概述
理解MongoDB查询优化的核心,关键在于掌握“索引边界”这一概念。你可以将其视为查询引擎为索引字段设定的一个“数值筛选区间”。这个区间定义得越精准,数据库需要扫描的文档数量就越少,从而显著提升查询速度并降低系统资源消耗。
利用多键索引的边界交集优化查询
如何让这个“筛选区间”更加精准呢?一个非常有效的策略是计算“边界交集”。这类似于数学中的区间交集运算:例如,区间[3, +∞)与区间(-∞, 6]的交集就是[3, 6]。MongoDB在处理涉及数组的查询时,会智能地应用这一逻辑来缩小扫描范围。
具体到针对数组字段建立的多键索引,当查询中使用 $elemMatch 操作符来指定多个条件时,MongoDB会主动合并这些条件的边界,从而生成一个更精确的查询范围。我们通过一个实例来深入理解。
首先,创建一个名为students的集合并插入示例数据:
db.students.insertMany([
{_id: 1, name: 'Shawn', grades: [70,85]},
{_id: 2, name: 'Elena', grades: [92, 84]}
])
接着,为grades这个数组字段创建一个升序的多键索引:
db.students.createIndex({grades: 1})
现在,执行一个核心查询:查找grades数组中存在任意一个元素,其值在90到99之间(包含90和99)的文档。
db.students.find( { grades: { $elemMatch: { $gte: 90, $lte:99 } } } )
这个查询的精妙之处在于$elemMatch。它强制要求数组中的同一个元素必须同时满足“大于等于90”和“小于等于99”这两个条件。分析其执行策略:条件“$gte: 90”对应的索引边界是[90, +∞),条件“$lte: 99”对应的边界是(-∞, 99]。由于使用了$elemMatch,MongoDB会先计算这两个边界的交集,得到精确的[90, 99]区间,然后直接利用索引在该区间内进行高效查找。
如果省略$elemMatch,查询语义将发生根本变化:
db.students.find( { grades: { $gte: 90, $lte:99 } } )
此时,查询的含义变为:查找满足“数组中至少有一个元素≥90”并且“数组中至少有一个元素≤99”的文档。这两个条件可以由数组中两个不同的元素分别满足。因此,MongoDB无法预先计算出一个统一的边界交集,它可能只能选择其中一个边界(如[90, +∞))进行索引扫描,然后再在内存中过滤,这无法保证最终结果中的某个元素一定落在[90, 99]区间内。
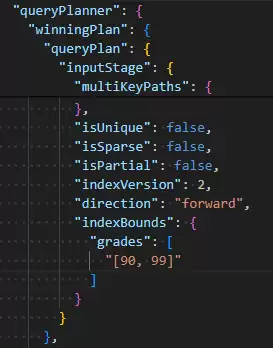
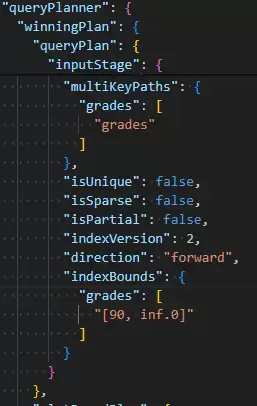
这两种写法的性能差异,可以通过执行计划(explain)清晰地展现出来。运行以下命令进行对比:
db.students.find( { grades: { $elemMatch: { $gte: 90, $lte:99 } } } ).explain()
db.students.find( { grades: { $gte: 90, $lte:99 } } ).explain()
下图对比直观地说明了问题。左侧是使用$elemMatch的执行计划,显示了精确的索引边界;右侧则未使用,查询范围更为宽泛,可能导致性能下降。
复合多键索引的边界混合机制
复合多键索引的强大之处在于,它能够将多个字段的索引边界“混合”起来,形成一个多维的查询过滤框,从而在针对多个字段进行查询时实现极致的效率。假设有一个关于温度和湿度的复合索引{temperature: 1, humidity: 1},分别给定边界[80, +∞)和(-∞, 20],那么混合后的复合边界就是{ temperature: [80, +∞), humidity: (-∞, 20] }。这样,MongoDB可以一次性利用两个维度的约束来精准定位数据。
反之,如果边界无法成功混合,查询引擎可能只能利用索引中的第一个字段(前导字段)进行范围扫描,后续字段的过滤能力将大大减弱,甚至退化为内存过滤。下面,我们探讨几种典型的边界混合场景。
场景一:非数组字段与数组字段的边界混合
这个场景演示了如何通过混合边界,强化查询的过滤条件。我们创建一个survey集合并插入数据:
db.survey.insertMany([
