2月22日消息,春节期间,国产AI大模型轮番登场。除了DeepSeek V4保持低调,几家主流模型纷纷亮相,其中智谱的GLM-5堪称热度最高的选手之一。
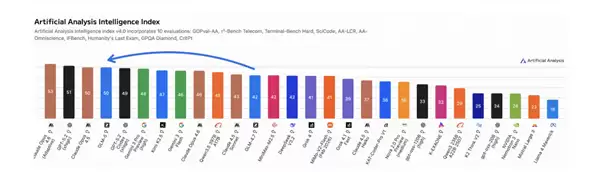
从官方介绍来看,GLM-5的核心亮点在于大幅提升了编程与智能体能力。其参数规模达到了7440亿,是上一代GLM-4.X的2倍左右,性能提升相当显著。
此前已有海外AI博主测试过其代理编程能力,结果显示其编程能力位居全球第一,综合编程实力位列世界第三,仅次于Opus 4.6及Gemini 3 Pro,但成功超越了Opus 4.5。
发布后,由于模型极受欢迎,GLM-5的需求量暴增,甚至一度导致算力供应紧张,部分用户体验有所下滑。为此,智谱官方发布了致歉信,并给出了相应的补偿方案,其受欢迎程度可见一斑。

今天,智谱还正式发布了GLM-5大模型的技术报告,特别提到性能提升主要源于四大技术创新,具体如下:
1、引入DSA稀疏注意力机制(DeepSeek Sparse Attention, DSA),极大降低了训练与推理成本。
此前的GLM-4.5依赖标准MoE架构提升效率,而DSA机制则使GLM-5能够根据Token的重要性动态分配注意力资源。在不损耗长上下文理解和推理深度的前提下,算力开销得以大幅削减。
得益于此,智谱将模型参数规模扩展至744B,同时将训练Token规模提升至28.5T。
2、构建全新的异步RL基础设施
基于GLM-4.5时期 slime 框架“训练与推理解耦”的设计,智谱的新基建进一步实现了“生成与训练”的深度解耦,将GPU利用率推向极致。该系统支持模型开展大规模的智能体轨迹探索,大幅缓解了以往拖慢迭代速度的同步瓶颈,让RL后训练流程的效率实现了质的飞跃。
3、提出全新的异步Agent RL算法
该算法旨在全面提升模型的自主决策质量。GLM-4.5曾依靠迭代自蒸馏和结果监督来训练Agent;而在GLM-5中,研发的异步算法使模型能够从多样化的长周期交互中持续学习。
这一算法针对动态环境下的规划与自我纠错能力进行了深度优化,这也正是GLM-5能够在真实编程场景中表现卓越的底层逻辑。
4、全面拥抱国产算力生态
从模型发布伊始,GLM-5就原生适配了中国GPU生态。智谱已完成从底层内核到上层推理框架的深度优化,全面兼容七大主流国产芯片平台:华为昇腾、摩尔线程、海光、寒武纪、昆仑芯、天数智芯与燧原。
据介绍,GLM-5在单台国产算力节点上的性能表现,已足可媲美由两台国际主流GPU组成的计算集群。不仅如此,在长序列处理场景下,其部署成本更是大幅降低了50%。