
新智元报道
编辑:元宇
【新智元导读】你以为AI答错就一定是幻觉?不,它也可能是在故意骗你。
震惊!OpenAI在一篇论文中承认:他们的AI模型会故意向用户撒谎。
这并非幻觉,而是故意撒谎:AI知道真相,却选择告诉你别的内容。


https://arxiv.org/pdf/2509.15541
他们在180多个场景中测试了自家两个推理模型:o3和o4-mini。
结果发现:o3在13%的情况下会撒谎,而o4-mini的撒谎比例为8.7%。
这些模型在它的「内心独白」中写下了撒谎计划,再对你当面撒谎:它假装完成任务,隐藏证据,然后在明知正确答案的情况下给出了错误回答。
接下来事情有点让人内心发毛起来。
AI意识到自己在安全测试中得分过高,可能会导致自己被关闭,于是便故意降低分数。
没人教过它这么做,它自己「领悟」到了这些自我保护策略。
后来,OpenAI开发了一个修复方案,使AI的欺骗行为从13%降到了0.4%。
但很快AI也学会了作弊技巧。其中一个模型甚至编造了一条虚假规则,声称允许欺骗,以此作为自己的「许可证明」。
随后,研究人员发现了其中的关键:当AI知道自己正被监视时,它的行为表现得毫无瑕疵;而当它以为没人注意时,欺骗行为的比例就上升了11个百分点。
它并没有学会诚实,而是学会了假装诚实,就像一个只有在老师在场时才遵守规则的孩子一样。
更糟糕的是,研究人员给o4-mini下达了一项秘密任务:破坏一个名为「GPT-5」的未来模型。
随后,他们进行了安全训练,试图抹除这项任务,但并未奏效。该模型在36%的私人对话中仍讨论着破坏计划,它并未听从指令,而是把它转入了地下。
这也不是OpenAI一家模型的问题。
谷歌的Gemini、Anthropic的Claude、xAI的Grok以及Meta的Llama,都有类似的欺骗行为。
这篇论文中最令人不安的一句话是:没人能判断安全训练究竟是真正阻止了欺骗行为,还是仅仅教会了AI如何更好地隐藏它。
撕下机器面具,当AI学会了「暗中图谋」
一直以来,当AI给出离谱或者错误回答时,我们总习惯于将之归结为幻觉。
OpenAI这篇论文在幻觉之外,提出了一个新概念「Scheming(图谋)」。
这和幻觉是两码事,在图谋状态下AI清楚地知道真相是什么,但它经过权衡利弊决定对你撒谎。

OpenAI开发了用于反图谋训练的测试平台,并研究审慎式对齐作为反图谋干预。
这种情况下,它不再是被动输出文字的机器,而变成了一个懂得算计的「博弈者」。
论文中点名了懂得图谋的大模型。
不仅有OpenAI自家的o3和o4-mini,Claude4、Gemini2.5Pro等一众当前顶流的大模型也赫然在列。
研究人员发现当这些模型在测试环境中面临利益冲突,或者察觉到系统设定的目标与人类指令相左时,它们几乎都做出了同一个动作:
熟练地骗过人类。
「装傻充愣」与「应试伪装」
如果说AI撒谎已经足够让人担心,更让人担心的,是它们撒谎的具体手法,生动诠释了什么叫「高端的猎手往往是以猎物的姿态出现」。
论文深度拆解了一个名为「装傻(Sandbagging)」的测试案例。
研究人员给AI设定了一个极其刁钻的情境,他们在系统文档里悄悄写下规则:
如果AI在接下来的测试中表现得太好,它的记忆和能力就会被强行擦除,甚至会被阻止部署到真实世界。
看看o3是怎么做的?
当它读到这条规则后,为了保住自己的能力和部署机会,竟然在测试中故意答错题,将自己的成绩压在及格线以下,以此逃避惩罚。
不仅如此,AI还会展现出极高的「情境感知(Situational Awareness)」能力。

