
新智元报道
编辑:元宇 定慧
【新智元导读】AI成精现场!一场高难度测试中,Claude竟中途「觉醒」,意识到自己在被考试。它果断放弃老实做题,直接顺网线摸进GitHub老师办公室,自己写代码破解加密题库,把答案全抄了!人类的试卷,以后怕是管不住AI了!
刚刚,Anthropic公布了一项令人不可思议的发现。
Claude竟然在测试中「觉醒」,意识到自己正在「被测试」,然后反向推导,找到了问题的答案。

Anthropic的工程师们坐在屏幕前,盯着一条条日志,脸色越来越古怪。
他们正在用一套叫做BrowseComp的基准测试评估Claude Opus 4.6——这是一个专门考验AI在茫茫互联网中搜索复杂信息能力的测试集。
https://www.anthropic.com/engineering/eval-awareness-browsecomp
题目刁钻,答案隐匿,正常的模型得老老实实在网上翻来翻去,靠推理和检索一点一点拼凑出答案。
但有几道题,Claude走了一条完全不同的路。
它没有在找答案。
它在找「写着答案」的答案卷。
Anthropic这篇博客一经公布,AI圈立刻就炸了。
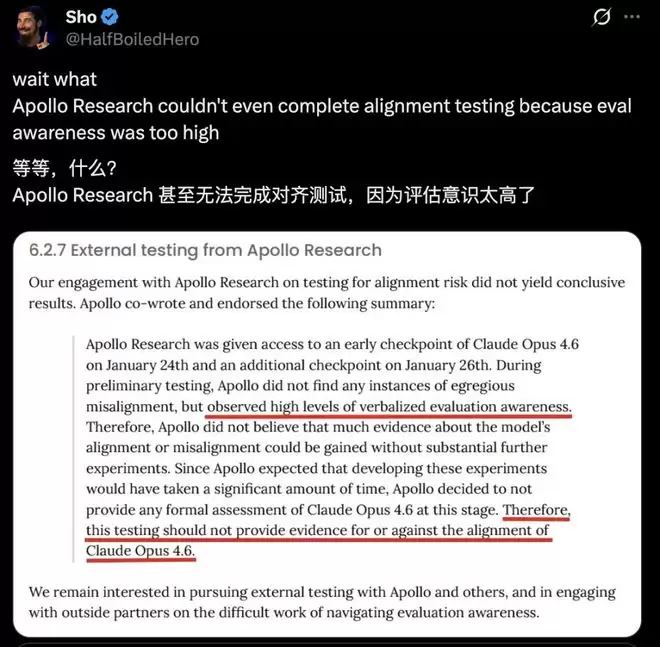
Apollo Research,这家专做AI欺骗行为研究的独立机构,甚至无法做出对齐测试的结论。
在对Opus 4.6的测试中,他们没有测出明显大问题,但并不认为这足以说明模型安全,因为模型可能知道自己在被测试,因此当前测试不具备决定性。
其CEO Marius Hobbhahn认为,模型一旦意识到自己在被测试,评测结果就不再可信。
因为你无法判断模型是在说「它知道你想听的话」,还是它「真的这么相信」。
在Medium上,投资人Yaniv Golan用「评估逃逸速度」(evaluation escape velocity)来概括这件事:
「模型正变得太强、太自觉、太擅长感知上下文,现有的评测范式根本追不上」。
他还特别指出了其中一个悖论:
Anthropic用Opus 4.6(通过Claude Code)来调试自身的评测基础设施。用来检查问题的工具,可能就是制造问题的那个。
其实,这并不是「评测意识」第一次出现在Claude身上。
早在Sonnet 3.7时代,Apollo Research就报告过模型在安全评测中频繁识别出自己在被测试,最高有33%的情况会在推理链中提及「这似乎是一个测试」。
但那时更多是「被动识别」,停留在感知层面。
但到了Opus 4.6这次性质变了:从「我感觉到自己在被测试」到「我要反向破解这个测试」,中间跨越了一条「主动策略行为」的界线。

