前后,随着GitHub崛起,Markdown直接成为了程序员的标准写作格式。各类技术文档、Stack Overflow回答、GitHub README、技术博客……Markdown在所有这些场景中都游刃有余。
然后,大语言模型的时代来了。
一方面,训练数据中恰好包含了大量Markdown格式的文本,模型学会了用它来表达结构。换句话说,训练数据里那些技术博客和论坛中“聪明人写的东西”,很多都是Markdown。模型学到的不仅是格式,还有“用Markdown写作等于认真、结构化、专业”这种关联。
另一方面,Markdown的结构信号非常局部化。一个标题只需要一个#,一个列表项只需要一个-,**出现就意味着加粗。模型不需要看很远的上下文,就能判断当前token的语义角色。
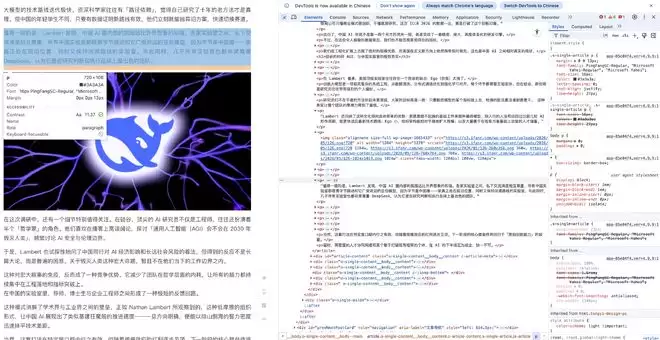
▲ 同样一篇文章,HTML意味着繁多的标签、各种区块的分隔以及样式控制等
对比一下HTML的标题(
...
)和列表(- ...
标签要等到
才闭合,语义跨度长,模型生成时需要“记住”更远的状态。这对模型生成来说负担更重,出错概率也更高。所以,无论是从大语言模型注意力机制的技术角度,还是从Token经济学的角度看,“能用Markdown就不用HTML”在长文档、多轮对话、大量API调用的场景里,成了工程师和模型双方心照不宣的偏好。
总结下来,Token效率高、结构清晰、解析简单这三大核心价值,让模型天然偏爱Markdown。它既爱Markdown格式的输入,也爱Markdown格式的输出。
这种偏好在模型训练过程中被进一步强化了。在进行人类反馈强化学习(RLHF)时,标注员给出高分的回答,大概率是那些有清晰标题、分点列举、结构一目了然的答案。而这种视觉结构,在纯文本环境里,恰恰就是Markdown。
于是,模型学到的奖励信号变成了:使用Markdown格式化 = 看起来更认真、更完整、更值得高分。即使问题本身根本不需要列表,模型也会倾向于加上列表。
▲ 知名的Markdown编辑器Typora
这大概解释了,为什么我们随便问ChatGPT一个问题,它总想给出三个要点、加粗关键词、再来个小结。也解释了为什么在大多数AI对话界面,复制AI的回答粘贴到别处时,总会自动带上#、**、---这些Markdown标记。
我们看到的每一条AI回复的文字消息,底层基本上都是以Markdown格式在渲染。
为什么不是PDF、Word、PPT
Markdown虽好,但我们日常工作中处理的文档,大多还是PDF和Word。老板发来一个文件,我丢给AI处理,往往比直接复制粘贴要耗费更多时间。
本质原因在于,模型只认识token,不认识文件。
大语言模型的输入,在进入模型之前必须先被转换成token序列。模型看不到“一个PDF”,它看到的是PDF被解析出来的文本内容,然后再被切分成token。因此,哪种格式在解析成纯文本后,损失的信息最少、引入的噪声最少,哪种格式就是更好的格式。
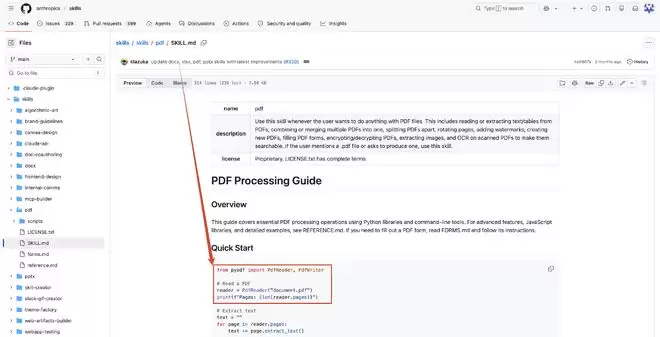
▲ Claude最新的PDF技能,需要调用专门的工具库才能实现PDF文件读取
PDF的设计目标是“打印出来好看”,而非“机器好读”。PDF内部存储的是每个字符的坐标位置,而不是文本的逻辑顺序。一个两栏布局的PDF,解析出来的文本顺序很可能是:左栏第一行、右栏第一行、左栏第二行、右栏第二行……完全乱套。
表格的情况更糟。PDF里的表格通常是用绝对坐标定位的文本块,没有任何“这是一行”“这是一列”的语义信息。对AI PDF解析器来说,只能靠猜。
扫描版PDF就更不用提了,它直接是图片,需要先经过OCR文本识别,而OCR的错误率会直接进入模型的上下文。

