理解一个自然语言处理模型的诞生,可以拆解成一环扣一环的六个关键步骤。下面这张流程图,就把这个过程清晰地勾勒了出来。
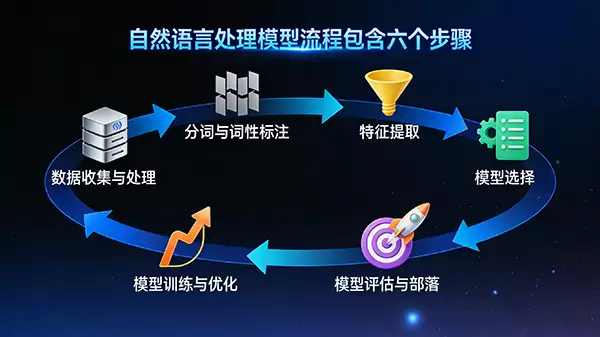
一、数据收集与预处理
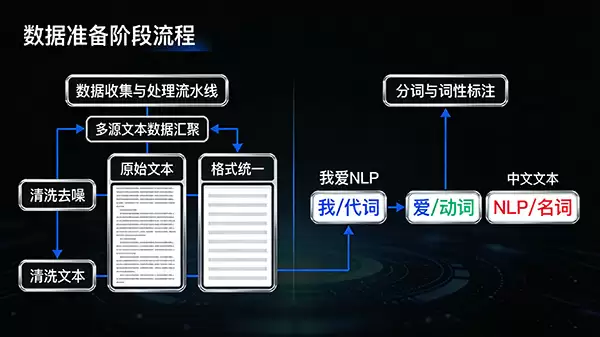
万事开头难,模型的起点在于数据。这一步需要从各种公开或特定的渠道,收集大规模的文本语料——这就是模型的“口粮”。不过,原始数据往往夹杂着大量“杂质”,比如无关字符、格式混乱乃至拼写错误。所以,紧随其后的预处理环节就至关重要了:通过清洗、整理和标准化,把这些原始文本打磨成干净、规整的“原材料”。毫不夸张地说,这一步直接决定了后续流程的根基是否稳固。
二、分词与词性标注
接下来,要让机器理解文本,得先把连续的句子“拆解”成基本的单元,也就是分词。对于像英语这样有空格分隔的语言来说相对简单,但对于中文,分词本身就是一道颇具挑战的关卡。完成分词后,还需要为每个词语“验明正身”,标注上名词、动词、形容词等词性。这就好比给每个零件贴上功能标签,能帮助模型更准确地把握词汇在具体语境中的角色和含义。
三、特征提取
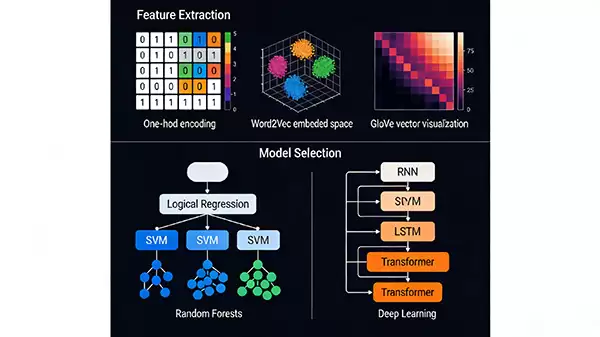
机器无法直接处理文字,所以需要把词语转换为它们“看得懂”的数字形式,即数值向量。从早期的One-hot编码,到后来的Word2Vec、GloVe等词向量技术,本质上都是在为词汇寻找合适的数学“化身”。此外,根据任务需要,可能还会抽取句子长度、词频等额外特征,这些都是为了让模型拥有更丰富的“感官”信息。
四、模型选择
特征准备妥当,就该选择处理它们的“引擎”了。传统的机器学习模型,比如逻辑回归、支持向量机(SVM),在处理小规模、结构化强的数据时往往是得力的干将。而当面对海量数据和复杂语义理解任务时,以循环神经网络(RNN)、长短期记忆网络(LSTM)以及如今大行其道的变换器(Transformer)为代表的深度学习模型,则展现出更强大的威力。
五、模型训练与优化
选好模型架构,真正的“学习”过程就开始了。通过输入大量标注好的数据,模型会不断调整内部参数,学着做出预测。然而,训练绝不是简单的“喂数据”。为了防止模型死记硬背训练集、在陌生数据上表现糟糕(即过拟合),还需要引入正则化、Dropout等技术进行优化。同时,调节学习率等超参数,也是一个精细的调试过程,目标只有一个:让模型变得更“聪明”、更稳健。

六、模型评估与部署
模型训练好了,但功夫到不到家,还得拉出来“考一考”。这时候,就用预留的、从未见过的新数据(测试集)来评估其表现。常用的指标如准确率、召回率、F1值等,会给出客观的量化评判。只有顺利通过评估的模型,才有资格进入最终环节:部署上线,真正投入到聊天机器人、情感分析、机器翻译等实际应用场景中,去解决实际问题。
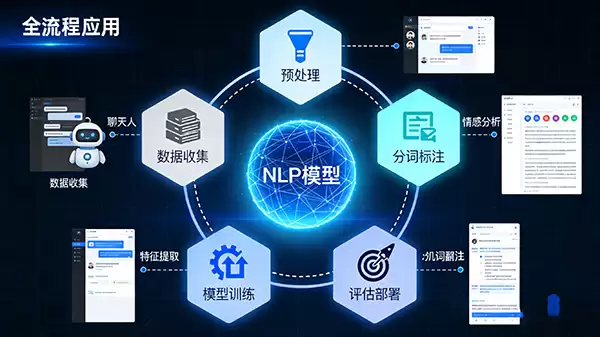
以上六个步骤,构成了一套相对标准化的工作流。当然,实际应用中并没有一成不变的模板,根据任务特性和数据状况,各个环节都可能需要灵活调整和深度优化。但万变不离其宗,理解这个核心框架,是走进NLP世界的第一步。




