
新智元报道
编辑:KingHZ Aeneas
【新智元导读】一夜之间,AI圈再次地震!这次不是DepSeek V4,而是DeepSeek直接换了推理架构。GPU空转的问题,被他们硬生生砍掉了一半。
昨天,DeepSeek-V4要来的消息纷纷扬扬,整个AI圈都被搅动得心绪不宁,隔壁的美国同行们都快崩了。
结果就在昨晚,DeepSeek突然又双叒叕更新了!他们联手北大、清华的团队,发布了针对智能体的推理框架DualPath。
这个框架的核心目标,就是缓解因大规模KV-Cache从外部存储读取而带来的I/O瓶颈问题,避免算力资源因数据加载速度受限而被闲置。

链接:https://arxiv.org/abs/2602.21548
具体来说,此次架构升级引入了「Storage-to-Decode」的第二条加载通路,通过「双路径KV-Cache加载」机制,有效改善了PD分离架构下的读取瓶颈和资源失衡问题。
可以说,这个框架直接剑指多轮AI智能体(agentic)场景下的大语言模型推理性能瓶颈——
以后,DeepSeek+OpenClaw的玩法儿不远了!
还是熟悉的味道,DeepSeek在AI基础设施上的提升一如既往的出色,如今迈入智能体与强化学习时代——
离线推理吞吐量最高提升1.87倍,在线场景下每秒智能体运行次数提升1.96倍。
论文一出,学界直呼:如此极致的算力管理,如此精准的调控,DeepSeek团队是真正的经济学大师!
网友直评:这正是赢得AI大战的关键基础设施思维。
可以说,这篇论文充分体现出DeepSeek的野心——把AI做成像水气电一样的基础设施!
OpenClaw引爆智能体
DeepSeek窥天机
Claude Code\Cowork、OpenClaw等智能体的爆火,毫无争议地点燃了Agent黄金时代的开年热潮!
DeepSeek发现,在智能体推理任务期间,GPU存在严重的利用率不足问题。
一个Agent任务有多长?几十分钟,有时几小时。它要写代码、查文档、 跑测试,再回来改代码。上下文几百万token,每一步都要快。
这就带来了一个巨大的技术债——KVCache(键值缓存)。
KV Cache是什么?一句话,它是AI的草稿纸。
模型每生成一个token,都会把「思考痕迹」存下来;下次继续写,它要翻草稿;草稿越厚,占用显存越多。
为了让AI记得上下文,我们必须把这些庞大的数据一直存在GPU的显存(HBM)里。
然而,HBM供不应求,死死卡住了AI行业的脖子。
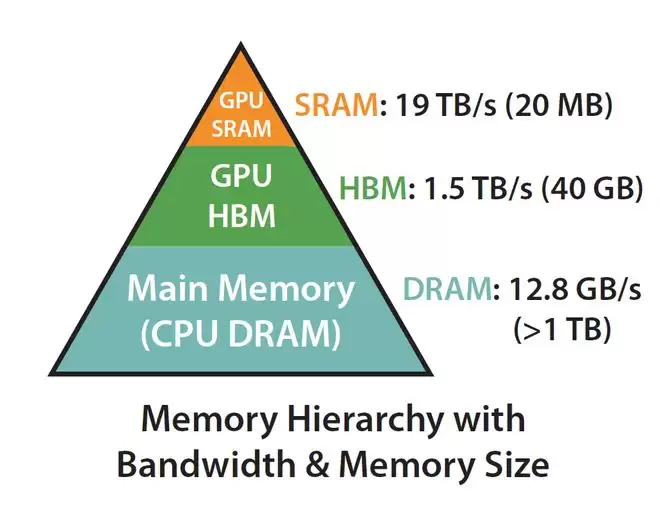
AI模型推理正演变为一场内存竞赛。
因为AI对HBM需求激增,消费级内存被停产,导致在短短几个月内主流的内存DRAM价格涨了7倍!
