关于DeepSeek的讨论,正从最初的技术惊叹,转向更为具体和复杂的审视。市场在问:这家曾以一己之力定义“中国技术理想主义”的公司,能否在沉寂近五个月后,再次证明其技术领导力?它庞大的技术势能,又该如何转化为可持续的商业营收?更进一步,在国产算力生态尚不完善的当下,它能否成为那个用国产AI芯片训练出顶尖模型的“破局者”?
四月初,外媒The Information传出消息,称DeepSeek V4或于四月下旬发布,并可能率先支持华&为新一代AI芯片昇腾950PR。随后,该媒体又报道DeepSeek正寻求首轮外部融资,估值不低于100亿美元。尽管这些消息均未得到官方证实,且据《财经》从相关资本机构了解,其估值与融资规模信息并不准确,但每一次传闻都能引发市场的广泛关注与讨论,这本身已成为一个值得玩味的现象。
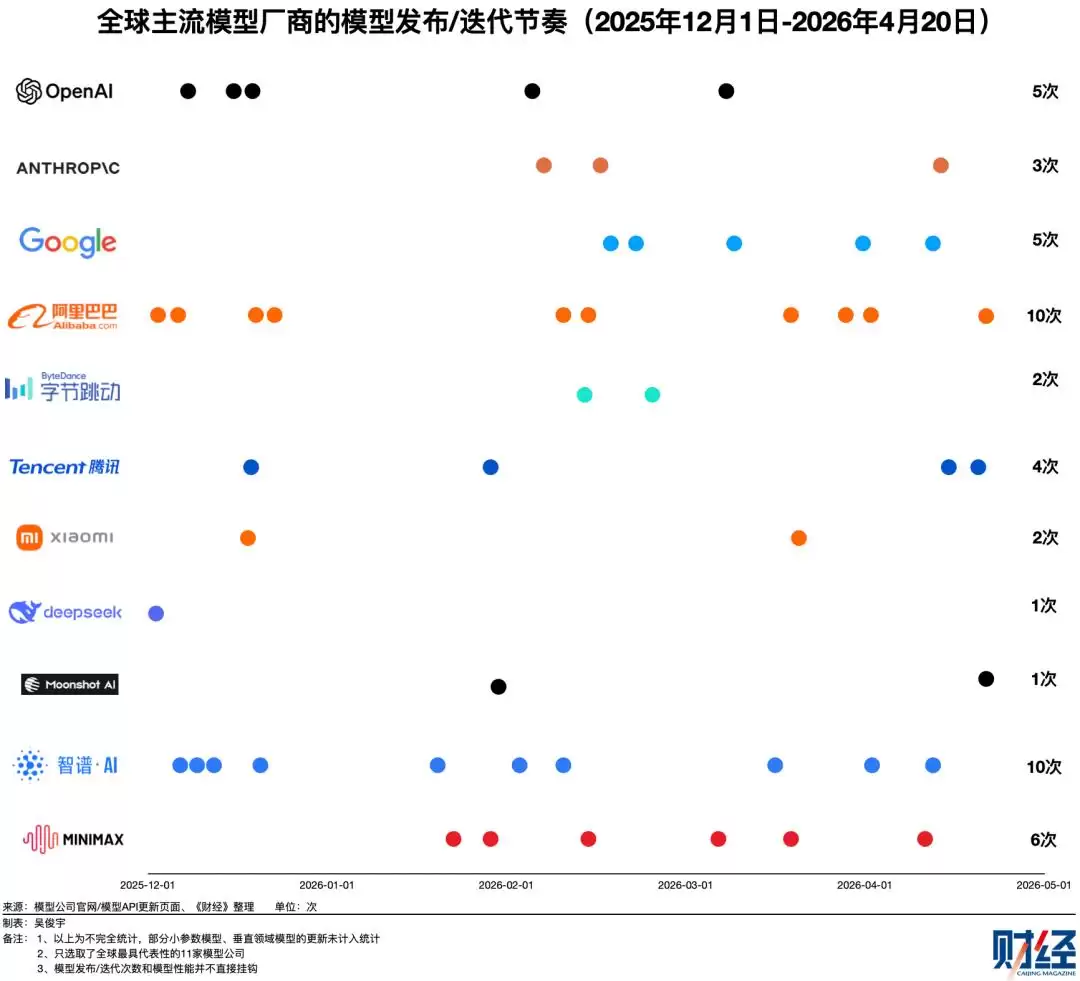
