AI PC的算力迷思:CPU、GPU、NPU,究竟谁才是主角?
现在但凡聊到消费电子,“AI PC”绝对是最热的风口。对于追求便捷的普通用户来说,它可能意味着一个更聪明、更能干的电脑助手。但行业内的人心里往往揣着一个疑问:从技术上讲,AI计算单元早就出现在个人电脑里了,为何这个概念直到今天才被炒得如此火热?这背后的逻辑,其实值得细品。
AI PC到底有多早?其实7年前就已经出现了
如果抛开那些顶尖的超算,仅看消费级市场,“AI PC”的起点究竟在何时?
从处理器这条线追溯,答案可以回到2019年。当时,英特尔在其第十代酷睿-X系列处理器(例如i9-10980XE)中,首次引入了专为加速16位运算设计的“DL Boost”指令集。随后,这项技术便下放到了更主流的十代酷睿移动版以及十一代酷睿全线产品中。它的意义在于,让这些CPU在处理深度学习和AI应用时,理论效能比之前提升了一倍。
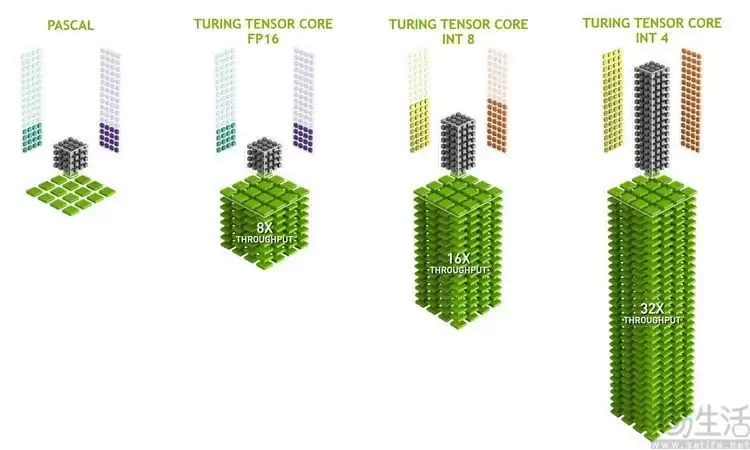
而如果从显卡的角度看,这个时间点还要更早。2017年,消费级市场迎来了首款内置Tensor Core的“AI显卡”——NVIDIA TITAN V。公开资料显示,其集成的640颗初代Tensor Core,在FP16精度下能提供高达119TFlops的AI算力。
有意思的是,如果你对数据敏感,可能会立刻发现:这款七年前的老将,其标称的AI算力甚至比当下许多号称“AI PC”的设备所宣传的水平,还要高出十倍不止。
NPU的AI性能不算高,可为什么还要用它们呢
那么问题来了,既然老显卡的算力都这么猛,为何如今还要大费周章地推广算力看似不占优的NPU(神经网络处理单元)呢?根据实际的产品表现和用例分析,原因主要集中在三个方面。
首要一点是能效。没错,现代的CPU和GPU都具备AI加速能力,特别是GPU的峰值算力确实惊人。但CPU处理AI任务的效率相对有限,而GPU一旦全力运行AI计算,其功耗对于笔记本电脑这类移动设备而言,往往是难以承受之重。因此,比CPU快、比GPU省电的NPU,在能效上的优势就凸显出来了。