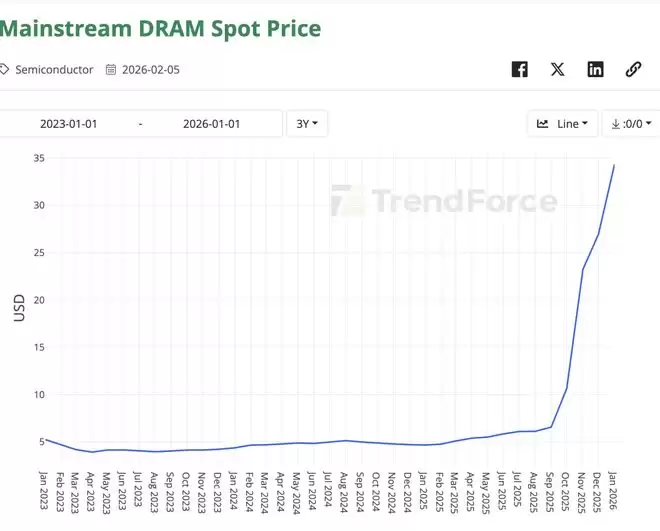
所以,把不需要立刻用到的记忆暂时挪到便宜的SSD或主内存里,下次要用时,再把它搬回来,这成了行业的出路。
矛盾就在这里爆发了:传统的推理架构是串行的。
当AI需要调取旧记忆时,计算单元(Compute Unit)必须停下来,眼巴巴地等着数据通过带宽有限的PCIe总线慢慢爬进显存。
DeepSeek的研究指出,在多轮智能体推理(Agentic Inference)的场景下,GPU竟然有大量时间是在「空转」等待数据!
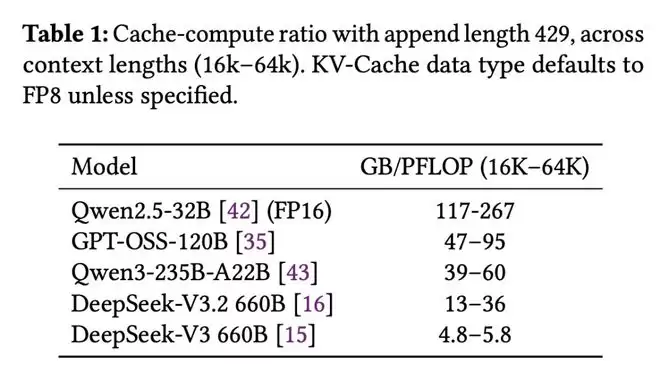
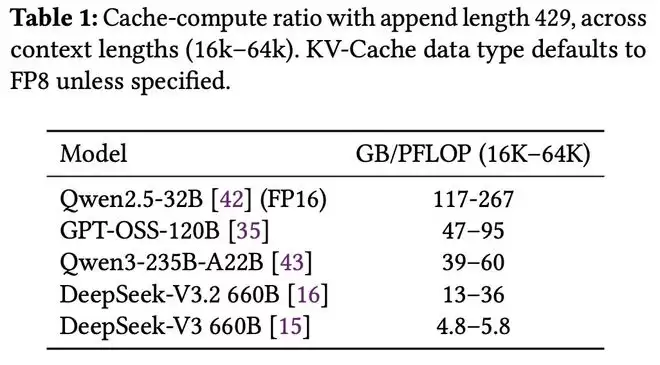
他们发布了一些关于智能体编码的真实世界数据,并定义了一个「缓存-计算比率」指标:该比例取决于模型类型、上下文和追加长度。
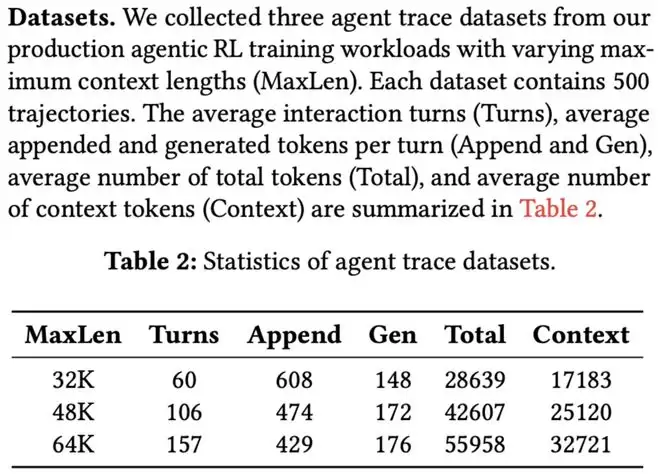
他们从代表性编码任务中收集的轨迹显示,平均交互轮数为157,表明LLMs倾向于进行多轮交互。
平均上下文长度为32.7k,而每次追加长度的平均值仅为429,这意味着KV缓存命中率高达98.7%。
在此场景下,缓存-计算比(定义为KV缓存加载量与所需计算量之比)对于DeepSeek-V3.2约为22GB/PFLOP。
由于每个节点上单块存储网卡的带宽有限,KV缓存加载速度成为了瓶颈。
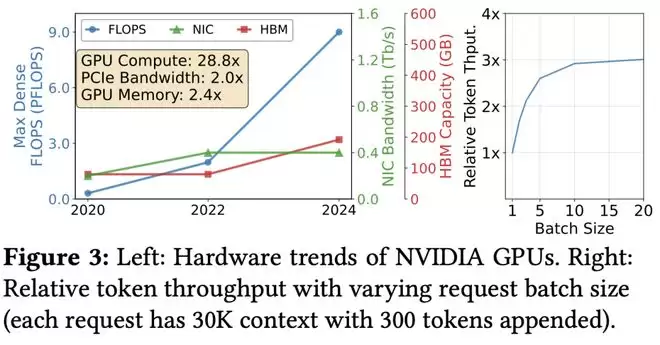
近年来,网络带宽和HBM容量的增长落后于GPU FLOPS的增长,I/O计算比率下降了14.4倍。
此外,较小的HBM容量限制了GPU内核可同时计算的token批次大小,阻碍了张量核心等计算单元被充分利用。
第三,现有的LLM推理系统在不同引擎类型之间表现出严重的存储网络利用率不均衡。