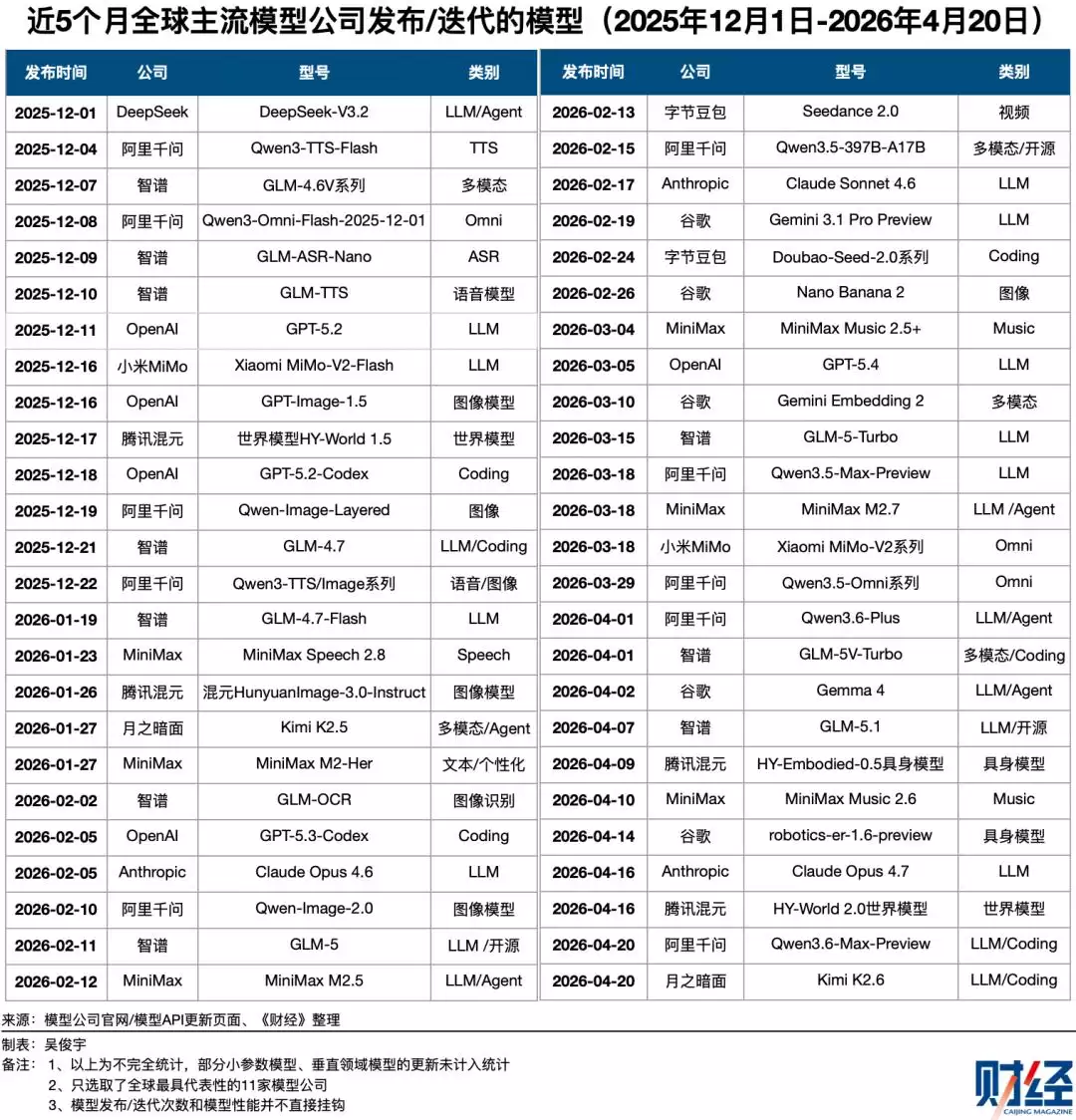
与频繁发声、高歌猛进的同行们不同,DeepSeek显得异常沉默。自2025年12月1日发布DeepSeek-V3.2后,这家公司已有近五个月没有推出新模型。相比之下,从2025年12月初到2026年4月20日,中美主流11家模型公司至少发布或迭代了50款模型,平均每2.8天就有一款新品问世。DeepSeek的发布节奏,在主流厂商中几乎是最低的。
沉默带来的是性能排名的滑落。那个在2025年初凭DeepSeek-R1惊艳全球、几乎追平当时OpenAI o1的“挑战者”,其最新版本V3.2在多项基准测试中已不再领先。如今,它正站在一个十字路口:是继续坚持研究驱动的低频创新,还是转向更高频的产品迭代与商业化,以应对白热化的市场竞争?
