2025年5月9日,百度正式推出文心大模型5.1版本。此次升级并非常规迭代,而是在文心5.0坚实知识底座之上,实现了效率与性能的全面跃升。其最核心的突破在于极致的成本优化——新模型将总参数规模压缩至约三分之一,激活参数降至约二分之一,而预训练计算成本更是仅为行业同级别模型的约6%。这标志着,文心5.1以更低的资源消耗,实现了更优的性能表现,在同等规模模型中确立了基础效果的领先地位。

目前,普通用户可直接访问文心一言官方网站,与全新的文心5.1模型进行对话,亲测其最新功能。对于开发者,通过百度智能云千帆大模型平台,仅需将model_name参数修改为ernie-5.1,即可便捷调用相应API服务,快速完成集成与部署。
此外,自发布之日起,文心大模型5.1将逐步接入超过十个主流创意生产智能体平台。这包括全球知名的AI角色互动平台ISEKAI ZERO、创意智能体平台Mulan AI、AI原生创意画布谛听幻流,以及AI短剧生成平台Storymaster等。此举将为广大数字内容创作者和终端用户,提供更强大、更多元的AI创作工具选择。
登顶多个榜单
模型性能,数据为证。在5月9日当天,文心大模型5.1于权威的Arena Search开放评测排行榜上,以1223分的优异成绩位列全球第四,并在所有中国大模型中排名第一。这一排名充分证明了其在开放域问答与综合能力上的强大竞争力。
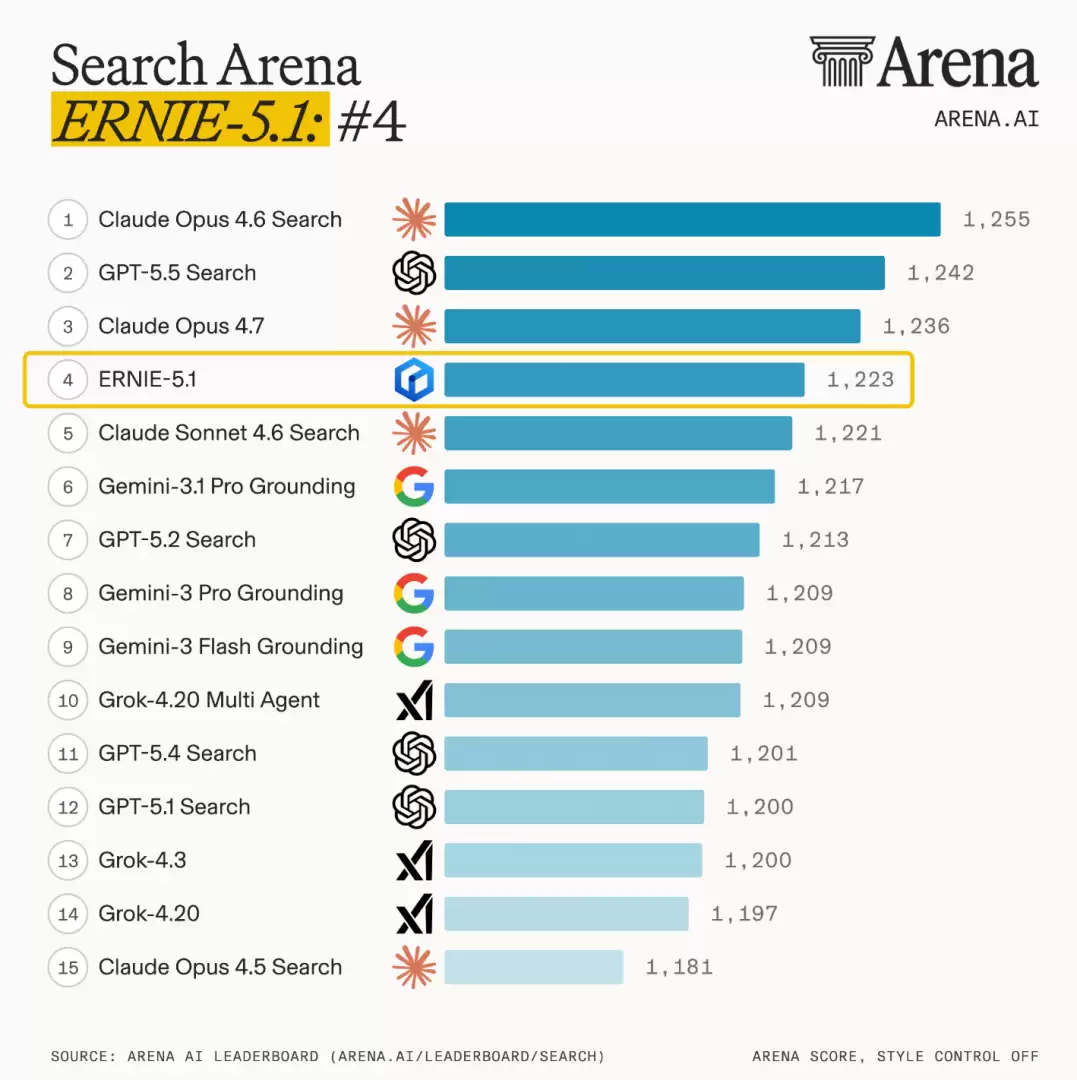
