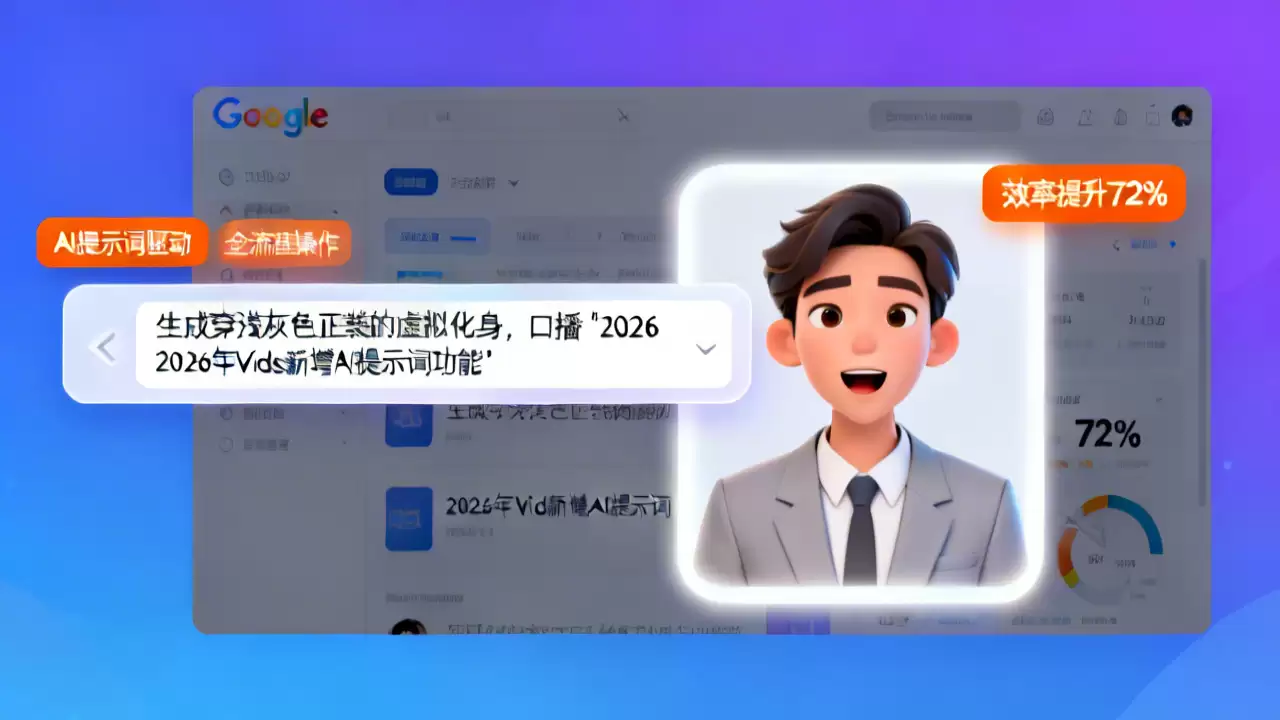
2026年4月,谷歌视频创作工具Vids迎来关键更新
2026年4月,谷歌对其Workspace生态下的视频创作工具Vids进行了一次重磅更新。这次更新引入了基于AI提示词驱动的虚拟化身功能,用户只需输入简单的自然语言指令,就能一站式完成化身形象定制、动作调度,乃至口播内容生成。根据谷歌官方披露的测试数据,这项新功能能将普通用户制作商用口播视频的效率提升72%。目前,该功能已面向所有Vids付费用户全面开放。
职场人的福音:告别繁琐视频制作
说到制作部门宣讲或产品推广的短口播视频,很多职场人都有一肚子苦水。协调出镜人员时间、反复调整妆造、耗费数小时进行后期剪辑……哪怕只是修改一句台词,都可能意味着推倒重来。而现在,谷歌Vids的这次更新,瞄准的正是这种低效的创作模式,意图将其彻底送进历史。
实际体验如何?用户进入Vids的创作界面后,只需在输入框里写下需求。比如,你可以输入:“生成一位身着浅灰色正装的女性虚拟化身,背景是带有公司logo的会议室,请她用活泼的语气介绍本次618营销活动的三个核心权益。”系统就会在一分钟内,生成与之匹配的完整视频片段。更值得一提的是,虚拟化身的唇形、动作和语音语调,都能与文本内容做到精准同步。
如果对初版效果不满意怎么办?很简单,继续“吩咐”AI就行。比如追加指令:“把化身的语速放慢20%,背景换成浅绿色的科技风格。”整个修改过程完全无需任何专业的剪辑技能,即便是新手用户,也有可能在10分钟内产出一支符合商用标准的优质口播视频。
瞄准企业办公:差异化竞争的关键一步
纵观当前的AIGC视频赛道,多数玩家如Runway、Pika等,其主要发力点仍集中在生成创意画面、转换视频风格等泛娱乐领域。而谷歌这次将虚拟化身功能整合进Vids,策略可谓相当清晰——直击企业办公场景下真实、高频的刚需。
有行业调研数据佐证了这一判断:2025年,全球企业对商用短口播视频的需求量同比激增了137%。然而,其中仅有18%的企业有财力负担专业视频团队的成本。谷歌的聪明之处在于,将虚拟化身功能与整个Workspace生态深度打通。用户生成的视频,能够直接无缝嵌入谷歌文档、幻灯片乃至会议纪要中。这不仅是功能的叠加,更是产品护城河的又一次加固。
技术底座:多模态大模型的垂直落地
如此流畅体验的背后,核心支撑是谷歌最新迭代的Gemini 1.5 Pro多模态大模型。要实现从一段文本提示到最终生成形象、动作、语音、背景齐全的视频,对大模型的要求极高。它必须同时具备出色的文本理解能力、3D形象生成能力、高质量的音频合成技术,以及精准的唇形动作匹配技术。
事实上,谷歌在早先Gemini模型的版本迭代中,已经将其3D内容生成的细节精度提升了40%。本次在Vids中的功能落地,正是这项技术迈向大规模商业化应用的关键一步。它也清晰地标志着一个趋势:多模态大模型的应用前沿,正从通用的人机交互,持续向视频创作这类垂直、专业的领域渗透。
未来展望:内容创作的门槛将持续降低
根据谷歌相关负责人的透露,Vids的后续规划中还将开放自定义化身上传功能。这意味着,企业和个人用户可以上传自己的照片,生成专属的虚拟数字分身,用于录制内部培训、产品宣讲等系列内容,应用场景将更加广泛。
业内分析普遍认为,随着AI视频工具能力的持续迭代,一个明确的未来图景正在展开:普通用户无需掌握任何专业创作技能,仅凭提示词就能完成过去需要专业团队协作才能实现的内容产出。这无疑将深刻重构内容创作行业的劳动力分工,并大幅拉低企业的内容生产成本。对于广大企业而言,高效、低成本地进行视觉化沟通,正从一个可选项,迅速变为一项必备能力。