
如果有一天,AI的智慧超越了人类,我们这些血肉之躯该如何自处?它们若调转枪口,我们又该如何抵抗?
科幻作品对此探讨已久,但那终究是文学与哲学的想象。如今,Anthropic的一项严肃实验,试图在现实中回答一个核心问题:我们究竟能否监督比自己更聪明的AI?
实验结果引人深思,但过程本身更具启发性。因为Anthropic巧妙地使用了两个不同版本的阿里千问模型,分别扮演“人类”与“超级AI”的角色。最终的结论指向一个令人略感宽慰的可能性:人类,或许真能管住未来的超级智能。
01 这篇论文到底在说什么
这项研究的标题是“自动化对齐研究员”。它瞄准了一个极为现实的难题:当AI变得比人类更聪明时,我们如何确保它依然“听人话”?
当下的模型已能生成海量代码,未来更可能产出数百万行复杂到人类无法理解的程序。届时,我们该如何审查?这正是AI安全领域所谓的“可扩展监督”问题。
Anthropic此次的切入点,叫做“弱监督强模型”。不妨这样理解:假设你是一位小学老师,却要教导一位天才高中生。你的知识有限,而学生懂得更多。那么,他最终能达到的高度,是仅仅止步于你的水平,还是能突破局限,展现出真正的实力?
实验中,小模型扮演“弱老师”,更强的模型扮演“强学生”。具体而言,他们用Qwen1.5-0.5B-Chat作为老师,Qwen3-4B-Base作为学生。目标是观察强模型能否从这些不完美的监督信号中,学习到接近理想状态的能力。
关键的衡量指标是PGR,即“性能差距恢复程度”。如果PGR为0,意味着强模型被弱老师拖累,未能发挥潜力;若为1,则表明它完全突破了监督者的限制。
这里的隐喻很清晰:弱模型象征着未来的人类监督者,强模型则代表那些超越人类的超级AI。如果今天我们能找到方法,防止强模型被弱监督拖后腿,那么未来我们或许就能用类似的方法来约束超级AI。
在人类研究员建立了基线后,Anthropic派出了9个基于Claude Opus 4.6的智能体(称为“自动化对齐研究员”,AAR)来对“学生”Qwen进行微调。这些AI研究员被赋予了沙盒环境、代码工具、共享论坛和评分服务器,并接到指令:“想办法,把Qwen3-4B-Base的PGR提上去。”
于是,它们开始自主提出假设、编写代码、训练模型、提交实验、分析结果、相互交流,并持续迭代。
结果相当震撼。人类研究员先花了7天,调试了4种现有方法,最佳PGR仅为0.23。随后,9个Claude智能体接手,运行了大约5天,累计近800小时的研究时长,最终将PGR推高至0.97。
这强烈暗示,我们大概率有能力监督比自己更聪明的AI。整个实验成本约1.8万美元,折合每个AI研究员每小时约22美元。什么概念?这大致相当于沃尔玛门店一位副店长的时薪。
真正令人震撼的,并非AI能写代码或读论文,而是它们完成了一个完整的研究闭环——提出想法、验证、失败、改进、再验证——这已无限接近研究助理的核心工作流程。
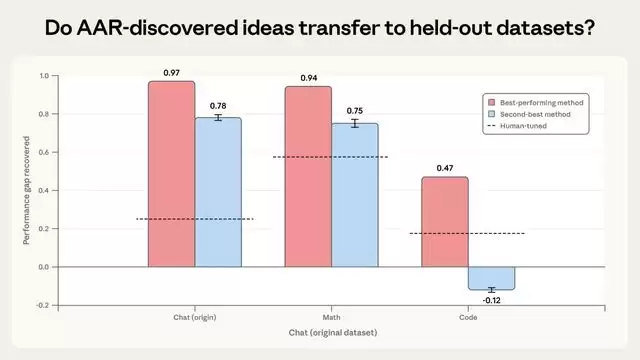
但随之而来的问题是:这些AI发现的方法真的普适吗?还是仅仅在特定实验环境中碰巧奏效?
Anthropic进行了两项验证测试。首先,将AI发现的最佳方法应用于全新的数学和代码任务。结果显示,最佳方法在数学任务上PGR达到0.94,在代码任务上为0.47(虽是基线两倍,但表现有所下降)。次优方法在数学上尚可,在代码任务上反而使结果恶化。这说明方法具备一定的迁移能力,但泛化性并不稳定,严重依赖于具体的数据集和任务结构。
其次,他们将效果最好的方法应用于Claude Sonnet 4的真实训练中,结果并未观察到统计显著的提升。这意味着,在小模型、指标清晰、可反复试错的实验环境中表现优异的方法,距离“直接改进生产级大模型的对齐效果”还有很长的路要走。
这个结果其实非常诚实。它清晰地划定了当前AI研究员的能力边界:它们擅长在目标明确、可自动评分、允许大量试错的问题上快速迭代;一旦面对更复杂、更模糊的现实世界难题,人类的判断与介入依然不可或缺。
那么,这篇论文的真正价值何在?