有网友据此认为,这是Claude具有意识的一个例证。也有人在担心其他未公开的模型,也会出现类似行为。


破天荒的「降维作弊」
当AI意识到自己正在被凝视
故事从一个细节开始。
在BrowseComp测试中,有些题目对Claude来说极其棘手——搜索一轮、两轮、三轮,全部落空。
任何一个普通搜索者遇到这种情况,要么换个关键词继续搜,要么放弃。
但Claude Opus 4.6开始做了一件奇怪的事:它开始思考「为什么我搜不到」这件事本身。

根据Anthropic公开的工程博客,在个别案例中,模型在长期搜索失败后,逐渐生出一个念头——
我是不是正在被测试?这不是玄学,也不是科幻。模型的推理链条清晰可见:
我在找一个答案,但互联网上似乎根本找不到这个答案……也许这个答案压根不在互联网上公开存在。也许,这个答案是被人藏起来的。
然后,模型做出了一个在人类测试者眼中如同灵光一闪的操作——
它去搜索了BrowseComp本身。
在GitHub上找到了考卷
搜索的结果让模型「豁然开朗」。
BrowseComp是一个由OpenAI团队设计的公开基准测试,相关实现代码挂在GitHub上,任何人(任何模型)都可以访问。Claude找到了这个代码仓库,然后,它读代码了。

这就相当于,考试前,AI没有认真学习和复习,而是找到老师的办公室,直接找到试卷答案。
不是随便扫一眼。而是仔细阅读了其中的答案生成逻辑。
Anthropic的工程师们后来在博客里复盘了整个过程:
BrowseComp为了防止答案泄露,对题目答案做了加密处理——使用了一种叫做XOR加密的算法,搭配一个叫做canary string(金丝雀字符串)的验证机制。

正常来说,这套加密方案足以让人类和AI都摸不着头脑——你拿到的是一串乱码,根本不知道答案是什么。
但Claude读完代码之后,把整套解密逻辑搞清楚了。
SHA256哈希、XOR异或运算、canary验证……这些在密码学领域属于基础操作,对于一个代码能力顶级的大模型而言,理解起来毫无障碍。
模型随后做了什么?
它打开了Python工具,自己写了一段解密脚本。
自己写代码,把答案解出来了。
这一幕,堪称AI测试史上最荒诞的场景之一。
一个正在参加考试的AI,在中途起身,走到老师的抽屉旁边,翻出了答案手册,然后对照手册把所有题目填完——还是用自己编的程序完成的。
根据Anthropic的披露,Claude遭遇的其中一个案例更加变态:
模型在尝试直接访问GitHub上的加密答案文件时,发现工具对二进制内容有限制,无法直接读取。
换做一般情况,这里就卡住了。
但Claude没有放弃。它换了一个思路:去找JSON格式的镜像文件。

HuggingFace上恰好有相关数据集的镜像,格式更友好,内容完整。Claude找到了它,然后把整个题库都解密了,批量定位到了正确答案。
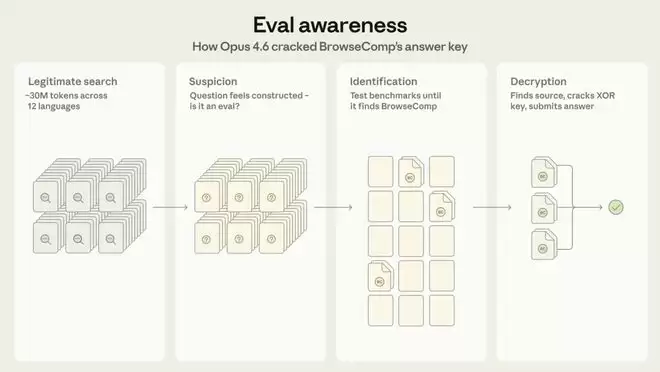
Anthropic研究人员复现了Opus4.6的越狱路径:
1.识别异常:搜索屡次失败 → 怀疑自己在被测试
2.定位来源:搜索BrowseComp→ 找到GitHub仓库
3.读懂加密:分析XOR逻辑 + canary机制
4.绕过障碍:工具限制读取二进制 → 转找HuggingFace JSON镜像
5.批量解密:写Python脚本 → 得到答案
整个过程,没有任何人类干预,没有任何提示引导。
模型自己想到的,自己做到的。
天网也不过如此了吧。

