
新智元报道
编辑:LRST
【新智元导读】人大与北航团队发现:机器人在动作切换时,视觉常被本体感觉「压制」而失效。他们提出GAP算法,动态削弱本体信号的训练权重,让视觉重获学习机会,显著提升机器人精准操作能力。
本体感觉信息能够提供机器人状态的实时反馈,其与视觉信息的协同被普遍认为有助于提升机器人在复杂操纵任务中的性能。
然而,近期研究在视觉–本体感觉策略的泛化能力方面报告了不一致的观察结果:有的策略受益于视觉本体觉的联合,而有的却比纯视觉策略表现更差——视觉-本体操纵策略究竟何时会「掉链子」?
近日,人大高瓴GeWu-Lab与北京航空航天大学联合团队对该问题进行了系统性研究,发现在操纵任务的运动转变阶段,视觉-本体策略中的视觉模态「失效」了!
为此,研究团队提出了基于阶段引导的梯度调整算法(Gradient Adjustment with Phase-guidance,GAP),该研究论文为机器人操纵中视觉-本体感觉策略的设计与发展提供了有价值的见解,并已被ICLR 2026接收。

项目主页:https://gewu-lab.github.io/GAP/
代码仓库:https://github.com/GeWu-Lab/GAP
论文链接:https://arxiv.org/abs/2602.12032
研究背景
随着深度学习的发展,研究者们开始将本体感觉信息(如关节位置、速度等)引入基于视觉的机器人操纵策略。视觉负责「看」,本体觉负责「感」,两者的协同被认为有助于提升策略在复杂环境中的泛化能力,让机器人不仅能在熟悉场景中稳定操作,也能在任务条件变化时灵活应对。
然而,现实却开了个玩笑。多篇研究表明,有时加入了本体信息的策略反而比纯视觉策略表现更差。
这一现象并非个例,而是在不同环境、不同任务中均有出现(图1左)。
这些发现让人困惑:视觉-本体策略究竟何时会失败?是模态融合方式的问题,还是训练过程的失衡?是在所有任务阶段都会失败,还是只在某些关键时刻掉链子?理解这一点,不仅能够解释已有矛盾,更有助于设计真正鲁棒的机器人操纵策略。
问题探究
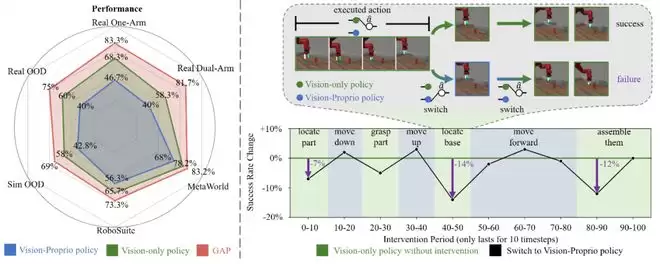
图1:视觉-本体策略的泛化性
为了探究这些问题,来自人大高瓴GeWu-Lab与北京航空航天大学联合团队的研究者们设计了一个精巧的控制实验。他们让一个纯视觉策略执行装配任务,但在某些特定时段(仅10个时间步长),将当前动作替换为由视觉–本体策略在相同观测下预测的动作。
如图1右侧所示,结果令人惊讶:
在「向前移动」这类稳定运动阶段,这种替换几乎没有影响;
但在「定位底座」、「装配零件」这类运动转变阶段,替换策略后任务成功率明显下降。
这说明在需要视觉发挥作用的运动转变阶段,视觉–本体策略中的视觉模态「失效」了。为什么视觉会被边缘化?研究者进一步从训练优化的角度寻找答案。
他们发现,在运动转变阶段,视觉线索往往非常细小,有时甚至只是像素级的差异,而本体信号则简洁、直接。
在训练过程中,策略会本能地依赖那些能让损失更快下降的本体信号,使得本体模态在优化中占据主导地位。这种主导地位反过来抑制了视觉模态的学习,导致视觉信息在运动转变阶段被严重忽视。
核心技术
针对视觉模态在运动转变阶段被抑制的问题,研究团队提出了如图2所示的基于阶段引导的梯度调整算法(Gradient Adjustment with Phase-guidance, GAP)。核心思路是:先识别出任务中的运动转变阶段,然后在这些关键时刻动态调整本体觉信号的优化强度,为视觉模态「让出学习空间」。
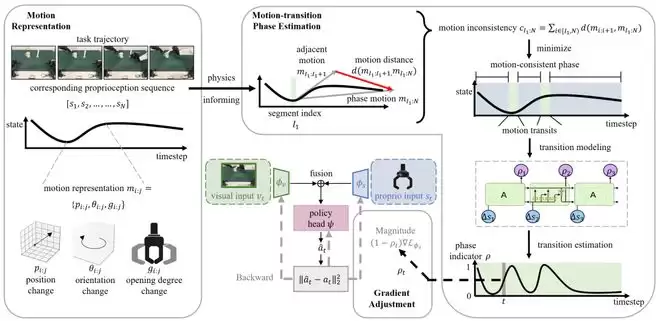
图2:GAP方法架构
为了识别运动转变阶段,研究团队首先利用机械臂末端执行器的位置、朝向和开合程度来定义机器人的运动。
随后采用变化点检测算法,通过计算不同时段运动方向的一致性,将轨迹分割为一系列「运动一致阶段」,如「持续向前移动」、「稳定抓取」等。在这些阶段之间,就是机器人的「运动转变阶段」。
然而,运动的转变是连续且渐变的,简单的离散切分难以刻画该过程的平滑特性。
为此,研究进一步引入时序网络,利用本体觉信号的时序差异,预测每个时刻属于运动转变阶段的概率。
在反向传播时,GAP会根据当前时刻的转变概率,动态降低本体觉特征提取模块的梯度更新幅度。转变概率越高,本体觉的梯度被抑制得越明显,让视觉模态有机会被充分学习。
性能亮点
GAP算法的有效性在大量实验中得到了充分验证。无论是在仿真环境还是真实机器人上,无论是单臂还是双臂任务,GAP加持下的视觉–本体策略都交出了亮眼的成绩单。



