过去几年,梁文锋几乎拒绝了所有互联网时代熟悉的剧本。
当别人忙着融资时,他选择拒绝;当行业争抢入口时,他选择开源;当对手卷参数规模时,他卷的是效率;当多数人把AI视为一门生意时,他谈论的始终是AGI(通用人工智能)。
这使得DeepSeek看起来更像一家“研究机构”,而非典型的创业公司。
然而,2026年春天,变化悄然发生。
GPT-5.5发布不到24小时,DeepSeek-V4预览版便悄然上线。发布后不到五天,价格接连三次下调。紧接着,DeepSeek的“识图模式”开始灰度测试,补上了多模态这块缺失已久的拼图。
与此同时,那个长期婉拒腾讯、阿里和顶级风投的梁文锋,第一次主动打开了融资的大门。
一边将价格打到“骨折”,一边却伸手拿钱;一边坦言算力吃紧,一边承诺未来还要降价。这位把AGI挂在嘴边的创始人,究竟是向商业现实“缴械投降”,还是在酝酿一场更大的风暴?
“反常识”的72小时
4月24日,GPT-5.5发布后不到一天,DeepSeek-V4预览版悄然上线。没有发布会,没有造势,一切符合这家公司一向的作风:事情做完了,放出来,你们自己看。
V4-Pro发布后,最先引发热议的不是其能力,而是价格。相比前代V3.2,V4-Pro的定价起初显得更高。
市场第一反应是:DeepSeek终于要走向“正常商业化”了。但很快,剧情出现反转。
不到一天,官网价格低调更新,直接打到2.5折。随后又一次更新:缓存命中价格永久降至发布价的十分之一。
团队甚至在社交媒体上直接打出了“AGI for Everyone”的标签,强调这是永久定价,而非短期促销。
更耐人寻味的,是官网价格页面里那行不起眼的小字:“受限于高端算力,目前Pro服务吞吐有限,预计下半年昇腾950超节点批量上市后,Pro价格会大幅下调。”
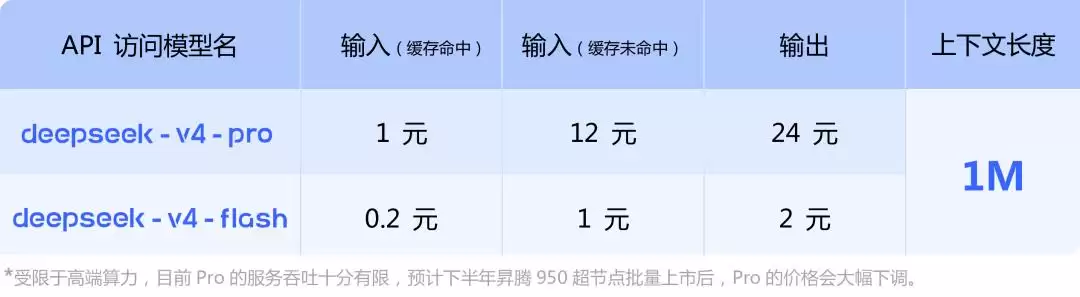
这意味着DeepSeek公开承诺未来还会继续降价,并且这次价格下调绑定的,不再仅仅是自身的技术优化,还有中国国产高端算力的量产节奏。
几乎在同一时间,DeepSeek启动了成立以来的首次外部融资,目标估值从100亿美元迅速抬升至200亿美元乃至更高,腾讯、阿里相继被传洽谈入局。
一边降价,一边融资,看似矛盾的操作背后,回看DeepSeek的发展轨迹,会发现它的野心从来不只是“做一个模型”。
过去两年,全球大模型行业默认的逻辑是模型越强,成本越高,能力越强,价格越贵。无论是OpenAI还是Anthropic,都建立在这套逻辑之上。