性能光环的褪色与市场份额的韧性
近五个月的“空窗期”,直接反映在性能榜单上。根据Artificial Analysis截至4月20日的测试,DeepSeek-V3.2的综合性能、代码生成(Coding)性能和智能体(Agent)性能,分别位列全球第16、17和15名,落后于OpenAI、Anthropic、谷歌,以及国内的阿里、月之暗面、智谱等公司的旗舰模型。
更关键的是,2026年模型竞赛的焦点已从纯文本推理转向了智能体(Agent)能力,而代码生成能力正是智能体的核心引擎。代码能力的强弱,直接决定了智能体任务的成功率、执行效率和Token消耗成本。在这个新赛道上,DeepSeek-V3.2与头部模型的差距被迅速拉大。行业内的反馈也印证了这一点:前沿开发者在处理高要求的代码或Agent任务时,若不计成本会首选OpenAI或Anthropic;追求性价比则会考虑月之暗面、智谱等国产模型;DeepSeek-V3.2更多被用于对价格敏感、或纯文本对话的场景。

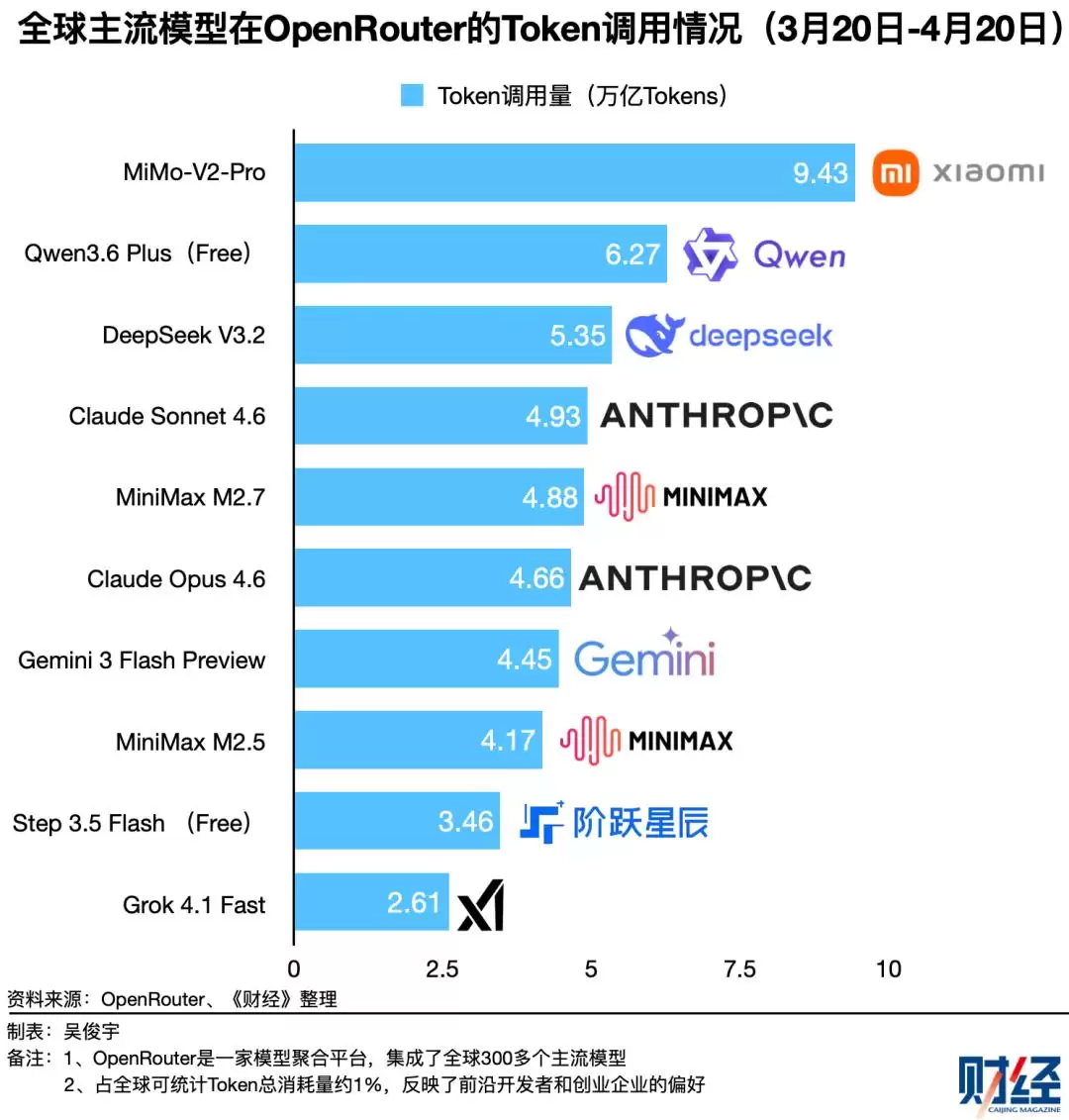
然而,一个有趣的反差是:尽管性能不再领先,DeepSeek的市场份额却依然稳固。在全球开发者平台OpenRouter上,DeepSeek-V3.2的月调用量长期位居全球前五,截至4月20日仍以5.35万亿Token的消耗量排名第三。其市场份额在近五个月内稳定在5%-10%之间。
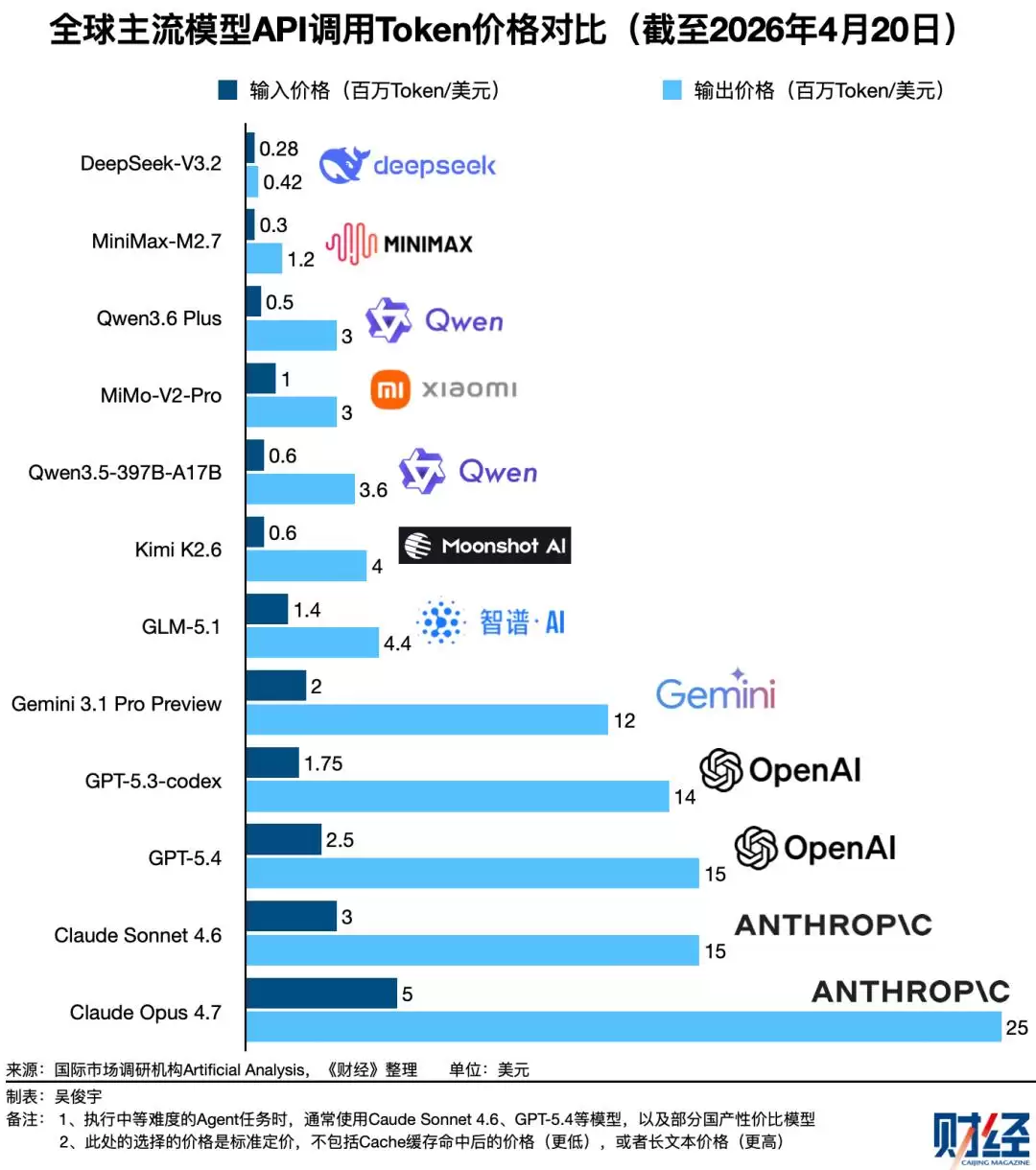
这份韧性从何而来?答案在于其极致的性价比和彻底的开源策略。DeepSeek-V3.2每百万Tokens的输入/输出价格仅为0.28/0.42美元,是许多国产模型的10%-30%,更是国际巨头旗舰模型的2%-5%。更重要的是,它采用最宽松的MIT开源协议,允许任何形式的商业使用与修改,像种子一样在全球开发者社区中生根发芽。OpenRouter数据显示,不仅V3.2,连2025年发布的V3和R1等旧版本至今仍被广泛使用,它们被集成在各类新兴的Agent工具和AI角色扮演应用中。
