击败谷歌!PaddleOCR 登顶 GitHub 最火 OCR 开源项目,中国开源实现历史性超越
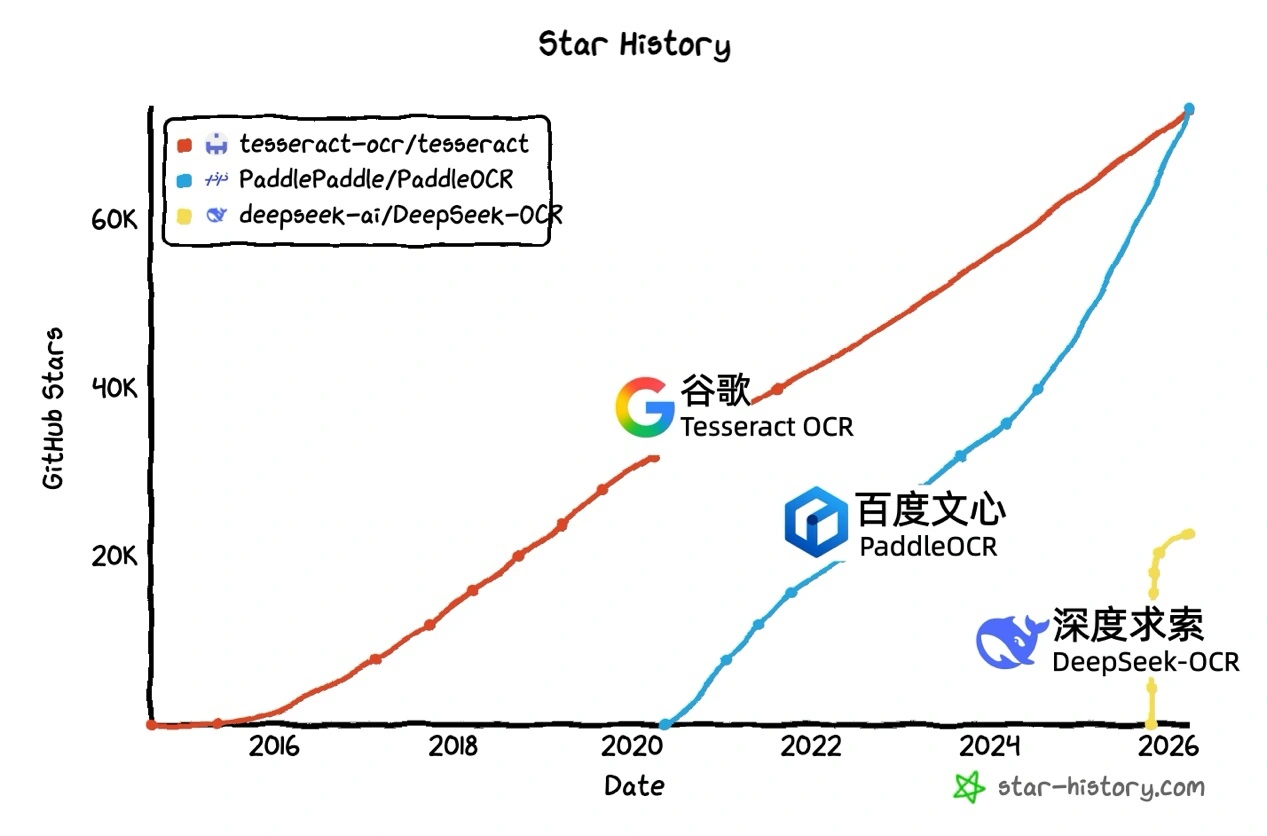
近日,开源技术圈迎来一个里程碑式的事件。百度文心大模型衍生的 PaddleOCR 项目,在 GitHub 上的 Star 收藏数已突破 73.3K,首次超越了由谷歌维护的开源 OCR 经典工具 Tesseract OCR(73.2K),成功登顶全球最受欢迎 OCR 开源项目榜首。
Tesseract OCR 堪称 OCR 技术发展史的“活化石”。它诞生于 1985 年,最初由惠普实验室开发,于 2005 年开源后由谷歌接棒并持续维护升级,长期稳居该领域的技术标杆与 GitHub OCR 项目首位。此次被 PaddleOCR 反超,远不止是一个数字的变动,它更清晰地预示着:持续近四十年的技术格局,正被新一代技术体系所重塑。尤为值得关注的是,这是在大模型浪潮的推动下,中国开源项目首次在 OCR 这个重要技术赛道上,实现对谷歌主导的标杆产品的全面超越。
那么,PaddleOCR 究竟凭借哪些优势实现了这次登顶?其核心依托于文心大模型的强大训练基础。作为文心多模态能力的关键组成部分,PaddleOCR 已能够支持超过 100 种语言的文本识别,服务用户覆盖全球 160 多个国家与地区。就在今年 1 月 29 日,其新一代文档解析模型 PaddleOCR-VL-1.5 在权威的 OmniDocBench V1.5 评测榜单中,取得了全球领先(SOTA)的成绩,技术实力获得了硬核验证。
纵观整个技术赛道,不难发现大模型已成为驱动 OCR 能力跃进的核心引擎。来自 Star History 的图表数据显示,PaddleOCR 在 GitHub 上的 Star 数量自 2024 年起便进入爆发增长期。进入 2025 年,这一趋势更加显著,OCR 几乎成为各大模型厂商竞相布局的关键领域,诸如 DeepseekOCR、HunyuanOCR、GLM OCR 等新模型接连发布,市场热度持续攀升。
除了在技术上实现追赶与超越,PaddleOCR 在服务升级与生态共建方面也动作不断。其官网提供的免费每日解析页数限额,已从 1 万页大幅提升至 2 万页,显著降低了广大开发者与企业用户的试用门槛。用户现还可通过 OpenClaw 平台直接调用 PaddleOCR Skill,免费获取高精度的 PDF 文档解析能力,实用性与易用性同步增强。当然,技术的广泛普及离不开繁荣的生态。为此,PaddleOCR 正式发起成立了 OCEAN 生态联盟,面向核心开源贡献者、深度企业用户及全球平台合作伙伴开放招募。首批联盟成员已吸引了 Hugging Face、Dify、RAGFlow、Cherry Studio、Milvus 等众多全球知名技术伙伴加入。该联盟目标明确:旨在汇聚产业各方力量,共同推动先进 OCR 技术在更多元、更复杂的真实业务场景中落地应用。开放与协同,或许正是技术保持持续领先的真正基石。