DeepSeek的黑科技:DualPath
DeepSeek的DualPath架构,做了一件听起来简单、实现起来却极具颠覆性的事:它把「思考」和「回忆」这两件事,从串行变成了并行。
在计算机科学中,这被称为「计算与存储访问的解耦」(Decoupling Compute and Memory Access)。
让我们换个通俗的比喻。
传统架构是串行的:先把数据读进显存,读完后,GPU才开始算。像下载电影,必须等100%,才能播放。
而DualPath做了一件事:边下载,边播放。
SemiAnalysis的技术团队成员、高级工程师Jordan Nanos认为:
DeepSeek在DualPath 论文中提出了一个超酷的点子!
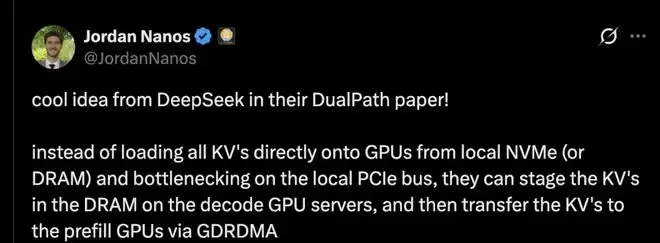
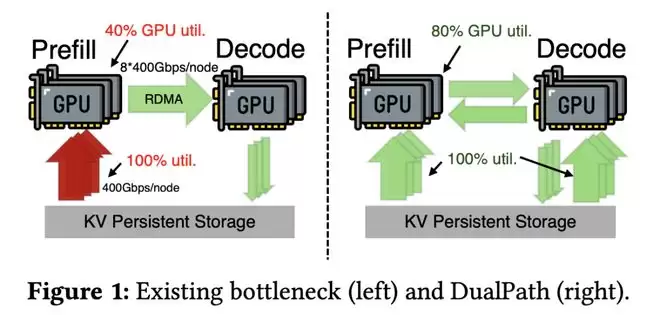
在目前流行的预填充-解码分离系统中,命中token的KV缓存完全由预填充引擎直接从远程存储加载。这种设计将所有存储I/O压力集中在预填充端的网卡上,而解码引擎端的网卡则基本处于空闲状态。
因此,无法充分利用聚合的存储网络带宽。
DeepSeek则另辟蹊径:
与其直接从本地NVMe(或 DRAM)将所有KV加载到 GPU 上并受限于本地PCIe总线带宽,不如先将KV暂存到解码 GPU服务器的DRAM 中,再通过GDRDMA将KV传输至预填充(prefill)GPU。
DeepSeek设计了两条独立的流水线:
存储路径(Access Path):负责疯狂地从SSD/DRAM中搬运KV Cache数据块。
计算路径(Compute Path):负责利用已经搬运好的数据块立刻开始计算。
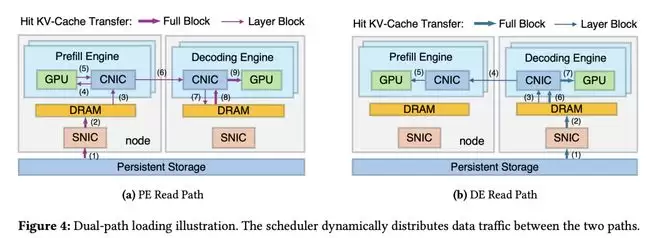