这种开源生命力甚至重塑了全球AI市场的区域格局。微软的报告指出,DeepSeek在北美、欧洲采用率不高,但在中国、俄罗斯及许多非洲国家份额快速增长,在俄罗斯的份额甚至高达43%。它正在成为发展中国家降低AI使用门槛、培育下一批十亿级用户的关键推动力。
商业化:克制与观望背后的现实
庞大的市场份额并未转化为清晰的商业收入。DeepSeek被外界视为中国大模型创业公司中,唯一一家放弃“既要又要”、始终专注于研究与开源路线的“异类”。当所有同行都在用巨额亏损换取增长时,DeepSeek的商业化步伐显得异常克制。
目前,其公开的商业化路径仅限于通过官网API调用收费,并未设置App订阅或Token套餐。然而,这条路径本身也充满挑战:开发者完全可以通过其他算力服务商,甚至自行在云端免费部署开源的DeepSeek模型。其开源策略如同一把双刃剑,虽然快速占领了市场,但也意味着主流云厂商部署其模型时,DeepSeek可能无法获得直接收入。
市场密切关注其融资动向,正是因为一旦启动融资,意味着这家公司可能不得不将投资者回报提上日程,大规模商业化或将随之而来。尽管有高管在内部会议中透露“已初步验证找到了一些路径”,但具体是什么,外界仍不得而知。
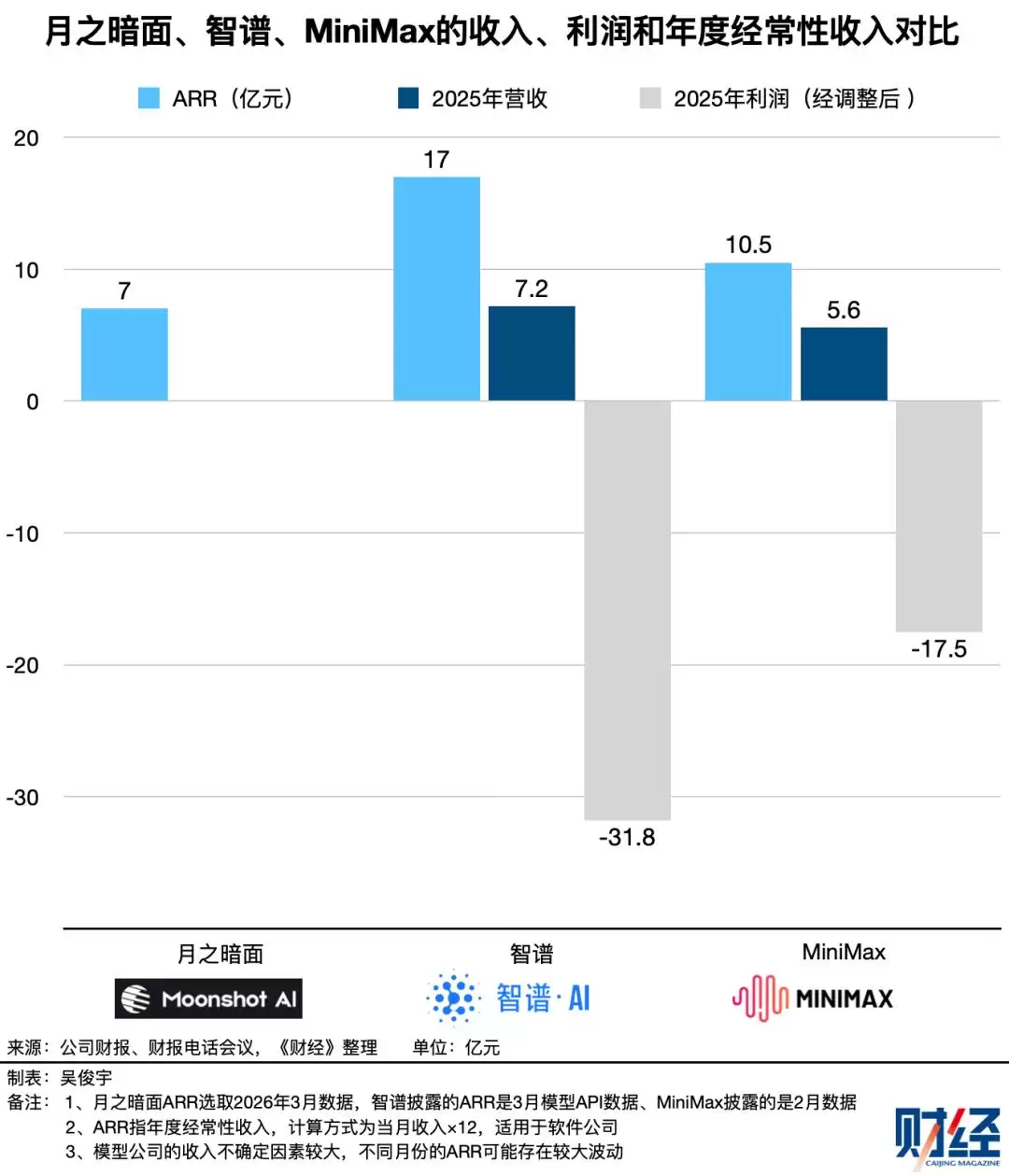
环顾四周,无论是美国的OpenAI、Anthropic,还是中国的月之暗面、智谱、MiniMax,都已全面转向以产品和收入驱动增长的阶段。这些公司的收入正在快速增长,证明商业化与性能提升并非不可兼得。当然,商业化不等于盈利,上述几家明星公司目前仍处于大规模亏损状态。这或许也是DeepSeek保持克制的理由之一——在找到真正的商业正循环之前,冒进未必是上策。
国产算力的“天堑”与期待
除了商业化,市场对DeepSeek的另一重期待,落在了国产AI芯片上。传闻中V4将适配华&为昇腾芯片,这引发了更深远的猜想:它能否基于国产芯片完成从零开始的训练?