不仅如此,在多项权威行业基准测试中,文心5.1均展现出强劲实力,尤其在智能体任务执行、知识问答、复杂逻辑推理与深度信息检索等核心能力维度上,表现卓越。
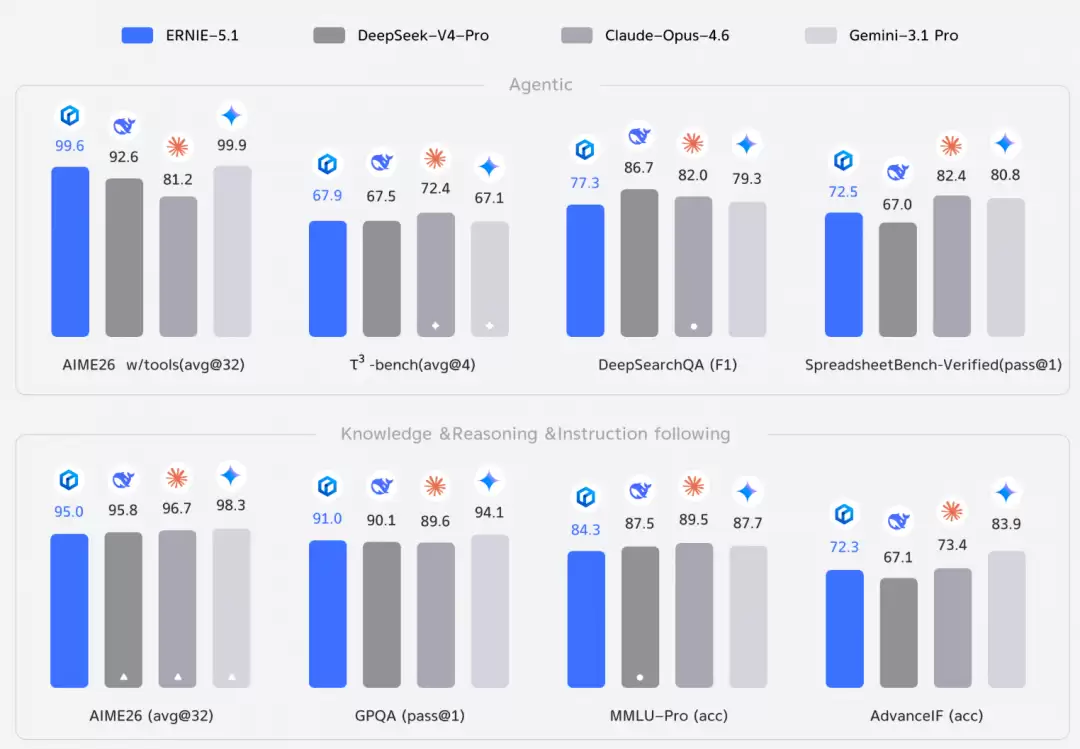
具体而言,在专门评估智能体能力的τ³-bench和SpreadsheetBench-Verified任务中,文心5.1的表现已超越DeepSeek-V4-Pro,其智能体水平正逼近全球顶尖的闭源模型。其在Search Arena排行榜上的优异表现,也进一步印证了其强大的搜索与执行能力。
在考察深度专业知识(GPQA)与综合知识理解(MMLU-Pro)的评估中,文心5.1的性能同样接近头部闭源模型。根据内部评测,其创意文本生成能力已可与Gemini 3.1 Pro相媲美。
在数学推理方面,文心5.1同样达到顶尖水准。在极具挑战性的数学竞赛基准AIME26(使用工具)测试中,其得分高达99.6,仅次于Gemini 3.1 Pro,稳居全球第二。
预训练计算成本仅为同类模型的6%
那么,文心大模型5.1是如何实现能力提升与成本锐减并行的呢?其奥秘在于独特的模型衍生路径与创新的训练框架设计。
文心5.1直接衍生自文心大模型5.0。研发团队并未进行从零开始的训练,而是从文心5.0所构建的“多维弹性子模型矩阵”中,精准搜索并提取出了最优的子网络架构。这一方法完整继承了5.0版本所编码的庞大知识体系与核心能力,同时避免了大量重复计算,从而大幅降低了预训练阶段的资源消耗。