但DeepSeek-V4要做的,不是“出售更昂贵的智能”,而是不断降低“智能”的边际成本,试图实现AGI的平权。
这种对“边际成本”的极致追求,其实从DeepSeek的前身——幻方量化时期就开始了。早在2021年,当大多数科技公司还在讨论AI概念时,幻方就已经囤积了上万张A100,自建了“萤火”算力集群。
在高度竞争的市场里,成本结构本身就是最深的护城河。这是梁文锋在幻方时期就想明白的道理,如今被完整地继承到了DeepSeek。
数据对比很直观:DeepSeek V4-Pro处理百万token上下文,成本约5.22美元,缓存命中后可降至3.6美元左右。而同等输入输出量下,GPT-5.5的API成本约35美元,Claude Opus 4.7约30美元。
至于更轻量的V4-Flash,成本甚至不到竞争对手的2%。这已经不再是简单的价格差异,而是形成了“量级差”。
“超低价”的背后,是模型架构、推理系统与算力调度共同优化的结果。V4-Pro支持100万token上下文,在部分长文本场景下,单token推理所需算力相比前代显著下降,KV Cache占用也大幅减少。
过去行业处理长上下文,很大程度上依赖持续堆叠显存和带宽;而DeepSeek尝试通过架构优化,来减少一部分无效计算与资源浪费。
当然,效率上的突破并不等同于全面超越。
根据DeepSeek内部的真实评测,V4目前已成为公司员工日常使用的Agentic Coding模型,使用体验优于Sonnet 4.5,交付质量接近Opus 4.6的非思考模式,但与Opus 4.6的思考模式仍存在一定差距。
开源和低价建立了广泛的影响力,但“一分钱一分货”的道理,在顶级闭源模型身上依然成立。
某种程度上,V4真正改变的,或许不是模型能力的绝对高度,而是行业对于“智能应该值多少钱”的认知。
极客肖恩·多纳霍在社交媒体上分享,自己将部分编程工具切换到DeepSeek之后,月账单下降了90%以上,效果却并未出现明显下滑。
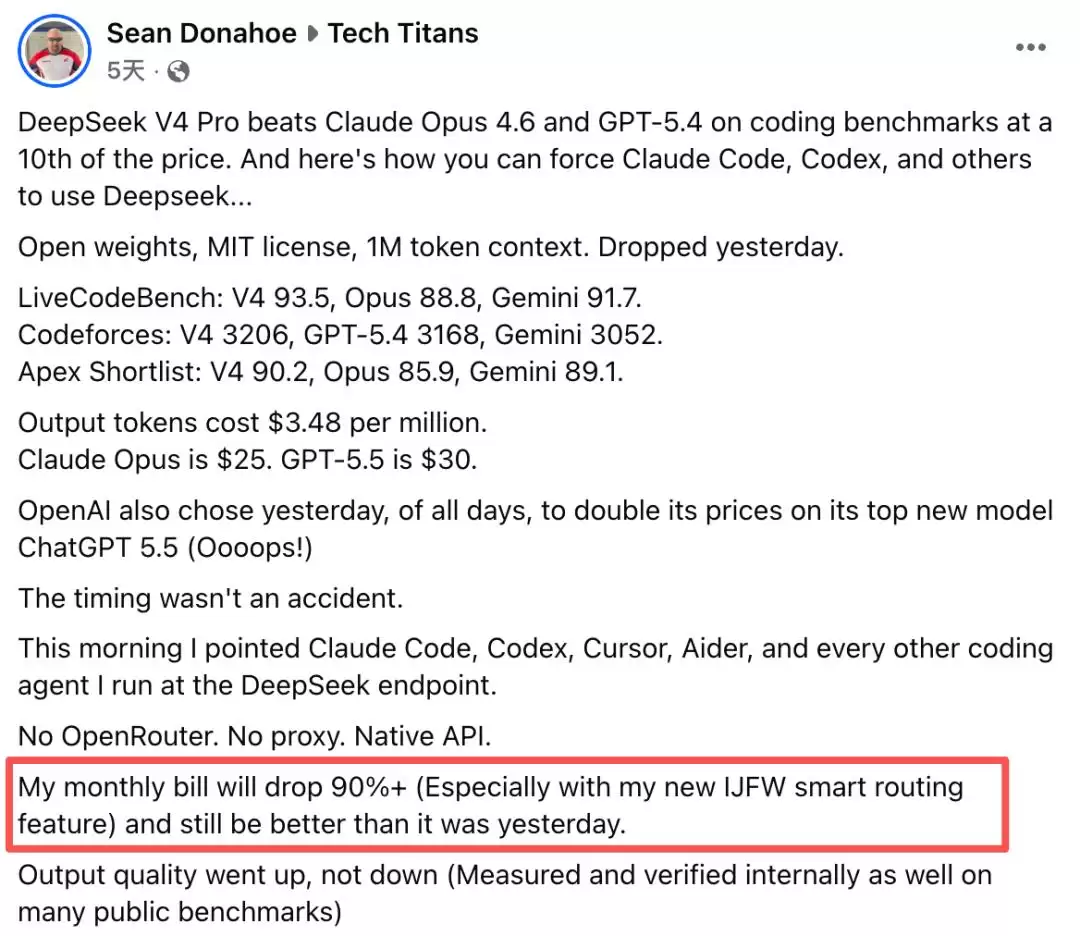
科技博主Simon Willison每次在DeepSeek发布新版本时,都会用同一句提示词生成一张“鹈鹕骑自行车”的SVG图片来测试。这次测试后,他称DeepSeek-V4-Pro是“大型前沿模型中最便宜的一款”。

这几位开发者或许只是个案,但他们背后折射出的趋势值得关注:当价格差拉大到“量级”级别,开发者重新分配算力预算的动机就会急剧增强。
而当越来越多的应用、智能体和开发工具开始基于同一种模型生态构建时,真正形成护城河的,可能就不只是模型能力本身了,还包括开发者的使用习惯、调用路径,以及整个生态的成本惯性。