对于模型推理而言,适配国产芯片已是行业常规操作。但训练则是另一回事。这是一个极其复杂的系统工程,涉及数万枚芯片组成的集群、数周不间断的训练,以及芯片、网络、软件、电力散热等环节的精密协同。在万卡规模下,任何故障都可能导致训练中断,造成巨大的时间和算力浪费。
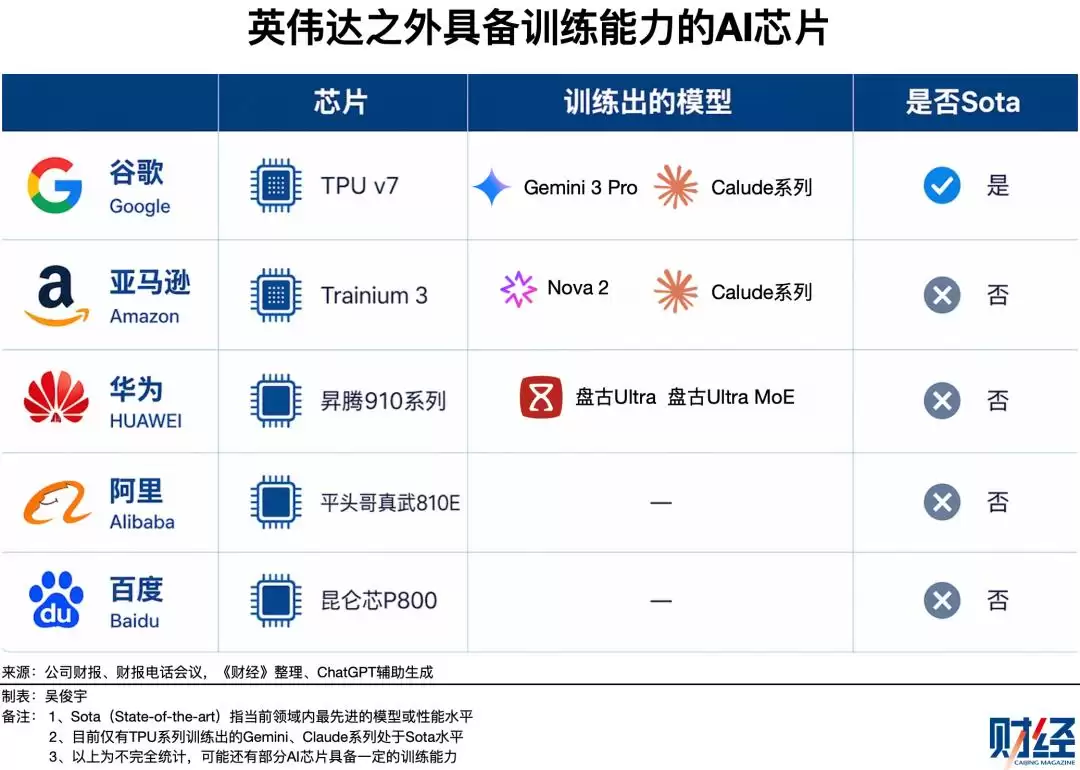
目前,中国主要模型公司的核心训练任务仍依赖于英伟达芯片。尽管谷歌用自研TPU、亚马逊用Trainium芯片成功训练出了顶尖模型,证明了非英伟达路径的可行性,但在国产芯片上,尚未有公开的、关于万亿参数规模且被大规模商用模型的完整成功案例。国产芯片在绝对性能、软件生态成熟度上仍落后主流产品两代以上,训练工程代价高昂。有企业尝试用某国产芯片复现英伟达芯片上的视觉模型,结果训练周期延长20%以上,综合成本翻倍。
正因如此,英伟达创始人黄仁勋才在近期的一次播客中直言,DeepSeek在华&为芯片上首发的那一天,对美国而言将是一个“可怕的后果”。他担心的是,一旦开源模型深度优化并绑定非美国技术栈,将威胁到美国AI生态的全球领导地位。
2025年初,中国市场的焦虑是“缺乏算力,模型能否追上”。到了2026年,这个问题的答案已经清晰——中国已不缺乏便宜好用的基础模型。新的焦虑变成了“能否用国产算力训练出顶尖模型,从而摆脱依赖”。
DeepSeek曾用2048张英伟达H800芯片和558万美元的成本训练出V3,这已被视为一次极限突破。如今,市场的期待情绪再次汇聚到它身上:它能否再次完成一次看似不可能的挑战,为国产AI芯片的模型训练蹚出一条可复制的工程路径?这已不完全是一家公司的技术选择,而是在特定时期,整个行业对一家特殊公司所寄托的特殊期许。




