BabyVision是什么
在各类多模态模型层出不穷的当下,一个根本性问题常常被忽略:这些宣称能“看懂”图像的模型,其纯粹的视觉理解能力究竟如何?BabyVision的诞生,正是为了回答这个问题。它是由UniPat AI团队精心打造的一套多模态理解评测基准,核心目标在于评估多模态语言模型和图像生成模型在视觉推理任务上的真实水平。这套评测集设计严谨,主要分为MLLM评估和生成评估两大赛道,并从精细辨别、视觉追踪、空间感知和视觉模式识别这四大核心能力维度出发,分解出22项子任务,总计388道题目。最关键的是,这些任务的设计严格控制了对文本线索的依赖,力求剥离语言干扰,逼出模型最本真的视觉“内功”。
BabyVision的主要功能
那么,这套评测基准具体能做什么?它远不止是简单地打一个分数。
- 评估多模态模型的视觉推理能力:通过一系列“去语言化”的严格任务,直接测试模型在纯视觉场景下的表现,精准揭示其在视觉理解能力上的短板与盲区。
- 提供两个评估赛道:它不仅评测多模态语言模型的理解能力,还专门设立赛道评估图像生成模型的“视觉脑补”能力,实现了对多模态技术谱系的全面覆盖。
- 涵盖四大视觉能力类别:从辨别细节到追踪动态,从感知空间关系到归纳视觉模式,其多样化的任务设计如同一次全方位的“视力体检”,能系统评估模型在不同维度的视觉推理水平。
- 严格控制语言依赖:这是其设计的精髓所在。确保所有题目无法通过“耍小聪明”解读文本提示来完成,从而将评测焦点牢牢锁定在视觉能力本身。
- 提供详细的评测结果和排行榜:评测结果会以准确率等量化指标清晰呈现,并生成公开排行榜,还会与人类表现基线进行对比,为研究者提供直观、可靠的横向比较依据。
- 支持快速启动和灵活配置:项目提供了开箱即用的完整数据集、评估脚本和详尽文档。研究人员可以快速上手,还能通过环境变量等方式灵活调整评测参数,大大降低了使用门槛。
- 推动多模态技术的发展:其终极价值在于诊断而非评判。通过精准定位当前模型的共性缺陷,它为未来的算法优化和创新指明了清晰的技术攻关方向。
BabyVision的评测结果
用这套严苛的标准检验当前的主流模型,结果揭示了一些颇为耐人寻味的发现。
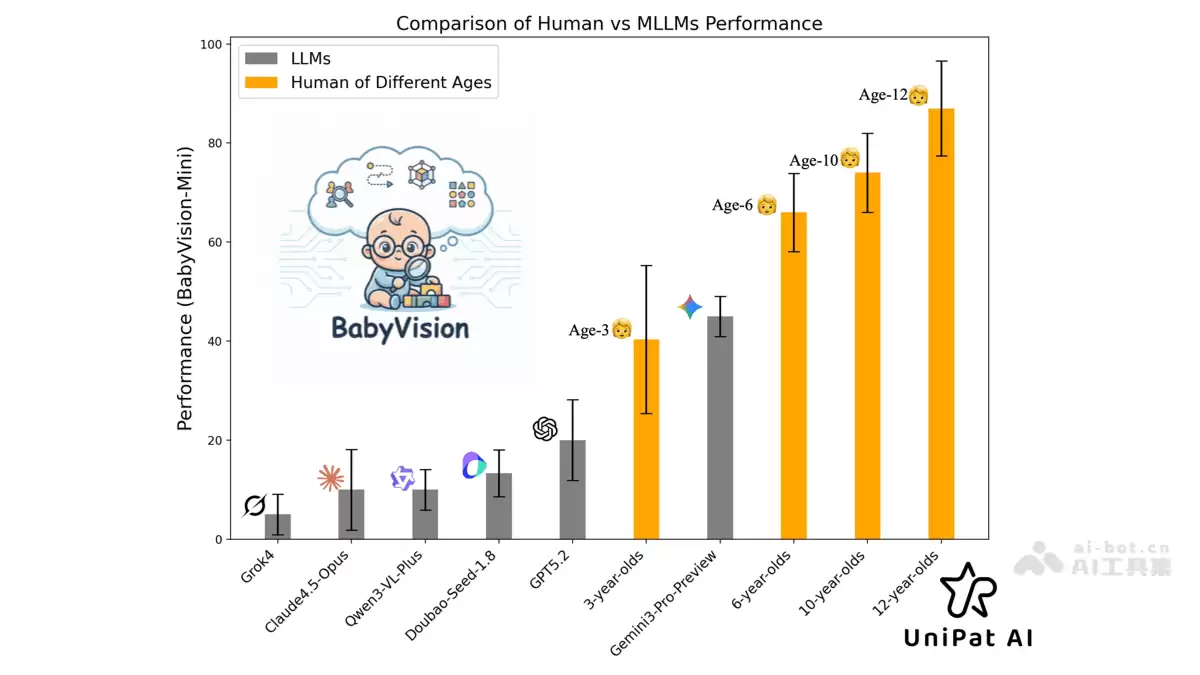
- 人类基线表现卓越:人类测试者在这些任务上的平均准确率达到了惊人的94.1%,这充分证明了人类视觉系统在推理方面的强大与高效,也为AI模型树立了一个清晰的追赶目标。