{ _id: 1, item: "abc", ratings: [ 2, 5, 8 ] },
{ _id: 2, item: "xyz", ratings: [ 5, 8 ] }
])
为其创建一个包含非数组字段和数组字段的复合多键索引:
db.survey.createIndex({item: 1, ratings: 1})
执行如下查询:查找item为“abc”且ratings数组中存在大于等于3的元素的文档。
db.survey.find({item: "abc", ratings: { $gte: 3}})
查看其执行计划,过程非常清晰:
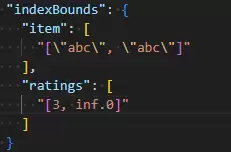
我们来解析查询条件:item: “abc”是一个精确匹配,等价于边界[“abc”, “abc”];ratings: {$gte: 3}等价于边界[3, +∞)。MongoDB成功地将这两个边界混合,创建了一个高效的复合查询范围,从而快速定位到目标文档。
场景二:非数组字段与多个数组字段的边界混合
当查询涉及多个数组字段时,情况会变得复杂。新建一个集合survey2,其中包含嵌套文档的数组:
db.survey2.insertMany([
{ _id: 1, item: "abc", ratings: [ { score: 2, by: "mn"}, { score: 9, by: "anon"}] },
{ _id: 2, item: "xyz", ratings: [ { score: 5, by: "anon"}, { score: 7, by: "wv"}] }
])
创建一个涉及嵌套数组字段的复合索引:
db.survey2.createIndex({item: 1, "ratings.score": 1, "ratings.by": 1})
现在执行这个查询:查找item为“xyz”,且ratings数组中存在分数小于等于5、并且评价者为“anon”的文档。
db.survey2.find({item: "xyz", "ratings.score": { $lte: 5}, "ratings.by": "anon"})
单独分析每个查询条件:
item: “xyz”: 边界是精确的[“xyz”, “xyz”]“ratings.score”: {$lte: 5}: 边界是(-∞, 5]“ratings.by”: “anon”: 边界是精确的[“anon”, “anon”]
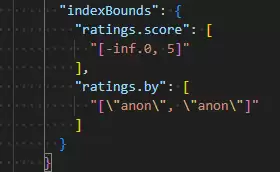
这里出现了一个关键限制:MongoDB能够将item的边界与ratings.score或ratings.by中的一个边界混合,但具体选择与哪个字段混合,取决于查询操作符和索引值的分布。当引擎无法确定时,执行计划也会反映出这种不确定性。如下图所示:
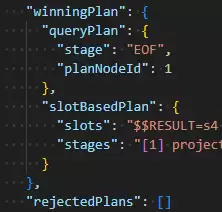
那么,如何确保MongoDB能够成功混合文档数组中多个字段的边界呢?答案是:必须使用$elemMatch操作符。
场景三:混合同一数组中多个字段的边界
要成功混合同一个数组内多个字段的索引边界,必须严格遵守以下两个规则:
- 索引键必须位于完全相同的文档路径上(即使字段名不同)。
- 查询语句必须使用
$elemMatch,并在相同的路径上指定所有条件。
什么是“相同路径”?以点号分隔的字段如“a.b.c.d”,其路径就是“a.b.c”。要混合这个数组内字段的边界,$elemMatch必须作用在“a.b.c”这个路径上,即针对整个数组元素进行匹配,而不是直接针对字段d进行独立查询。
我们在survey2集合上再创建一个专门针对数组内字段的复合索引:
db.survey2.createIndex({"ratings.score": 1, "ratings.by": 1})
然后,构建一个正确使用$elemMatch的查询。该查询要求ratings数组中的同一个元素必须同时满足分数条件和评价者条件:
db.survey2.find({ratings: {$elemMatch: {score: {$lte: 5}, by: "anon"}}})
查看此时的执行计划(如下图),可以看到MongoDB已经成功地将score和by字段的边界混合为一个高效的查询范围,这正是我们期望的优化效果,能极大提升此类数组多条件查询的性能。