他们将Prefill GPU定义为PE(Prefill Engines,预填充引擎),Decode同理;而SNIC表示存储网卡,CNIC表示计算型网卡
就像你看网剧一样,不需要等电影下完,只要缓冲好前5秒,你就可以开始看了。
后台的下载和前台的播放同时进行,互不干扰。
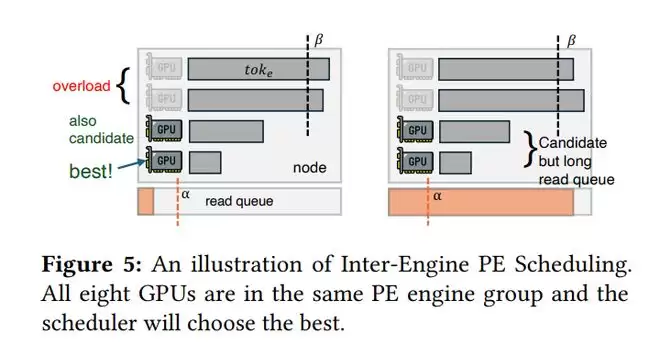
Inter-Engine PE调度示意图。八张GPU均属于同一个PE引擎组,调度器会从中选择最优的一个(或一组)进行调度
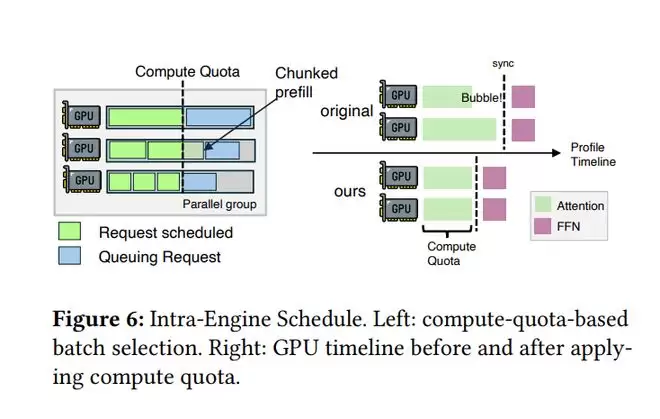
Intra-Engine Schedule示意图。左:基于计算配额的批次选择。右:应用计算配额前后的 GPU 时间线对比
在技术实现上,DualPath利用了Chunk-based Streaming(块式流处理)技术,将庞大的KV Cache切分成一个个小块。
当计算单元在处理「第N块」记忆时,存储单元已经悄悄地把「第N+1块」预加载好了。
DRAM缓冲区(PE缓冲区和DE缓冲区)用于从层块构建完整块
具体而言,DeepSeek的GPU显存只需容纳单层的KV向量即可处理一个请求,内部是这样进行推理的:
你发送一个请求(并缓存命中了一堆token),在推理过程中,当执行LLM的一层时:下一层的KV向量从CPU加载,以滑动窗口的方式从磁盘加载之后那一层的KV。
而且,该架构专为适配其基础设施而设计。
他们分析网络接口卡(NIC)与DRAM带宽,以找出实际可行的Prefill:Decode配置范围。

P表示预填充节点数;D表示解码节点;g表示每个节点的GPU数量;B表示网卡的带宽;s表示每台机器的存储网卡数量;M表示每台机器的DRAM带宽
最佳结果是所有P:D从1:7到7:2。
效果惊人:近2倍效果提升!