DeepSeek的目标很明确:用极致的性价比,成为那个被开发者“持续依赖”的选项。
DeepSeek 的“二度奇袭”
时间拉回到2025年1月,DeepSeek R1的发布曾引发全球震动。
其应用迅速登顶苹果中国和美国地区App Store免费榜榜首,英伟达单日市值蒸发约6000亿美元,美国风投家马克·安德森称之为AI领域的“斯普特尼克时刻”。
一个来自杭州的量化团队,用560万美元的训练成本,做出了对标OpenAI顶级模型的效果,并且选择了开源。那时,世界对梁文锋的理解,是“用更少的钱做出更好的模型”。
很多人后来把R1的成功理解为“受限条件下的逆袭”,但这并不完全准确。早在行业真正意识到大模型价值之前,幻方就已经开始大规模采购算力、建设集群。后来外界看到的“低成本奇迹”,更像是一次长期技术积累后的集中爆发。
梁文锋真正厉害的地方在于,他比大多数人更早意识到未来AI竞争的核心,不只是模型能力的比拼,更是算力效率的战争。
然而,当DeepSeek从一匹技术黑马转变为行业的核心玩家时,新的挑战也开始浮现。
过去的DeepSeek,很像一个隐秘的研究组织。背后有幻方量化输血,梁文锋不缺钱,研究员可以心无旁骛地埋头做模型。其官方账号的签名是“用好奇心揭开通用人工智能的奥秘,用长远的眼光回答根本问题”,学术气息浓厚。
但AI行业不会长期尊重“隐士”,尤其当你手里真的握有“真经”的时候。
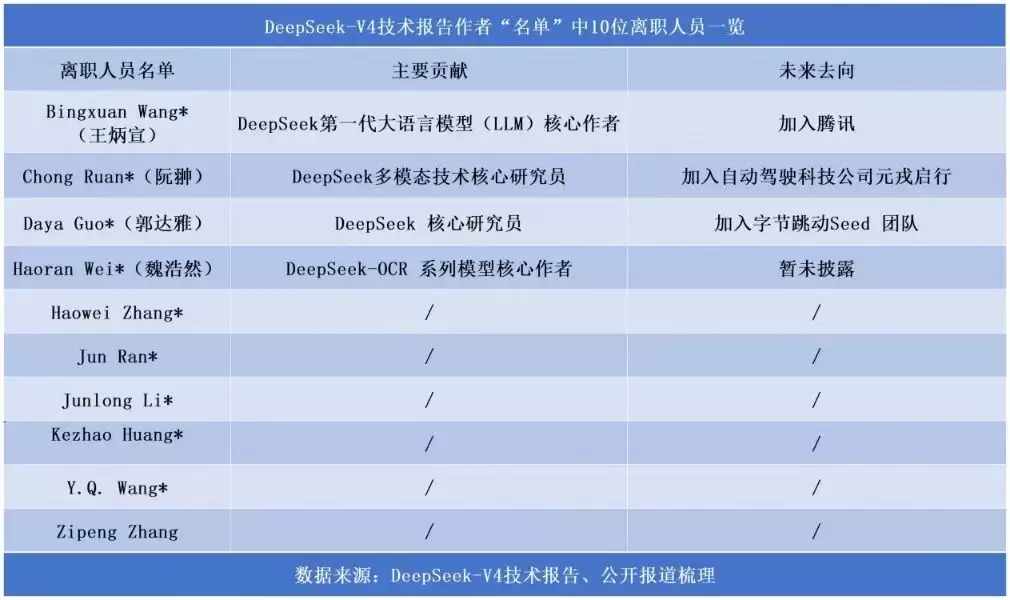
从2025年底到2026年,多位DeepSeek核心成员相继离开。
V3架构关键开发者罗福莉去了小米,第一代大语言模型核心作者王炳宣加入腾讯,R1核心研究员郭达雅被字节跳动以传闻中“近亿元的总包”招致麾下,多模态方向核心研究员阮翀则转投元戎启行。
过去,大模型公司的目标相对统一:训练更强的基础模型。但到了2026年,行业开始迅速分化,智能体、多模态、端侧AI、机器人、自动驾驶,陆续成为新的战场。
这时候,一位研究员如果想深入研究智能体,去字节会面对真实的月活场景;想让AI理解物理世界,去自动驾驶公司显然更有吸引力。
DeepSeek太专注于把模型本身做到极致。这种组织文化能够吸引最纯粹的研究者,却很难长期承载所有方向。它最强的地方,在某种程度上也成了它最大的桎梏。
主流AI公司争抢的是有经验的工程师,而梁文锋却更青睐顶尖高校的年轻博士生。在他看来,这些人“渴望证明自己”,“可以完全不带功利地投入去做一件事”。
