很多人认为SRE就是一个“全栈岗位”——招一个人,就能解决所有稳定性问题。这种理解既片面,又过于理想化。
今天,我们就从一线实践出发,聊聊应该如何真正理解SRE。

很多人认为SRE就是一个“全栈岗位”——招一个人,就能解决所有稳定性问题。这种理解既片面,又过于理想化。今天,我们就从一线实践出发,聊聊应该如何真正理解SRE。
一、为什么对SRE的理解如此多样?
不同角色看SRE,视角天差地别:
管理者:希望SRE是“万能稳定器”,一个人就能扛住所有故障。
传统运维:SRE就是把监控做好、告警及时、根因快速定位。
平台/DevOps团队:SRE的核心是容量规划、自动化弹性伸缩,学习Google的完全自动化。
开发团队:SRE就是帮我们把变更风险降到最低。
这些理解都有道理,但都不够完整。SRE并非某个具体的岗位或单一技术,而是一套体系化的工程实践。其核心在于,用软件工程的方法来解决运维问题,最终目标是在支持业务快速迭代的同时,持续提升系统的可靠性。
二、SRE的核心:体系化工程,而非单点能力
SRE的精髓在于“体系化”。它不是简单地把监控、容量、变更、容灾等技术点堆砌在一起,而是让这些组件有机结合,形成一个闭环的稳定性保障体系。
常见的核心组件包括:
- 容量评估与压测
- 全链路监控与智能告警
- 灰度发布与自动回滚
- 故障预案与自动化恢复
- 混沌工程与故障演练
- Blame-free故障复盘
关键在于,这些工作绝非单个SRE或单个团队能独立完成。它要求跨团队协作——开发、运维、平台、监控、业务方必须形成合力,才能发挥最大效能。
Google SRE有一条核心原则:SRE团队应将50%的时间花在工程项目上(旨在减少重复性劳动),而非纯操作性工作。这也解释了,为什么单纯招聘几个“全栈SRE”往往效果不佳——真正的威力,来自于组织机制和配套体系的建设。
三、构建稳定性:推荐“六道防线”模型
稳定性从来不是靠单一防线,而是层层递进的防护体系。在实践中,一个有效的“六道防线”模型(可根据团队规模灵活调整)值得参考。
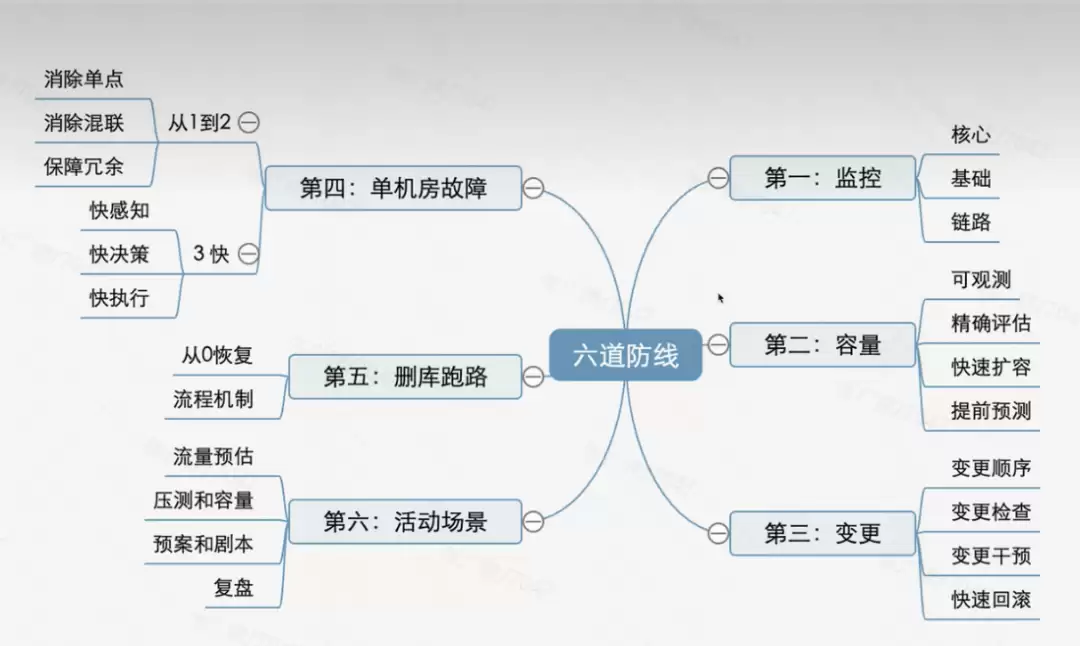
第一防线:监控与发现(快)
关键词:早发现、少而准
核心:建立全链路可观测性(指标、日志、链路追踪),并定义清晰的SLI(服务等级指标,如成功率、延迟、错误率)。
落地建议:可引入AIOps进行异常检测,确保告警“紧急、重要、可行动”,避免陷入告警风暴。
第二防线:容量规划(准)
关键词:防打爆
核心:容量评估、基准压测、流量预测、资源冗余。
落地建议:大促前必须进行全链路压测,建立容量模型,并对数据库、消息队列等关键组件做好多活或冗余设计。
第三防线:变更管理(稳)
关键词:80%的故障源于变更
核心机制:灰度发布、分批上线、自动化检查、快速回滚。
四个关键动作:变更顺序控制、预发布检查、人工/自动干预、秒级回滚能力。
