当前,通用人工智能正以前所未有的速度发展,对大规模算力的需求正呈现爆发式增长。在这样的背景下,如何高效地协同异构算力,从而充分释放计算潜能并有效降低成本,已成为行业关注的核心议题。作为国产AI芯片领域的重要参与者,天数智芯始终致力于深耕算力芯片的技术创新,并深度融入了上海人工智能实验室的DeepLink开放计算体系。从跨域混训到多元混推,天数智芯全程参与并助力构建了DeepLink“训练+推理”全栈算力赋能方案,旨在盘活国产异构算力资源,为筑牢“人工智能+”的算力底座注入坚实的核心芯片力量。

自DeepLink体系推出以来,天数智芯便已成为其核心生态合作伙伴。依托自研智算芯片的技术优势,公司深度参与了异构算力的适配与优化工作。2025年,当DeepLink超大规模跨域混训技术方案落地时,天数智芯芯片已完成深度适配,凭借其高算力与高吞吐特性,成功支撑了跨数千公里多智算中心、长稳混训千亿参数大模型的关键任务,助力实现了等效算力达单芯片单集群95%以上的优异成果,充分验证了国产芯片在超大规模异构集群中的稳定表现。
此次DeepLink多元算力混合推理加速方案的发布,进一步打通了国产异构算力的全链路协同。天数智芯也已完成全面适配,成为混推体系中的核心算力节点。长期以来,国产算力在推理场景中常受限于单一芯片集群的调度能力,不同架构的芯片因标准不一、通信壁垒等问题难以有效协同。天数智芯依托DeepLink四大原创技术底座,实现了多款国产芯片的混合调度与协同推理。在DLInfer推理中间件的支持下,芯片与上层框架实现了无缝对接,显著降低了适配门槛;借助DLSlime高速通信库,芯片间跨架构互联的带宽利用率得到大幅提升,有效保障了异构推理的低时延与高稳定性。
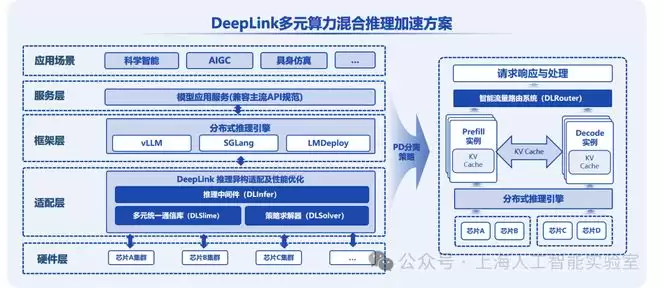
在实际应用中,天数智芯芯片与DeepLink混推方案的深度融合,充分发挥了其在算力密集型和访存密集型任务中的优势。千卡规模集群的实测结果显示,搭载天数智芯芯片的异构集群,在多模态生成、高并发服务等场景中的推理时延优化显著;在科学论文处理等任务中,其吞吐性能也实现大幅提升。与其他国产芯片协同实现了“1+1>2”的效能跃升,不仅验证了天数智芯通用GPU芯片的高性能与广泛兼容性,也彰显了DeepLink生态强大的协同潜力。
作为深耕国产智算芯片的企业,天数智芯坚信开放协同是算力产业发展的必然趋势,而DeepLink体系正是打破生态壁垒、实现软硬件解耦的关键。依托其标准化适配体系,天数智芯仅需一次适配,即可兼容多款主流框架与大模型,大幅降低研发适配成本,加速芯片行业应用落地。同时,DeepLink芯片评测体系为天数智芯芯片的迭代优化提供了科学参考,助力其持续优化性能、提升在异构场景下的适应能力。
展望未来,天数智芯将继续深化与DeepLink生态的合作,持续推动芯片技术创新与生态适配,助力完善多元算力调度能力,进一步盘活国产异构算力资源。公司致力于为“人工智能+”行动提供更高效、灵活、高性价比的算力支撑,为中国新质生产力的发展持续注入强劲的算力动能。