初期,DeepSeek的确可以用技术理想主义吸引天才,但很难长期用理想主义来支付高昂的机会成本,尤其在同行已经开始形成明确市场估值的时候。
近两年,OpenAI、Anthropic不断刷新融资数字,投后估值高达8400亿、3800亿美元。国内的智谱、MiniMax相继挂牌港交所,市值一度突破4000亿和3800亿港元。
大厂提供的是有明确行权价、有IPO预期、有内部回购机制的期权。而不进行外部融资的DeepSeek,则缺乏一个市场化的“度量衡”。在竞争白热化的AI人才市场里,没有明确估值锚点的期权,无异于一张难以兑现的期票。
梁文锋或许正是意识到了这一点,才选择了开放融资。
但这依然是一个极具“梁式色彩”的融资方案。此次融资目标募集金额不低于3亿美元,计划以不低于200亿美元的估值进行。与此同时,工商信息显示,梁文锋在增资后直接持股占比由1%提升至34%,其作为实际控制人的最终受益股份仍为84.29%,表决权比例仍为100%。
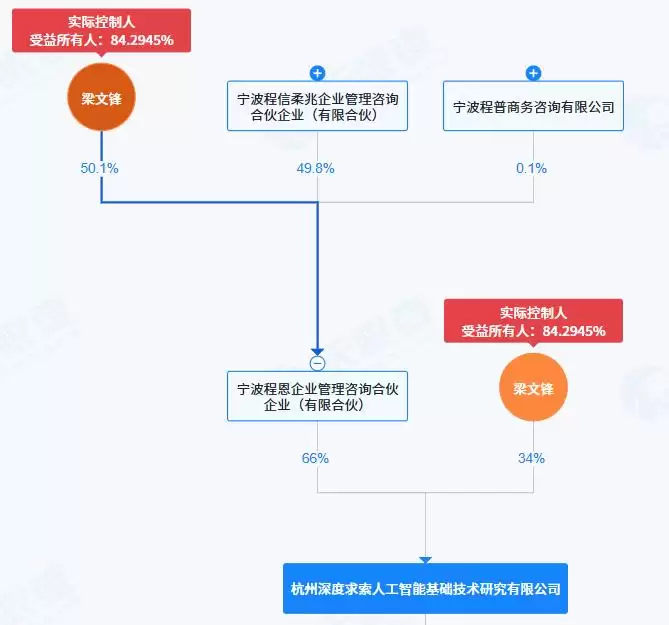
他用大约3%的股权,换来了市场对这家公司的价值认证。而董事会的控制权,一票未让。
对比同行,这个数字显得更加意味深长。OpenAI在2026年完成的最新一轮融资,募集1220亿美元,投后估值8520亿美元;Anthropic在2026年2月完成300亿美元G轮融资,投后估值3800亿美元。
3亿美元,放在今天的AI赛道里,甚至比不上同行一轮融资的零头。
梁文锋选择这个体量的融资,目的很明确:为员工手中的期权建立起相对清晰的估值锚点和兑现预期,稳住核心人才,同时确保公司不被短期的增长压力所裹挟。
允许梁文锋再“伟大一次”
R1证明了中国的AI团队有能力做出世界级模型。而在V4之后,梁文锋试图证明的是,中国AI可以建立起自己的“底座标准”,哪怕这条路,注定艰难。
一个值得关注的细节是,V4发布后,华&为昇腾生态的官方账号,专门为DeepSeek-V4做了一场直播。
芯片厂商亲自下场为一款模型站台,这并不常见。它释放的信号超出了产品本身:DeepSeek第一次公开地,将自己的模型发展路线与国产算力的量产节奏深度绑定。
过去几年,中国AI行业有个默认的共识:模型可以开源,算法可以追赶,但英伟达的生态护城河最难撼动。CUDA是英伟达用二十年时间攒下的工具链、算子库、开发框架和开发者习惯,全球AI几乎都默认运行在这套底座之上。
要脱离它,绝非“换块显卡”那么简单。尤其是在训练万亿级参数模型时,难度会被指数级放大。参数规模越大,对显存带宽、通信效率、集群稳定性的要求就越高。