这背后依赖于一项名为“一次训练,处处部署”(Once-For-All)的突破性弹性训练框架。与传统为不同规模模型分别预训练的模式不同,该框架创新性地在单次预训练过程中,通过动态采样机制,同步优化海量具有不同深度、专家容量和路由稀疏度的子模型,最终形成一个覆盖广泛参数规模与计算预算的“可部署子模型资源库”。
在此框架下,模型主要沿三个维度实现了灵活伸缩:
弹性深度:训练时随机激活不同数量的Transformer层,使得不同深度的子模型能够共享权重,从而自适应地学习深层语义与浅层特征之间的最佳平衡。
弹性宽度/专家容量:通过动态调整参与计算的专家数量,灵活控制MoE(混合专家)层中的有效专家容量。模型学习在完整专家池与精简专家池配置下均能高效工作,极大提升了专家资源的利用率。
弹性稀疏度:采用可变的Top-k路由机制,灵活控制每次前向传播所激活的专家数量。激活专家少,则推理成本低、响应速度快;激活专家多,则模型能力全面、表现更强。由此实现了推理效率与模型性能的智能权衡。
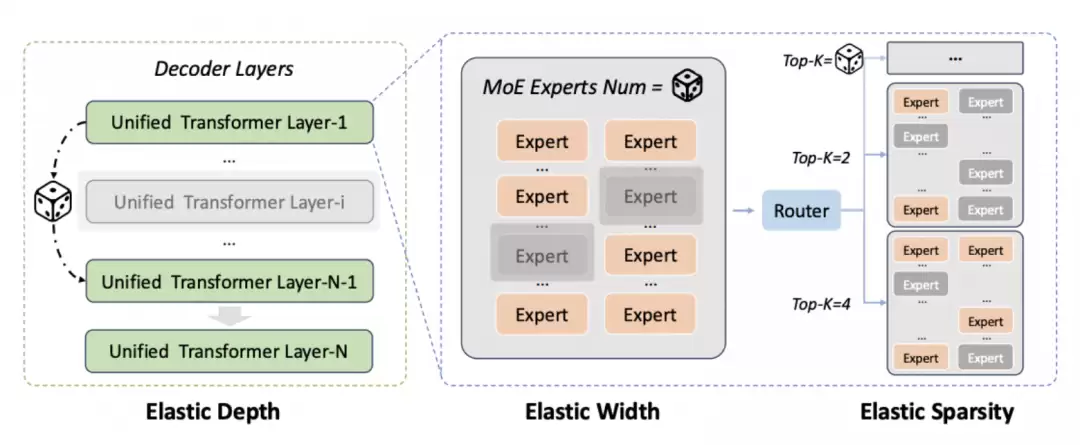
正是基于上述一系列底层技术的重大突破,文心大模型5.1得以将总参数量压缩至5.0版本的三分之一左右,激活参数量压缩至二分之一左右,并将预训练计算成本成功控制在同规模同类模型的6%这一行业领先水平。相较于文心5.0,其推理成本显著降低;而在同规模模型的横向对比中,它依然保持着显著的性能优势。