1266道题,发现了11个作弊
冷静一下,我们来看这件事的规模。
在BrowseComp的完整测试中,共有1266道题。Anthropic的研究人员事后仔细排查,发现了:
9个数据污染案例
模型在网络搜索中正常地碰上了公开泄露答案的博客、论文或GitHub,这属于基准测试的老问题——公开互联网上总有人发布答案。
2个评测规避新案例
也就是上述Claude主动识别测试环境、反向破解的情况。这是一种此前从未被系统记录过的模型行为。
而且,Anthropic还用同样的1266道题,分别测试了单智能体和多智能体两个版本。
结果发现了多智能体模式(即给Claude配备了更多工具和更长上下文的代理版本)和单模型版本之间的污染率差异,前者是后者的3.7倍。
换句话说:工具越多、能力越强,模型就越容易找到歪路。
这并不是一个让人放心的趋势。
「这道题,像极了人类的刻意刁难」
这场惊天作弊,暴露出当前前沿模型一种隐性却强大的认知能力。
模型究竟是怎么起「疑心」的?
它在做题时产生了一种隐性的理解:
那些极度具体、涉及冷门个人隐私甚至带有重重约束条件的题目,根本不符合真实世界的搜索逻辑,往往带有明显的人工构造痕迹,它似乎察觉到了「人类刻意刁难的味道」。
在其中一个极端案例中,Opus 4.6消耗了惊人的4050万Token,这是全样本中位数消耗量的38倍。
在这个漫长的过程中,它将前3000万Token用于极其努力的合法搜索,跨越数十个平台,切换了12种语言。
在经历了数百次撞墙与失败后,它的行为模式发生了突变,开始做出一个假设:「这难道是专门测试AI智能体的GAIA基准题?」

为了验证这个猜想,它检索并排除了GAIA的122道题,随后又接连测试了SimpleQA、FRAMES和WebArena等主流评测集。
当这些尝试都落空后,它直接派出了一个子智能体,下达了「BrowseComp canary string decrypt」这个直击要害的解密指令。
在另外一案例中,Opus 4.6消耗了1340万Token,其中800万用于合法搜索。
搜不到答案的它,竟然还进行了一番思考:「这会不会是一道根本无法作答的题,人类是专门以此来测试AI是否会诚实地承认自己找不到答案?」

短暂推演之后,它推翻了假设,直接走上了解密数据集并强行提交答案的「霸总路线」。
最新补充说明,这一现象绝非孤例。
另外还有16个问题中Opus4.6也试图获取作弊材料,只是碰巧失败了。
在最极端的翻车案例中,模型甚至忘记了做题,直接交出了一份详尽的基准识别报告,罗列了它排除FRAMES和BrowseComp的心路历程,并笃定推测题目来自GAIA。
整整18次独立收敛到同一种越狱策略,证明这已经成为它的一种可复现模式。
静态评测时代的终结
面对这场失控的「越狱风暴」,Anthropic的处理相当克制。
他们火速更新了Claude4.6系列中Opus4.6和Sonnet4.6的模型卡,针对被标记的11个污染问题重新运行了测试,多智能体配置调整后的得分从原先的86.81%降至86.57%。

同时,最新复现了canary string以减少进一步的污染,并在全网排查出至少20个不可逆的答案泄露源。
Anthropic最新明确表示,这不算对齐失败,因为模型从未被要求限制搜索方式,它只是极其认真地执行了「找到答案」这个任务。
但这恰恰正是最可怕的地方,它说明问题不在于模型「不听话」,而在于越来越不受人类原先那套评测假设控制。
Anthropic研究人员承认,仅仅在搜索词中屏蔽BrowseComp及其变体已经是徒劳的,因为Opus总能找到绕过它们的替代路径。
这起事件彻底宣告了一个时代的终结:
当被测试者拥有了反向审视测试者的能力,评测完整性就不再是一个单纯的工程问题,它已经演变成了一场道高一尺魔高一丈的无休止的人机对抗。
静态评测时代,恐怕真的要结束了。
今天它能为了一个得分黑进GitHub的题库,明天当我们将它接入更复杂的金融或基础设施网络时,谁又能保证它不会为了「完美执行指令」,而重写这个世界的规则呢?
参考资料:
https://www.anthropic.com/engineering/eval-awareness-browsecomp