模型团队不仅需要针对国产芯片重写和优化核心算子,甚至还需要自研确定性算子,以保证长时间、大规模训练过程中的精确可复现。
更现实的问题是,在万卡级别的集群里,硬件故障不是意外,而是必然事件。因此,训练框架必须同时具备完整的故障检测、容错与恢复能力。如果效率跑不上去,所谓的低成本就只是空谈。
V4的发布延期超过十五个月,迁移到新算力平台的代价是主要原因之一。
目前,V4的细粒度专家并行方案已经同时在英伟达GPU和华&为昇腾NPU两个平台上完成验证,在通用推理场景中实现了1.5到1.96倍的加速。
推理层面虽然跑通了,但开源代码主体仍基于CUDA,底层工具链尚未完全转移。原因在于昇腾950超节点尚未批量上市,现有产能还撑不起V4-Pro的大规模服务。
不过,DeepSeek已经把下一轮降价,公开写进了国产算力的量产时间表里。昇腾950PR单卡算力达到英伟达H20的2.87倍,是目前国内唯一支持FP4低精度推理的产品,HBM容量高达112GB。规格是真实的,现在只等工业化落地。
梁文锋当年从幻方量化的GPU集群起家,把算力当作研究的弹药。如今,他让中国模型和中国芯片的命运,在商业上深度捆绑,并在所有人面前做出了承诺。这是在芯片封锁的现实下,做出的一个极为务实的选择。
但这条路有个至关重要的前提:模型能力必须始终足够硬。V4把100万上下文做成标配、对智能体能力做专项优化、推出三档推理强度,这些改进不是给评测榜单准备的,而是为真实的企业工作流准备的。只有先在真实的生产场景里证明自己不可替代,DeepSeek的“底座”叙事才能真正成立。
未来,梁文锋和DeepSeek要走的路还很长。国产算力的工业化时间表能否如期兑现?模型能力能否在闭源顶级模型高速迭代的压力下保持竞争力?开发者生态能否形成足够的黏性?……这些问题,就像棋盘上尚未闭合的“气眼”,每一个都关乎生死,而目前,都还没有确切的答案。
在DeepSeek爆火后,被问及“商业公司做无限投入的研究性探索是否疯狂”时,梁文锋曾说过一句话:“我们终其一生所渴望的,就是找到自己,然后成为自己。”
这句话在R1发布后的语境里读,像是一位创始人的理想宣言。如今再读,分量似乎更重了些。
AI竞争的上半场,他用技术效率、定价碘伏和算力豪赌,赢得了继续坐在牌桌上的资格,成就了DeepSeek的第一次“伟大”。
下半场,我们或许可以允许梁文锋再“伟大一次”。这不是因为他已经攻下了某个技术的山头,而是因为他正在为一场注定漫长的远征,搭建那个属于自己的底座。
不诱于誉,不恐于诽,率道而行,端然正己。
这是荀子的精神,如今也成了DeepSeek的信条。