在标准的代理推理基准测试中,DualPath将系统的吞吐量直接提升了1.96倍。

请注意,这不是10%或20%的微调,而是近乎200%的性能暴涨。
在半导体日益逼近物理极限的今天,纯软件架构的优化能带来这种幅度的提升,堪称神迹。
这意味着,同样的硬件成本,Agent的反应速度快了一倍;或者说,维持同样的体验,推理成本腰斩。
他们使用一个智能体轨迹数据集,对DeepSeek V3.2的660B和27B版本以及Qwen 2.5-32B进行了评估。
并在其推理框架中对比启用与未启用DualPath的性能,以及与SGLang(带HiCache和Mooncake)的对比。

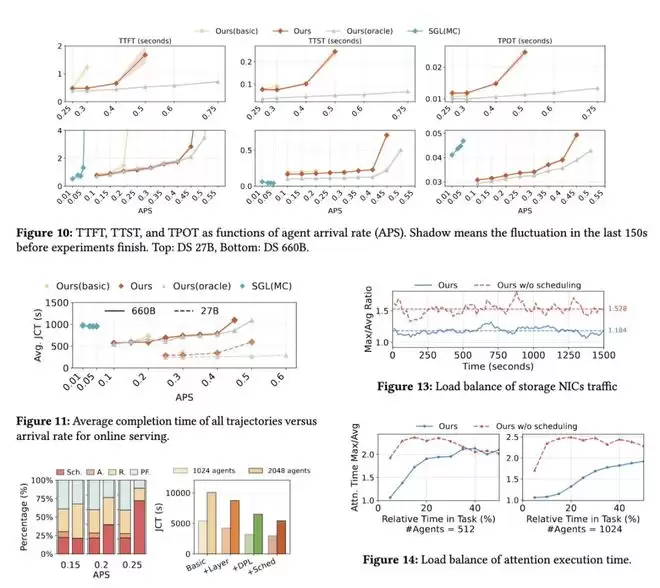
基本上,DualPath能带来近2倍的性能提升;下图灰色条代表理论上限;JCT是离线场景(即强化学习rollout)下的作业完成时间。
结果显示,在在更大的批大小和更长的MAL下,DualPath的优势更加明显。图 7 展示了不同批大小和MAL配置下的JCT。
在DS 660B上,DualPath相比Basic最高可实现1.87×的加速,并且性能接近 Oracle,表明KV-cache的I/O开销基本被消除。
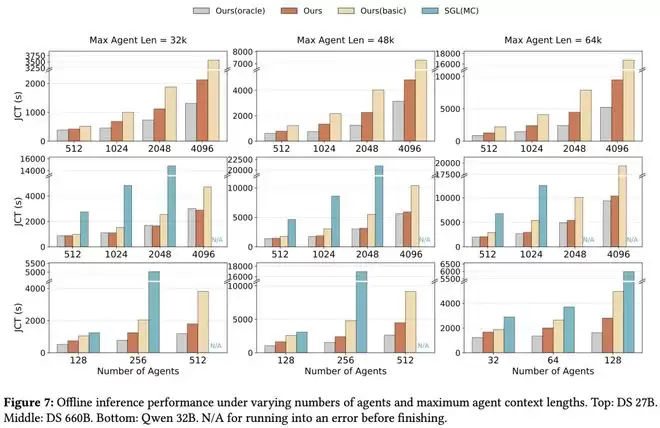
在DS 27B上,DualPath相比Basic最高提升1.78×,但由于1P1D配置下存储带宽受限(见图8),其性能仍比Oracle慢 1.09–1.85×。
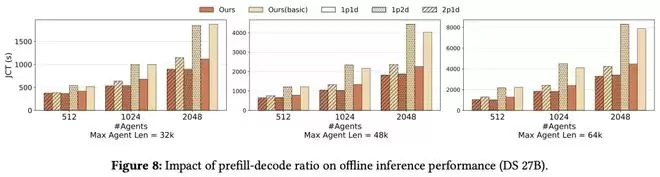
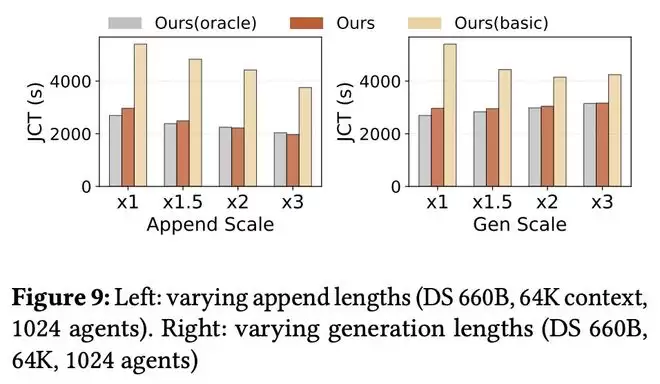