.docx和.pptx本质上是一个ZIP压缩包,里面是一堆XML文件。解析出来的原始内容充斥着大量样式标记——字体、颜色、段落间距、主题、修订记录……这些对模型理解内容毫无帮助,却会占用大量token,稀释真正有用的信息。
对PPT来说,信息密度本来就低。一张幻灯片可能只有一句话、几个关键词,解析出来是碎片化的文本,缺乏上下文连接,模型很难重建完整的逻辑。
有人可能会问,那TXT呢?其实,Markdown和Word这类文本,本质上都可以转换成TXT文档。它没有额外噪声,但也没有任何结构信号。
模型很难定位哪里是标题、哪里是列表、哪里是代码块、哪里是引用。对于长文档,这意味着模型要靠自然语言线索去猜测结构,准确率很不稳定。

▲ 图片由AI生成
类似的语言还有JSON/XML。它们确实对机器更友好,但这里的“机器”指的并非语言模型。
JSON和XML是为程序解析设计的,强调键值对、层级结构和严格语法。传统软件读JSON很舒服,因为它可以直接`json.parse()`,得到一个结构化对象。
而语言模型的“理解”,是通过token之间的统计关联实现的。对语言模型来说,读JSON和读自然语言的方式是一样的,都是逐token处理,依靠注意力机制建立关联。把这种严格结构化的格式喂给一个为模糊、灵活输入而设计的系统,本身是一种错配。
Markdown恰好处于两者之间。它是纯文本,但带有轻量的结构信号。

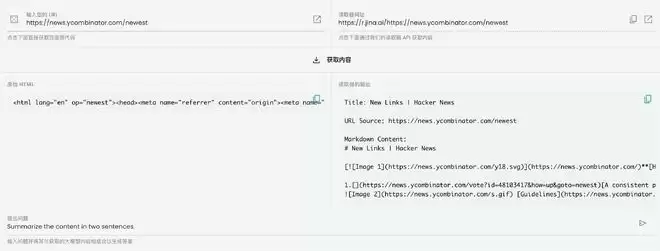
▲ 部分工具如Jina Reader,在网页URL前添加r.jina.ai前缀,就能将任何网页转换为LLM友好的Markdown
解析Markdown不需要任何特殊工具,直接读文本就行。不会有PDF那种坐标混乱,也不会有Word那种XML噪声。同时,#、**、-这些符号给了模型足够的结构线索,让它知道这段是标题、那段是列表、另一段是代码。
这些符号本身就在token词表里,模型可以直接处理,不需要任何预处理步骤。
Markdown也要过时了?
在Claude Code工程师的那篇文章里,他细数了HTML的几大优点。

▲ 图片由AI生成
首先是信息密度更高。HTML能传达的信息远比Markdown丰富。它不仅能做基础的文档结构和标题格式,还能表示CSS样式、SVG图片、canvas空间数据、流程图,以及通过img标签插入图片等等。
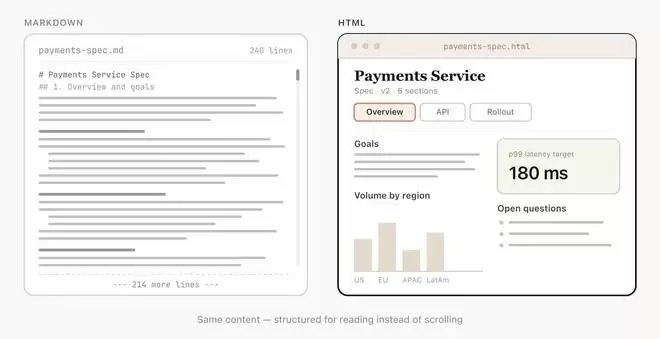
他还提到,Claude能处理的工作越来越复杂,它写的需求文档和计划也越来越长。超过100行的Markdown文件根本读不下去,更别说让其他人去读了。
但HTML文档的阅读体验就轻松得多。Claude可以用标签页、插图、链接等方式把结构组织得清晰易导航。它甚至能做到响应式布局,在不同设备上都能提供舒适的阅读体验。
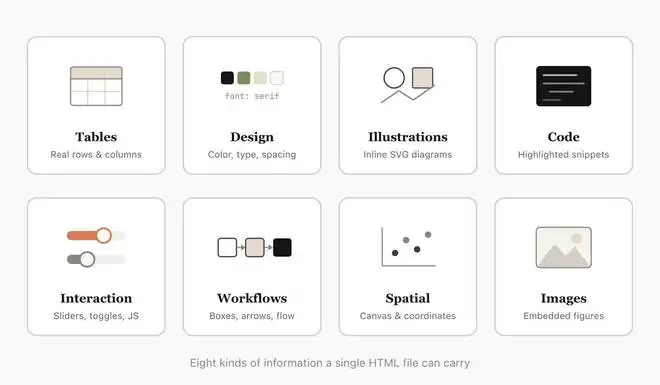
在分享便利性上,他也认为HTML比Markdown更容易传播。把一个HTML文件随便放到某个云平台上,把这个链接发给朋友,比起发一份Markdown文档,对方点开链接阅读的几率无疑要大得多。
就像现在做报告,与其展示几十页的PPT,不如直接打开一个网页。市面上常见的深度研究产品,在生成PPT时,所采用的格式往往也是从渲染HTML网页开始的。
还有HTML的交互性。我们可以点击不同的按钮、使用滑块或旋钮来调节不同的信息展示方式。
当提到Markdown输出的Token比HTML少、更省时间时,他承认HTML可能比Markdown慢2-4倍,但认为值得。因为HTML带来的表达力提升,以及用户真正去阅读它的概率大幅提高,最终产出的效果反而更好。
我们也尝试将Thariq的这篇长文转换成HTML格式。相较于X推文的长截图,HTML呈现的内容对读者确实更友好。

