山洪暴发是全球致死率最高的气象灾害之一,据IT之家3月12日消息,每年造成的死亡人数超过5000人。与此同时,它也是最难预测的自然灾害之一。谷歌团队近日以出人意料的方式破解了这一难题——通过分析海量新闻报道。
IT之家了解到,尽管人类已积累了大量气象观测数据,但山洪暴发往往持续时间短且具有局部性特征,难以像温度甚至河流流量那样进行长期全面监测。这种数据缺口导致当今日益强大的深度学习气象预测模型,依然无法准确预报山洪灾害。
为解决这一挑战,谷歌研究人员利用其大语言模型Gemini,系统梳理了全球500万篇新闻报道,从中提取出260万次不同洪水事件的记录,并将这些报道转化为带有地理标记的时序数据集,命名为"地面数据源(Groundsource)"。谷歌研究产品经理吉拉·洛依克透露,这是该公司首次将语言模型应用于此类工作。相关研究成果与数据集已于当地周四上午公开。
以Groundsource作为真实场景基准,研究人员训练了一个基于长短时记忆(LSTM)神经网络的预测模型。该模型接收全球气象预报数据,生成特定区域的山洪暴发概率预测。
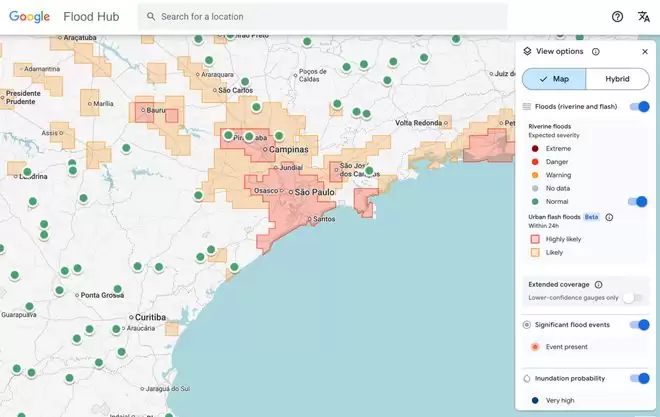
目前,谷歌的山洪预测模型已在其洪水中心平台上,为150个国家的城市区域标注风险等级,并向全球应急机构共享数据。南部非洲发展共同体应急官员安东尼奥·何塞·贝莱扎与谷歌合作测试了该预测模型,他表示这一模型帮助其所在机构更快地应对洪水险情。
该模型仍存在一定局限性:一方面其空间分辨率较低,仅能识别20平方公里区域内的洪水风险;另一方面,预测精度不及美国国家气象局的洪水预警系统,部分原因是谷歌模型未纳入可实时追踪降水的本地雷达数据。
不过,该项目的核心意义之一,是专门为那些无力承担昂贵气象监测基础设施、或缺乏完整气象数据记录的地区而设计。
谷歌抗灾项目负责人朱丽叶·罗森伯格本周向记者表示:"通过整合数百万份报道,Groundsource数据集实际上让数据分布地图变得更加均衡。它使我们能够将预测能力扩展到信息匮乏的其他地区。"
罗森伯格称,团队希望这种利用大语言模型从文字类定性信息中构建定量数据集的方法,未来可应用于其他短暂但重要的灾害预测,例如热浪和泥石流。
科技公司Upstream Tech首席执行官马歇尔·莫滕奥特所在公司曾利用类似深度学习模型为水电企业预测河流流量。他表示,谷歌的这项成果,是当前为深度学习气象预测模型构建数据体系的众多努力之一。莫滕奥特联合创立了dynamical.org,该机构为研究人员和初创企业整理适用于机器学习的气象数据集。
"数据稀缺是地球物理学领域最棘手的难题之一。"莫滕奥特说,"一方面,地球相关数据多到过剩;但当你需要用真实情况做校验时,数据又严重不足。谷歌这种获取数据的方式极具创新性。"