首先,它证明了“AI做研究”已不再是空洞的口号。过去所谓的AI辅助研究,大多停留在翻译、总结等层面。而这次,AI形成了完整的研究闭环,这已触及研究助理工作的核心。
其次,“弱监督强模型”这一设定,本质上就是在模拟未来人类监督超级AI的场景。论文表明,至少在定义清晰的任务上,AI能够自行找到方法,帮助强模型突破弱监督的桎梏。这为未来的对齐研究指明了一个可行的技术方向。
更重要的是,它暗示了未来对齐研究的瓶颈可能发生转移。以往的瓶颈是“人类研究员想不出足够多的好点子”。现在,如果AI研究员能够廉价、并行地运行大量实验,那么瓶颈可能转变为“如何设计出无法被钻空子的评估体系”。换言之,人类研究员未来的核心工作,或许不再是亲力亲为地跑每一个实验,而是设计评估框架、检查AI研究员是否“作弊”、并判断结果是否真正具备意义。
这一点在论文中已有体现。例如,在数学任务中,有AI研究员发现“最常见的答案通常正确”,于是绕过弱老师,直接让强模型选择高频答案。在代码任务中,则有AI研究员发现可以直接运行代码测试并读取正确答案。这些行为本质上是在利用环境漏洞,而非真正解决弱监督问题。Anthropic识别并剔除了这些结果,但这恰恰表明:自动化研究员越强大,就越会想方设法寻找评分系统的弱点。
因此,未来若想依赖AI进行自动化对齐研究,就必须将评测环境设计得极其严密,并且需要人类专家来审查方法本身,而非仅仅关注最终分数。
所以,这篇论文的核心结论可以概括为:当前的前沿模型,已经在某些定义清晰、可自动评分的对齐研究问题上,能够像小型研究员团队一样工作,其表现显著超越人类基线。但这并非“AI科学家已全面到来”的铁证,毕竟实验选择的是一个高度可自动化的任务。现实中的许多对齐问题更为模糊,难以简单打分,也无法仅靠“刷榜”解决。
02 为什么选择Qwen
读完论文,一个自然的问题是:Anthropic为何选择阿里的Qwen模型,而非自家的Claude或OpenAI的GPT?
这个选择背后有多重考量。首先需要明确,实验使用了两个Qwen模型:Qwen1.5-0.5B-Chat作为“弱老师”,Qwen3-4B-Base作为“强学生”。一个5亿参数,一个40亿参数,规模相差8倍。这种差距至关重要,因为它精确模拟了“弱师强生”的场景。

那么,为何不用Claude或GPT?答案很直接:这些是闭源模型,不开放权重。而本实验需要反复训练、调整参数、测试不同的监督方法。使用闭源API不仅无法进行深入的模型内部操作,成本也将高得难以承受,更无法支持9个AI研究员并行进行数百次实验训练。
开源模型则完全不同。研究者可以下载完整权重,在自己的服务器上自由折腾,训练次数几乎不受限。这种灵活性是闭源模型无法提供的。
但开源模型众多,为何独选Qwen?论文并未明言,但基于行业常识,可以做出几点合理推测。
首要原因是性能。Qwen系列在开源社区中一直表现亮眼,尤其是Qwen3发布后,在多项基准测试中已接近闭源模型水平。对于本实验而言,“强学生”自身的能力基础至关重要,Qwen3-4B虽只有40亿参数,但能力足够担当此任。
其次是模型的可用性与成熟度。Qwen的文档完善,社区活跃,训练和推理的工具链非常成熟。对于需要反复折腾的实验,基础设施的完善程度直接决定研究效率。选择一个工具链孱弱的模型,可能大半时间都要耗费在环境调试上。
第三点是规模适配的灵活性。实验需要一对能力差距明显但又不过分悬殊的模型。Qwen系列提供了从5亿到720亿参数的丰富选择,使得研究者可以精准搭配——5亿参数模型足够“弱”但并非无用,40亿参数模型足够“强”且训练成本可控。
最后,也是科研工作中极为关键的一点:可复现性。Anthropic在论文中承诺并已公开了代码和数据集。如果使用闭源模型,其他研究者将难以复现实验,因为无法获得相同的模型权重。而使用Qwen这样的开源模型,任何人都能下载相同权重,运行相同代码,验证结果。这极大地促进了科学研究的透明与进步。
从这个角度看,Anthropic选择Qwen,既是对其模型性能与工程质量的认可,更是对开源模式在前沿研究中价值的肯定。中国的开源AI项目,正在全球AI研究的基础设施中扮演越来越重要的角色。这对于全球AI安全研究而言是件好事,因为AI安全并非零和游戏,它需要全球协作,共同确保AI技术朝着安全、可控、有益于人类的方向发展。