或许有人会想,如果用性能更强的设备在更短时间内算完任务,不也能省电吗?道理是这个道理,但关键在于,当前“AI PC”面临的任务是多样化的。并非所有AI任务都像视频超分或文生图那样需要爆发式算力。像AI语音助手、系统性能智能调度这类功能,需要的是常驻后台、随时以最低延迟响应。这种情况下,让CPU或GPU长期处于高功耗状态来“待命”,显然是不现实的。
AMD基于GPU的端侧AI大模型聊天功能,就非常吃显卡性能
再从实际使用场景看,目前绝大多数主流PC应用和游戏,其核心逻辑并非基于AI。如果一直让CPU或GPU分心去处理AI任务,势必会挤占它们处理本职工作的资源,导致整体性能下降。对除了专业AI开发者之外的大部分用户来说,这显然不是他们愿意看到的结果。
“算力融合”才是未来,但要做好它并不容易
当然,即便NPU有高能效、低功耗、可常时运行且不干扰主系统性能这些优点,很多人还是会自然而然地想到那个更理想的方案:为什么不能让CPU、GPU、NPU协同作战,根据任务需求灵活分配,兼顾高性能与高能效呢?

从理论上讲,这当然可以实现。例如,高通的骁龙X Elite平台就宣称实现了CPU、GPU、NPU均能参与AI运算,并能根据任务负载自动分配的“异构协同”设计。
但恰恰是从这个案例里,我们能看出其他主流“AI PC”方案实现协同运算的难点所在。说白了,核心障碍在于各家硬件巨头“各自为战”的产业格局。
最新的NVIDIA驱动界面会提供一系列基于RTX显卡的AI加速功能
以GPU领域为例,无论是NVIDIA的RTX系列、AMD的RX 7000系列,还是Intel的ARC独显,内部都设计了独立的AI计算单元。但NVIDIA并不生产消费级x86 CPU,因此我们看到其发展路线更侧重于强化显卡本身的AI能力,不断推出基于RTX显卡的AI视频增强、色彩修复、音频降噪乃至聊天机器人功能,颇有几分“AI PC,显卡算力足矣”的意味。
相比之下,英特尔和AMD的处境则有些尴尬。例如,英特尔的ARC独显虽具备XMX矩阵计算单元,但其集成在酷睿处理器内的核显版本却取消了这一设计。这就导致目前的Meteor Lake架构处理器,实际上主要依赖内置NPU进行AI计算。而且,即便搭配ARC独显使用,目前也无法实现核显与独显AI算力的叠加。

AMD的CPU和GPU现在都有AI单元,但架构和软件都不通用
再看AMD,其锐龙处理器中的NPU采用了来自企业级产品的成熟XDNA架构,理论上软件生态迁移更有优势。但蹊跷的是,其在RDNA 3独显架构中似乎采用了另一套AI单元设计,以至于至今仍未实现基于专用AI单元的游戏画面超分辨率技术。在不少演示中,其显卡的AI功能仍依赖GPU通用流处理器进行浮点运算,这意味着更高的功耗,并且很难实现“边打游戏边进行高强度AI处理”。
芯片厂商不团结,下游品牌就只能想方设法“自救”
分析了这么多,难道这些问题就无解了吗?倒也未必。对于英特尔和AMD而言,完全有可能在未来的产品架构更新中,通过重新设计来统一和协同不同单元的AI算力。而对于NVIDIA,虽然其暂无x86 CPU产品线,但也不能排除其未来借助ARM架构CPU,切入Windows on ARM生态的可能性。
当然,以上这些多少都把希望寄托于未来。那么,对于当下正要购机的消费者,甚至是那些早已在使用具备AI计算单元硬件的用户来说,就真的只能干等吗?
情况也没那么悲观。一方面,作为操作系统的掌控者,微软显然不愿看到“AI PC”标准分裂的局面。因此,它一直在驱动和API层面努力,试图统一调度不同架构的AI算力。一个典型的例子是DirectML API,无论算力来自显卡的通用流处理器、专用NPU,还是显卡内的AI核心,在Windows系统中都可被其统一调度,从而实现一定程度的算力融合。
另一方面,PC整机厂商也在积极自救。一些头部品牌通过自研的AI中间件或底层框架,尝试在自家产品内协同调度CPU、GPU、NPU的算力,或者将显卡的AI加速API更深地集成到系统底层以提升效率。这些努力当然有价值,但它们往往受限于特定品牌甚至特定机型,其效果虽可能很出色,却难以对整个行业产生普适性的推动作用。