核心要点
在探讨深度学习框架的设计哲学时,命令式编程与符号式编程的区分并非总是非黑即白。以CXXNet和Caffe为代表的框架,它们通过配置文件来定义模型结构。如果我们把这份配置文件本身视为计算图的声明式描述,那么这类框架同样可以被纳入符号式编程的范畴。这启示我们,分类的本质在于其核心设计理念,而非具体的代码表现形式。
文章来源
源网址
深度解析:符号式编程与命令式编程
如果你熟悉Python或C++等通用编程语言,那么你对命令式编程范式应该非常了解。这种编程风格的核心特征是“即时执行”——代码编写到哪里,计算就立即执行到哪里。我们日常开发中的绝大多数Python脚本都采用这种模式。来看一个典型的命令式编程示例:
import numpy as np
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
d = c + 1当程序执行到 c = b * a 这一行时,乘法运算会立即进行,计算结果被直接赋值给变量c。
符号式编程则遵循截然不同的逻辑。在这种范式下,开发者首先需要定义一个完整的计算流程(这个定义可能非常复杂),但在定义阶段,并不会执行任何实际的数值运算。定义中使用的是抽象的符号占位符。只有当提供了具体的输入数据,并显式触发“编译”过程后,整个计算函数才会被真正执行。用符号式风格重写上述例子,其逻辑如下:
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
# 编译生成可执行函数
f = compile(D)
d = f(A=np.ones(10), B=np.ones(10)*2)请注意,语句 C = B * A 在此处并不会触发数值计算,它仅仅是在内存中构建了一个描述计算步骤的“数据流图”,我们称之为计算图或符号图。下图清晰地展示了计算D所对应的符号图结构:

绝大多数符号式框架都包含一个显式或隐式的“编译”步骤,其核心目的是将这张高级的计算图转换为底层可高效执行的函数。在上面的例子中,真正的数值计算直到最后一行调用f()时才发生。这种“先声明定义,后编译执行”的两阶段模式,是符号式编程的显著标志。在深度学习领域,这张计算图通常就完整定义了神经网络模型的前向传播与反向传播结构。
观察主流深度学习框架,Torch、Chainer、PyTorch(Minerva是其前身之一)是命令式风格的代表。而Theano、CGT以及TensorFlow则采用了符号式风格。至于CXXNet和Caffe这类基于配置文件的框架,如前所述,其配置文件本质上是一种声明式的计算图定义,因此也可归入符号式风格的阵营。接下来,我们将深入剖析这两种编程范式各自的优势与适用场景。
命令式编程的优势:灵活性与易用性
使用Python调用命令式风格的深度学习库非常直观,感觉就像在编写标准的Python代码,只是在需要进行高性能计算的地方调用了库函数。然而,若使用Python调用符号式风格的库,编程范式就需要转变。一个常见的限制是:某些原生的Python控制流结构(如动态循环)可能无法直接使用。尝试将下面这段命令式代码转换为符号式风格:
a = 2
b = a + 1
d = np.zeros(10)
for i in range(d):
d += np.zeros(10)如果符号式API不支持原生的Python for循环,转换就会变得复杂。这意味着,开发者不能完全以编写普通Python程序的方式来使用符号式库,而必须使用框架提供的特定领域语言来构建计算图。这套DSL虽然功能强大,足以描述各种复杂的神经网络架构,但也带来了额外的学习成本。
直观来看,命令式程序更符合程序员的思维习惯,上手更快,调试也更方便。例如,你可以在执行流的任意位置打印张量的值进行调试,也可以自由地使用if-else条件分支、for/while循环等熟悉的控制语句,实现复杂的动态逻辑。
符号式编程的优势:执行效率与优化潜力
既然命令式编程如此灵活且符合直觉,为何众多深度学习框架仍选择符号式风格?根本原因在于其对执行效率的极致追求——包括内存使用效率和计算运行效率。
让我们回顾最初那个简单的计算示例:
import numpy as np
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
d = c + 1
...
假设每个数组元素占用8字节内存,在Python的命令式程序中,需要分配多少内存?答案是,每一行代码执行时,都会为新的结果张量分配独立的内存。四个长度为10的数组,总共需要 字节。
然而,如果系统在编译期就已知我们最终只需要结果d,情况就完全不同了。在构建符号计算图时,编译器可以进行全局的内存规划,安全地复用中间变量的存储空间。例如,通过原址计算优化,可以将存放b结果的内存,直接用于存放c;同理,c的内存又可以复用于存储d。如此一来,整个计算过程可能只需要两个数组的内存,即 字节,内存消耗减少了一半。
当然,这种高效性是有代价的。符号式程序的限制更多。因为编译器知道我们只需要最终的d,在优化过程中,像c这样的中间变量的值,在计算完成后可能就无法被用户代码访问了。而命令式程序则灵活得多,在执行过程中的任何时刻,所有中间变量的值都可以被随时访问和检查,便于调试。
符号式编程的另一个关键优势是“算子融合”优化。在我们这个例子中,乘法和加法两个操作可以被融合成一个更大的复合操作,如下图所示:
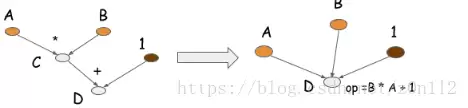
如果在GPU上运行,融合后的计算图只需要启动一个内核,避免了多次内核启动带来的开销。事实上,在Caffe/CXXNet这类早期框架中,工程师需要手动编写融合后的计算内核来实现性能优化。而符号式程序可以在编译阶段自动完成此类算子融合,因为它掌握了完整的、全局的计算图信息,能够精确分析出哪些值是最终需要的,哪些只是临时的中间结果。
相比之下,命令式程序由于无法预知未来哪些中间变量会被访问或依赖,因此很难安全地进行这种全局的、激进的操作融合优化。这正是在深度学习框架设计中,开发者需要在编程灵活性与运行时极致效率之间做出的核心权衡。




