SQL Server CSV数据导入实战指南:从基础到高级处理
在数据分析、报表生成或系统迁移过程中,将CSV格式的数据文件导入SQL Server数据库是一项高频且关键的操作。许多开发者可能会考虑编写外部程序来实现,但实际上,SQL Server自身就提供了高效、直接的批量导入功能,无需依赖额外代码,能显著提升数据处理的效率与便捷性。
核心方法:使用BULK INSERT命令快速导入
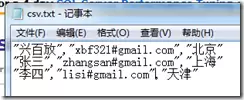
我们从一个标准场景入手。假设您有一个名为csv.txt的CSV文件,存放于D盘根目录,其内容结构清晰:
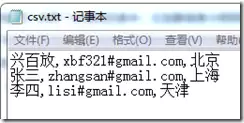
接下来,利用SQL Server内置的BULK INSERT命令可以轻松完成数据加载。首先,需要在目标数据库中创建一张与CSV文件列结构相匹配的数据表:
CREATE TABLE CSVTable(
Name NVARCHAR(MAX),
Email NVARCHAR(MAX),
Area NVARCHAR(MAX)
)
表结构准备就绪后,执行以下导入命令:
BULK INSERT CSVTable
FROM 'D:\csv.txt'
WITH(
FIELDTERMINATOR = ',', -- 指定字段分隔符为逗号
ROWTERMINATOR = '\n' -- 指定行终止符为换行符
)
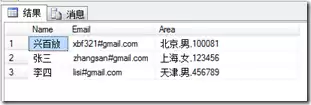
SELECT * FROM CSVTable -- 验证导入结果
执行后,数据将准确无误地插入表中:
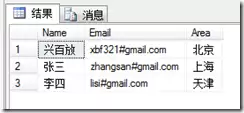
整个过程简洁高效,避免了编写和调试外部脚本的繁琐,是进行SQL Server数据导入的首选方案。
高级场景:应对复杂与非标准CSV文件的策略
然而,实际业务中的CSV文件往往格式不一,直接导入可能引发错误。掌握以下常见问题的处理方法,能让您的数据导入工作更加稳健。
场景一:字段值引号格式不一致
部分CSV文件中,某些字段值被双引号包裹,而另一些则没有,造成格式混杂:
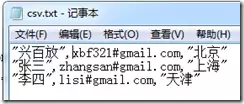
若直接使用基础命令导入,双引号会被视为数据内容的一部分,导致结果不准确:
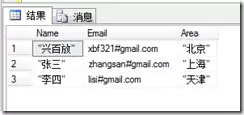
推荐采用“两阶段处理法”:首先将原始数据完整导入到一个临时表,随后通过INSERT...SELECT语句,结合REPLACE函数在插入目标表时清除多余引号,从而保证数据的纯净性。
场景二:所有字段值均被引号包围
此类文件更为规范,每个字段值都被双引号严格封装。
处理的关键在于正确配置BULK INSERT的格式化选项。在导入到临时表时,需在WITH子句中明确指定FIELDTERMINATOR与QUOTED_IDENTIFIER等参数,指导SQL Server正确解析并剥离字段周围的引号。

请注意上图中高亮的参数配置部分,这是实现精准导入的核心。
场景三:CSV文件列数多于目标表
当CSV文件包含的字段数量超过目标表定义时(例如文件有4列,表只有3列),直接导入会导致数据错位与混乱。
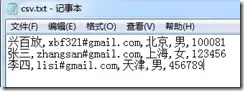
强行导入的结果是,超出部分的列值会被合并到最后一列中:
解决方案是采用“全字段接收,选择性插入”的策略。创建一个包含CSV所有列的临时表,将数据完整导入临时表。之后,通过INSERT INTO 目标表 SELECT 所需列 FROM 临时表这样的语句,仅将需要的列数据迁移至最终表,多余列在查询阶段即被自动过滤。
总结而言,BULK INSERT是SQL Server中功能强大的批量数据加载工具。面对格式各异的CSV文件,理解其工作机制,并灵活运用临时表与数据清洗SQL语句,能够有效解决绝大多数导入难题,实现高效、准确的数据入库。