当追加token和生成token较短时,DualPath的优势更加明显。
如图9所示,随着追加长度增加,Basic的性能逐渐接近DualPath和Oracle。
与Basic相比,在不同追加比例下,DualPath实现了1.82–1.99×的加速。
此外,如图8所示,DualPath在所有配置下平均实现1.64倍的加速(最高可达2.46倍)。
这进一步验证了:在智能体场景中,存储带宽是主要瓶颈。
他们还调整了预填充与解码(P:D)的比例,分别为1:2,1:1,2:1,看起来差别并不大,在这三种场景下性能大约提升了2倍。
对于在线服务来说,似乎在更大模型上性能提升更显著:
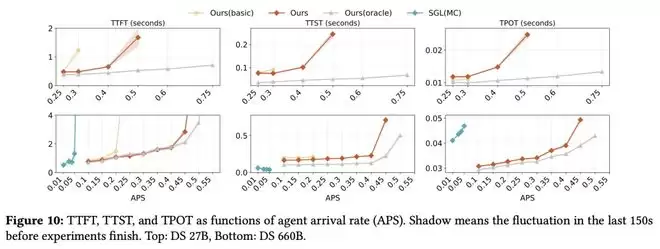
APS表示每秒代理到达率;有SLO限制:TTFT<4秒,TPOT<50毫秒;用InferenceX的术语来说,交互性表示1/TPOT;所以50毫秒的TPOT等于每位用户每秒20个token
团队还进行了消融研究,以将TTFT的改进和JCT归因于所采用的不同技术。
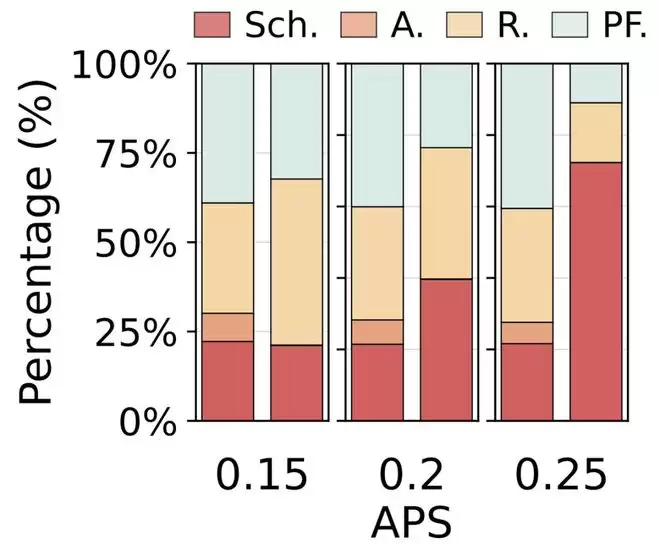
第一张图是在不同APS下的堆叠柱状图,左侧为使用DualPath的情况,右侧为未使用的情况。时间按百分比分配给:
Sch.表示调度
A.表示分配
R.表示读取KV缓存
PF.表示预填充
因此你可以看到分配所花费的时间消失了,prefill所花费的时间减少了,而(相对而言)读取KV和调度所花费的时间增加了
第二张图逐次加入三种技术时,对JCT的对比的总性能提升:
分层预填充(layerwise prefill)占45%
双路径加载贡献了39%
而调度算法负责最后的16%