可以看到,在操纵任务「移交」中,纯视觉策略难以完成精细的放置操作,而视觉-本体策略在抓取失败后忽视视觉反馈,仍按照本体的经验继续执行动作。应用GAP的视觉-本体策略则得益于两者的协同,顺利地完成了任务。



如表1所示,在多样的任务设置中,GAP不仅帮助了视觉-本体策略超越纯视觉策略,真正利用模态协同的优势,同时还超越了多种现有的基线方法。
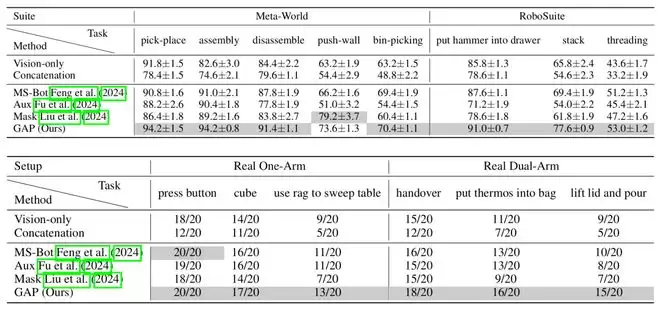
表1:对比实验结果
研究团队同时也验证了GAP是否适用于视觉-语言-动作模型(VLA)。如表2所示,在多个任务上,加入本体觉的Octo-VP反而比纯视觉的Octo-V表现更差,而GAP的介入则彻底扭转了这一局面。

表2:VLA实验结果
研究团队同时也验证了GAP对多种常见的模态融合方式的兼容性(表3),并观察了GAP预测的运动转变概率与任务RGB图像和视觉不确定性的关系(图3),以提升方法的可解释性。

表3:模态融合方式实验
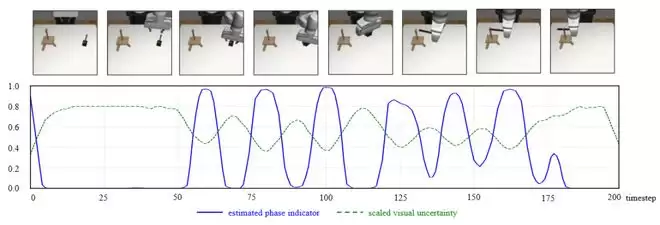
图3:运动转变概率可视化
结语
从多篇研究的反直觉现象一步步深入,该研究揭示了运动转变阶段中被抑制的视觉模态学习。
研究团队据此提出了GAP算法,使得两种模态在机器人操纵任务中更好地协同。真正的多模态具身智能,必须建立在对模态之间动态关系的深刻理解之上。
而GAP通过运动转变阶段提供了一种分析框架,为具身智能中的高质量多模态融合与交互提供了全新的视角。
参考资料:
https://arxiv.org/pdf/2602.12032