第四防线:故障响应(降低MTTR)
关键词:快恢复
核心:快速感知(告警)、快速决策(预案)、快速执行(自动化)。
落地:标准化应急手册、一键恢复脚本、自动化降级/限流/熔断。
第五防线:容灾与高可用(不挂)
核心:多机房/异地多活、数据备份与快速切换、架构层面的容错设计。
第六防线:活动与高峰保障(可控)
核心:流量预估、动态限流/降级、针对性演练。
四、如何有效降低MTTR?(实践重点)
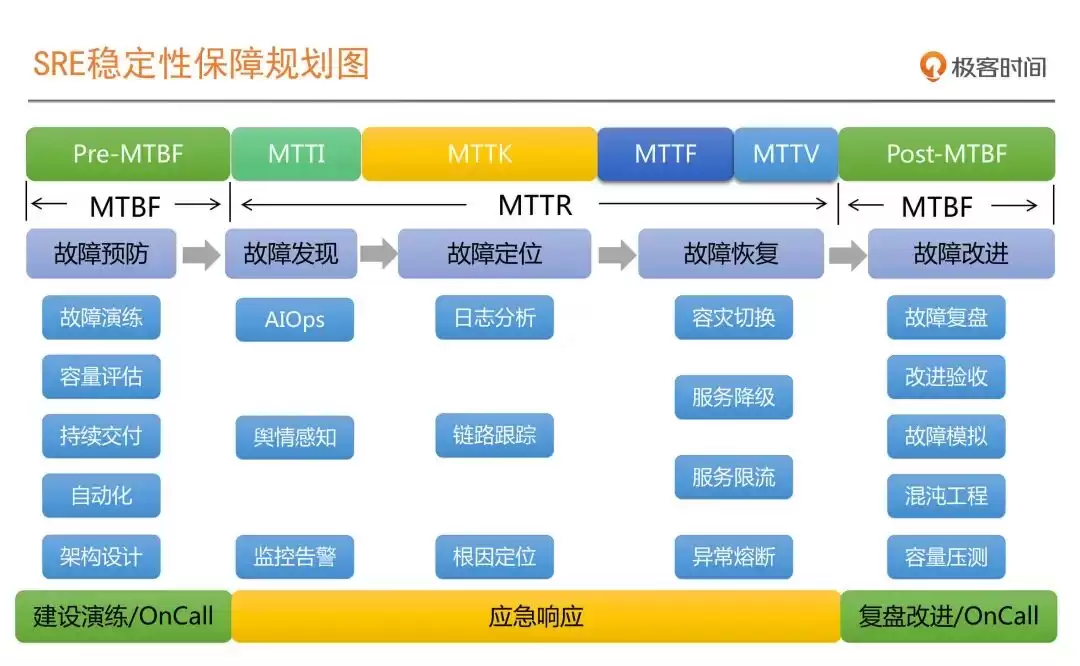
业界常用MTBF(平均故障间隔时间)和MTTR(平均恢复时间)来衡量系统稳定性。提升稳定性,就等于提高MTBF(少出故障)加上降低MTTR(快速恢复)。
MTTR可以进一步拆解为:MTTI(识别时间)+ MTTK(根因确认时间)+ MTTF(修复时间)+ MTTV(验证时间)。
几个实用建议:
- 标准化故障处理:为每类常见故障准备清晰的应急手册,明确现象、原因、处理步骤和命令。
- 自动化恢复:结合Kubernetes Operators等技术,实现自动重启、流量自动切换、弹性伸缩。
- 定期故障演练:利用Chaos Mesh等混沌工程工具,定期模拟数据库性能下降、节点宕机、网络分区等场景,既锻炼平台能力,也磨合团队协同。
- 沉淀知识库:将故障复盘、应急预案、常见问题解答结构化沉淀,便于快速查询。
五、不同角色的SRE进阶建议
- 运维/监控工程师:可以从Prometheus与OpenTelemetry入手,逐步构建全链路可观测性体系。
- DevOps/平台工程师:应重点关注变更风险和减少重复劳动,用工程化手段让发布更安全、更高效。
- 架构师/开发:需将“面向失败设计”融入日常,定义好SLI/SLO,并利用Error Budget(错误预算)来平衡稳定性和创新速度。
Google SRE强调,SRE对技术能力要求极高。从业者不仅需要懂监控、容量、变更,还必须具备分布式系统架构思维和出色的跨团队协作能力。
六、SRE的根本目标
所有SRE工作,最终只服务于两个根本目标:
- 提升MTBF:通过架构设计、限流熔断、混沌工程等手段,减少故障发生。
- 降低MTTR:通过可观测性、自动化、预案演练,缩短故障影响时间。
围绕故障全生命周期(预防 → 发现 → 定位 → 恢复 → 复盘),每一项工作都应对齐这两个目标展开。
总结
SRE不是一个人能扛起来的“全栈救火侠”,而是一套体系化的工程文化与组织协作机制。
记住两点核心:
- 全局视角:单点技术再强,若没有配套的流程、工具和跨团队机制,效果都会大打折扣。
- 明确目标:一切围绕“提高MTBF + 降低MTTR”展开,用SLI/SLO/Error Budget作为量化指引。
无论你是团队负责人、架构师,还是一线工程师,有了这个全局框架,就能更清楚地知道下一步该从哪里入手,以及如何与其他团队真正协同起来。