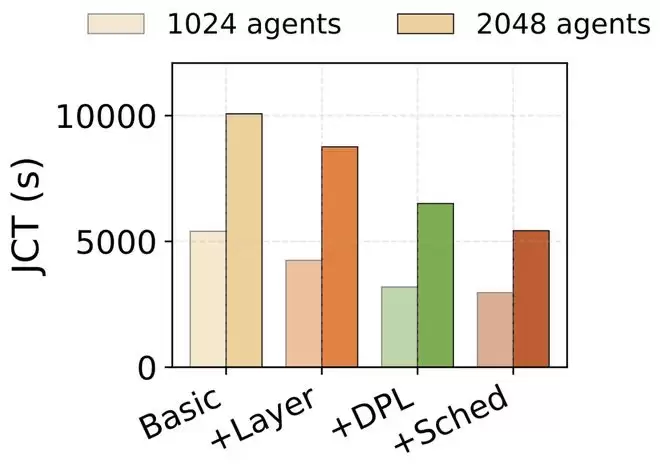
当这三种技术全部应用时,总体性能提升使得平均作业完成时间(JCT)加快了45%。
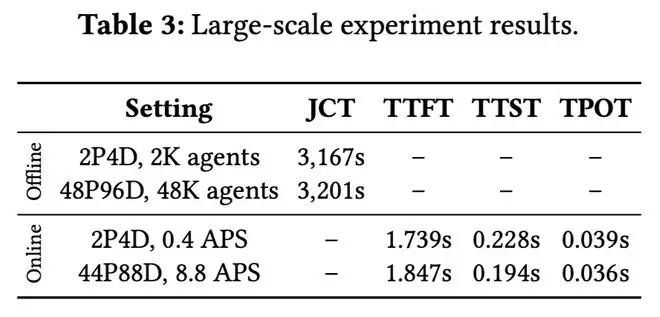
他们最后提到,其系统在由1,152块GPU组成的集群上支持4.8万个并发智能体,配置为48P:96D。
这是从2P:4D上的2000个智能体线性扩展而来的;还测试了44P:88D,也观察到了同样的线性扩展。
一个有意义的限制在于未考虑工具调用的延迟。
如果智能体在工具调用期间处于空闲状态,理论上你可以提高APS(并发数)
但这也会导致工作集(KV缓存的大小)呈平方级增长,由于命中率降低,进一步加大了对DRAM和存储的压力
也让人质疑他们早前提出的缓存-计算比率,很可能会提高GB:PFLOPs表中的GB数值(再次附上截图)
从「算力为王」到「带宽决胜」
DualPath的诞生,不仅仅是一个技术优化,它是一个信号。它宣告了Pre-filling(预填充)时代的终结,和Agentic Serving(智能体式服务)时代的正式确立。
在过去,我们迷信算力。仿佛只要堆足够多的H100、B200,AI就会无限变强。
但DeepSeek用DualPath狠狠地打醒了行业:当参数量不再是瓶颈,IO(输入输出)才是阿喀琉斯之踵。
实际上,DeepSeek就是在构建AGI的高效「海马体」。
通过彻底榨干PCIe 6.0/7.0的带宽,通过极致的软硬件协同,DeepSeek正在把AI从「在线计算」的束缚中解放出来。
如今,我们离真正的AGI,又近了一步。
参考资料:
https://arxiv.org/pdf/2602.21548