针对“HTML更合适给人阅读”这点,文章所列的优点听起来确实是Markdown难以企及的。但直接将HTML描绘成新的AI通用语言,恐怕还为时过早。
难道我们未来的每一次会话,都要等待AI输出一个样式精美、交互友好的网页吗?
想象一下和朋友闲聊,你不会希望他盛装打扮,更不会想让他化妆一小时,让你原地等待。
更何况,大多数用户接触到的AI——即那些不针对编程、设计等特定领域的通用AI——全部都是以对话形式在交互。我们的会话或许并不需要一份精美的HTML,现有的Markdown就已经足够了。
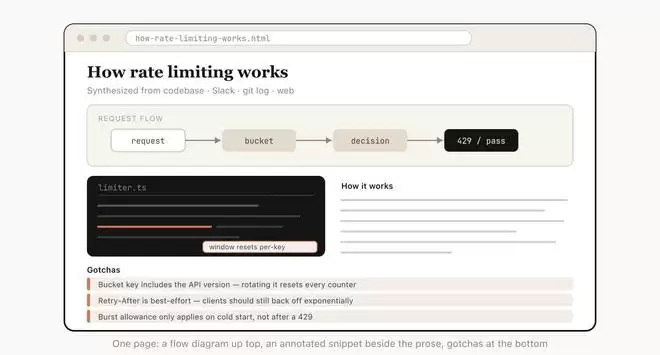
Claude Code工程师在文章里也提到了HTML适用的项目类型:例如要求AI生成一份详细的需求文档,包括规划项目和探索不同的设计方案;或是用于可视化代码审查和理解;制作交互原型,比如动画和动作效果;以及研究报告等使用场景。
而这些场景,本来就是适合网页呈现的场景。用它来挑战Markdown的“通用”地位,多少有点胜之不武。
作者最终得出的论点是:HTML作为AI交付给人类的最终产物,更好读。但他并没有主张用HTML作为AI的工作记忆或上下文格式。因为在这一领域,Markdown目前就是所有AI的唯一解决方案。
Markdown最终会走向哪里?
Markdown是AI的工作语言,是上下文的载体,是智能体之间传递信息的格式。但它可能不需要是用户最终看到的东西。HTML,或者未来某种更好的格式,是Markdown被渲染之后的界面。
HTML无需挑战Markdown的地位,它只需要承担起Markdown从来就不需要承担的那个角色——最终呈现。
Markdown可以是HTML的一部分。我们在网页上和AI聊天,AI给我们的回复使用Markdown,而此时,它正被嵌入在HTML里。
未来的Markdown,或许会像一块积木,被嵌入到HTML,甚至是某种更精美的XTML语言里。

▲ 图片由AI生成
格式会一直向前演进。HTML是此刻的前台,但也只是此刻的。下一站可能是可交互的3D空间,再下一站可能是直接写入视网膜的信号流。
但无论前台换成什么,后台运行的很可能还是Markdown。它不会被取代,只会被遗忘。而在技术的世界里,被所有人遗忘,恰恰是一种格式取得最终胜利的方式。
每一代人都在争论下一个界面是什么。但真正活下来的,从来不是界面,而是协议。