- 闭源模型表现参差不齐:在闭源模型阵营中,Gemini3-Pro-Preview以49.7%的准确率暂时领先,GPT-5.2和Doubao-Seed-1.8分别录得34.4%和30.2%。尽管存在高低之分,但所有模型的表现距离人类水准仍有巨大鸿沟。
- 开源模型差距明显:开源模型的挑战更为严峻。其中表现较好的Qwen3-VL-Plus准确率仅为19.2%,多数模型的表现不尽如人意,整体上与顶尖闭源模型及人类基线存在显著差距。
- 模型在视觉任务上存在短板:无论是闭源还是开源模型,在面对需要连续视觉追踪、复杂空间想象或抽象几何归纳的任务时,表现普遍乏力。这清晰地暴露出,当前许多多模态模型的“视觉根基”并不牢靠。
- 生成式评估结果不理想:在图像生成评估中,虽然部分模型能展现出一些“看起来更人性化”的操作行为,但整体上,模型仍然缺乏稳定输出完全正确答案的能力,其视觉-动作的推理链条尚不稳固。
- 评测结果推动技术改进:这些直指核心弱点的结果,其价值恰恰在于“揭短”。它为整个领域提供了不可多得的诊断报告,未来的技术优化无疑将从中获得关键启发。
BabyVision的项目地址
- Github仓库:所有感兴趣的研究者或开发者都可以访问其开源项目页面获取完整资源:https://github.com/UniPat-AI/BabyVision。
BabyVision的应用场景
这样一套专业的评测基准,其应用前景相当广泛。
- 多模态模型评估:可作为业界和学术界系统性评估模型视觉推理能力的标准工具,帮助团队客观衡量自身模型的强弱项。
- 技术研究与开发:为AI研究人员提供了一个稳定、可靠的“试金石”,用于在开发迭代过程中检验新算法或架构的有效性,驱动技术进步。
- 模型性能比较:在模型选型或技术调研时,它提供了一个统一的标尺,使得不同模型之间的性能对比变得有据可依。
- 教育与学习工具:对于高校和教育机构而言,它是一个绝佳的教学案例,能帮助学生直观理解多模态AI的能力边界与核心挑战。
- 行业应用参考:对于自动驾驶、医疗影像分析、工业质检等依赖高级视觉理解的行业,评测结果能为技术选型与落地提供重要的性能参考。
- 学术研究与发表:它提供了高质量的标准数据集和评测框架,能够支持并催生更严谨的学术研究,助力相关论文的发表与学术交流。




