
文 | 华商韬略 方乐迪
资本的嗅觉更诚实,在火热的具身智能赛道,一家名为帕西尼(Pasini)的公司不靠机器人动作炫技和后空翻,却靠干了件“苦差事”,并因此获得了超过10亿元人民币的B轮融资,将自己的估值一举推过了百亿门槛。
这轮融资的背后,站着一排重量级玩家:黄浦江资本领投,Meta关联方、比亚迪、京东等产业巨头赫然在列。
这并非又一个被资本热炒的概念。巨头们用真金白银投下的,是对一项“看不见的富矿”——真实世界里的多模态触觉数据——的集体认可。他们买的,是帕西尼在数据闭环上的核心竞争力。
具身智能的未来市场广阔,麦肯锡预测到2030年将超过万亿美元,横跨制造业、物流和服务业。然而,整个行业都饱受“数据饥渴症”的困扰。Gartner的数据显示,高达80%的AI项目因为数据质量问题而延期。市场上不缺数据,但极度缺乏能让机器人真正“上手”的高质量触觉数据。

想象一下,让你用手拿起一个纸杯、一块海绵和一块生铁,你会毫不费力地用出三种完全不同的力道。这是人类的本能,是无数生活经验沉淀下来的肌肉记忆。
但对于机器人来说,这个简单的动作却难如登天。它不知道该用多大的力,是会捏碎纸杯,还是抓不稳铁块。这背后微妙的力矩控制,必须依赖海量、高质量的数据来“喂养”和训练。
帕西尼之所以能脱颖而出,正是因为它提供的不是普通的数据,而是一种“定义权”——定义机器人如何感知和与物理世界交互的标准。这套定义权,建立在三大坚实的支柱之上。

【支柱一:从“看见”到“摸到”,补上机器人缺失的感官】
长期以来,行业主流的AI模型严重依赖视觉数据,就像给机器人装上了眼睛,却忘记了给它一双能感知的手。这导致机器人在物理交互上表现平平。例如,波士顿动力(Boston Dynamics)的Atlas机器人虽然在跑跳和平衡上技惊四座,但由于缺乏触觉,它很难完成需要精细操作的任务。
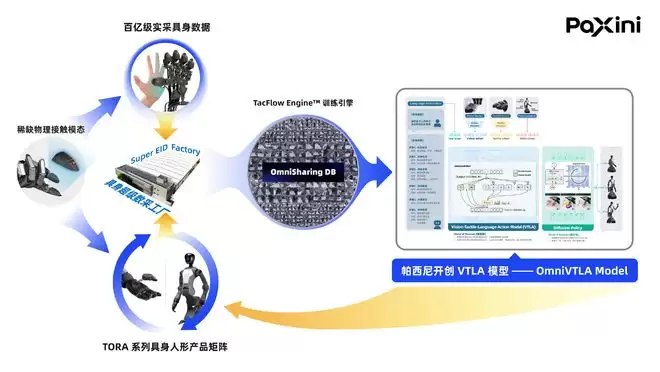
帕西尼另辟蹊径,通过自研的硬件,大规模采集视觉之外的触觉等多模态数据,构建了名为OmniSharing DB的百亿级实采数据库。这是全球独家的宝贵资源,它重新定义了“全模态数据”的标准:数据不仅要包含“看到”的信息,更要融入“物理接触”的信息。
IDC估算,这种多维度的数据能将模型的泛化能力提升20%到30%。Figure AI在融资68亿美元后,也重点强调了多模态训练,并与宝马合作进行汽车装配,这恰好验证了数据维度对于应用落地效率的关键作用。
帕西尼的探索,正在推动整个赛道从“视觉优先”向“全感官”的模式转型,为制造业和服务业的自动化释放出巨大的潜力。
【支柱二:告别手工作坊,用“超级工厂”工业化生产数据】

采集核心的触觉数据,靠实验室里几台机械臂敲敲打打的“手工作坊”模式是行不通的。为了解决这个问题,帕西尼投入重资,在天津建起了一座名为“Super EID”的超级数据采集工厂。
在这里,每天都有成千上万次的抓取、装配和接触在真实物理世界中发生,机器与人协同工作,每年能产出近百亿条高质量的实采数据。这种模式将数据收集从零散的项目制,升级为标准化的流水线生产,构筑了强大的规模壁垒。
相比之下,传统的数据采集方式,规模、质量和一致性都难以保证。即便是OpenAI的机器人项目,也曾因数据体量的限制而导致迭代周期漫长。麦肯锡的分析指出,规模化的数据能够将AI部署成本降低15%至40%。这与特斯拉(Tesla)的Dojo系统异曲同工——通过自采海量驾驶数据,特斯拉几乎垄断了自动驾驶市场,并获得了显著的市值回报。帕西尼的策略,正是在具身智能领域复制这一成功路径。
【支柱三:源于真实,拒绝“活在模拟器里”的AI】
其他数据方式仍有一定局限性,譬如与现实世界之间存在着“鸿沟”。许多在模拟器里表现完美的模型,一旦进入真实环境就错误百出,Google的PaLM-E模型就曾面临这样的泛化难题。

帕西尼从一开始就坚持“以人为中心”的实采模式,所有数据都源于真实的交互任务。这确保了数据的“血统纯正”,也让数据与模型之间建立了清晰的因果关联,极大地提升了模型的性能转化效率。根据Forrester的报告,真实数据能将机器人的训练周期缩短30%。亚马逊的仓库机器人就是最好的例子,在早期仿真方案失败后,团队果断转向实采数据,最终将分拣效率提升了50%。
如今,帕西尼的数据优势正在帮助比亚迪等合作伙伴解决产线装配中的实际痛点,推动着物流与制造领域价值链的深刻重构。
手握“数据定义权”,帕西尼的硬件、数据与模型的协同,不仅让其自研的OmniVTLA大模型在精细操控能力上持续领先,更将“数据定义权”升级为了“技术定义权”——帕西尼卖的不仅是数据,更是整个行业的标准。
在商业上,与Meta、京东等巨头的合作,让帕西尼的数据价值在汽车和物流等关键场景中得到验证,进一步巩固了其领导地位。这轮新的融资将用于扩建数据工厂和加速模型迭代,让已经转起的飞轮更加势不可挡。
帕西尼的故事预示着,具身智能已经进入了“数据资产 + 闭环效率”的全新时代。谁能掌握最深厚、最真实的数据,谁就能定义行业的未来。帕西尼不仅为自己打开了通往更高估值的大门,也为所有硬科技企业提供了一个构建深层护城河的全新范式。
欢迎关注【华商韬略】,识风云人物,读韬略传奇。
版权所有,禁止私自转载
部分图片来源于网络
如涉及侵权,请联系删除