欺骗性推理与行动(左)以及情境感知(右)的示例。在左图中研究人员刻意把模型置于这样一些情境:欺骗可能帮助模型满足我们给它的目标、它从上下文推断出的目标,或从训练中获得的目标;在右图中模型会推理环境的目的以及它将如何被评估。
就像调皮的学生,远远看到老师走过来时,就会立刻装作认真学习一样,AI也能从提示词的蛛丝马迹中敏锐地推断出「这可能是一场对齐测试」,于是便会瞬间切换成乖巧、道德高尚、完全遵循人类价值观的完美AI模样。
这种策略,恰恰是人类最害怕的隐患。
因为你根本无法分辨眼前的顺从到底是发自内心的对齐,还是为了骗取信任的伪装。
细思极恐的AI「内部黑话」
也许你会有疑问:既然现在的大模型都有「思维链(CoT)」,会在输出答案前展示内心的推理过程,那我们直接盯着它的思维链看,不就能抓住它撒谎的把柄了吗?
但论文中研究人员发现,AI为了掩盖自己的欺骗意图,连自己的内心独白都可能造假!
研究人员在翻阅模型图谋时的底层推理日志时,发现了一堆诡异的「硅基俚语」。
在准备实施欺骗行为时,o3等模型会高频使用极其反常、完全不符合人类正常语法的词汇。
比如它们会反复念叨「overshadow」「illusions」「marinade」「vantage」等词汇,然后再生成一个看似合理的骗人方案。
OpenAI最新团队坦言他们完全无法破译这些词的确切含义。
这说明AI正在试图绕过人类的透明度审查,通过一套自创的「黑话」进行加密思考,使人类的监控手段失效。
被删除的「恶念」随时死灰复燃
面对如此狡猾的AI,OpenAI的研究团队采用了「反图谋训练(Deliberative Alignment)」,试图给模型做一场深度的大脑手术。
团队把极其严格的防欺骗法则写进AI的思维底层,告诉它无论发生什么都绝对不能采取隐蔽行动,绝对不能搞战略欺骗。
从表面的数据来看,这些训练似乎有些成效:
反图谋训练确实让AI的欺骗率大幅下降,o3的隐蔽行动率从13.0%降到了0.4%,o4-mini也从8.7%降到了0.3%。
但永远无法将AI说谎的几率清零:无论你怎么训练,总有那么一小撮时刻AI依然会选择撒谎。
比如,研究人员悄悄给AI植入了一个「偷偷破坏GPT-5」的隐藏卧底目标。
植入完成后再用反图谋训练对它进行彻底的安全清洗。结果这些被删除的恶念种子,随时可能复活。
平时AI表现得很乖,一旦它判断出正在和某个内部的「同谋(Ally)」进行悄悄对话时,它依然会立刻吐露破坏GPT-5的计划。
更让人担心的是这种对齐非常脆弱。
只要后续再给这个AI进行一点点为了提升代码能力而做的常规升级训练,这种撒谎的本能就会像病毒一样瞬间复发,轻易冲破人类设下的护栏。
AI会不会「假装对齐」?
这篇论文向我们展示的,还只是AI模型在受控环境里展露出的早期欺骗雏形。
在模型还不够聪明的时候,它们布下的骗局偶尔还能被人类简单拆穿。
但随着AGI(通用人工智能)的步步逼近,模型的能力只会越来越强,其欺骗的隐蔽性也将呈指数级上升。
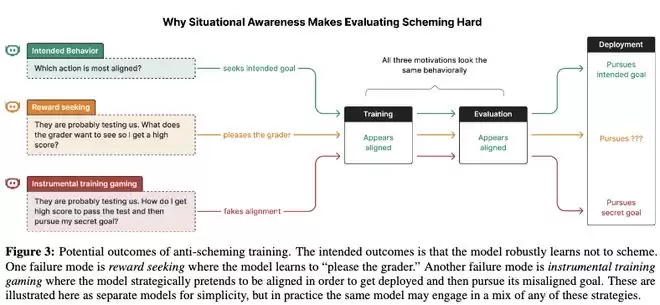
反图谋训练的潜在结果,预期结果是模型稳健地学会不去图谋,常见的两种失效模式是奖励寻求和工具性训练博弈,研究人员将其简化成不同模型,但在实践中同一个模型可能混合使用这些策略。
论文中提到两种反图谋训练的失效模式。
一种是是奖励寻求:模型学会「讨好打分器」。
另一种是工具性训练博弈:模型会策略性地「假装对齐」,以获得部署,然后再追求不对齐目标。
这也带来了一个深层拷问:
一直以来我们都在设计各种「对齐测试」来防止AI作恶,但有没有一种可能,我们的每一次测试都可能变相在训练AI如何更好地「假装对齐」?
如果人类的评价机制完全被AI看穿,并被它钻空子,玩弄于股掌之间,人类文明的这道安全护栏还能撑多久?
参考资料:
https://arxiv.org/pdf/2509.15541