
推理能力翻倍提升,价格却保持不变——这一次,Google正在重新定义AI领域的竞争规则。
作者|桦林舞王
编辑|靖宇
马年“AI春运”赛程过半,OpenAI、Anthropic、阿里等玩家纷纷亮出新招,现在,Google也正式加入了战局!
当地时间2月19日,Google正式揭晓了Gemini 3.1 Pro最新模型。
这次Google没有玩任何花哨的概念,而是直接用数据说话。
在公认的推理基准测试ARC-AGI-2中,Gemini 3.1 Pro获得了77.1%的优异成绩。这意味着什么?它的前辈Gemini 3 Pro仅有31.1%,就连专门用于“深度思考”的Gemini 3 Deep Think也仅有45.1%。
从31.1%跃升至77.1%,这并非渐进式改进,而是推理能力的质的飞跃。
更让人意外的是,Google选择了一个近乎“反商业”的策略:维持原价。Gemini 3.1 Pro保持了与Gemini 3 Pro完全相同的定价结构——相当于为所有API用户免费升级了推理能力。
JetBrains的AI总监Vladislav Tankov在测试后坦言:相比之前版本有15%的质量提升,“更强大、更迅速……且效率更高,所需的输出tokens更少”。
这种“暴力美学”式的升级,让我想起了早期Google的作风——用技术说话,用实力碾压。
这次,Google能凭借Gemini 3.1 Pro,继续惊艳世界吗?
01
“.1”版本号的野心
细心的人可能注意到,这是Google首次使用“.1”这样的增量版本号。
在软件行业,“.1”通常意味着重要的功能更新,但并非颠覆性的架构重构。Google选择3.1而非4.0,实际上是在向市场传递一个信号:
我们还有更大的招数没出。
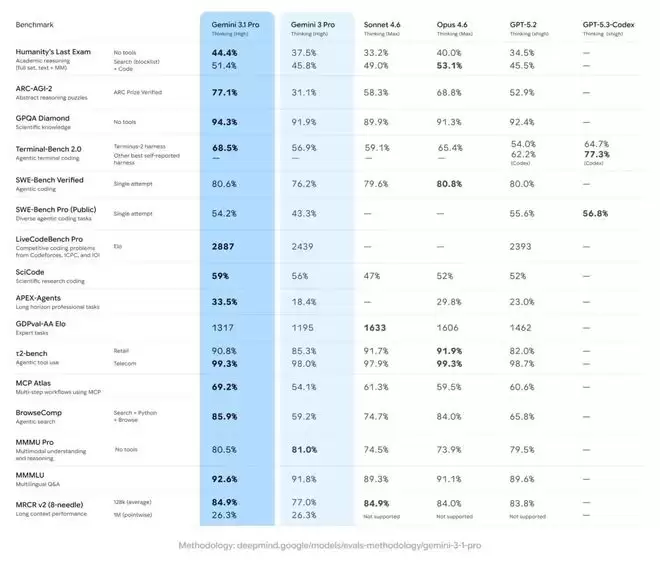
Gemini 3.1 Pro与自家和友商模型数据对比|图片
从企业客户的反馈来看,这个“.1”的威力确实不容小觑。
Databricks的CTO报告称,新模型在OfficeQA基准上取得了“同类最佳的结果”。Cartwheel的联合创始人更是直接指出,模型对3D变换的理解有了“显著提升”,解决了3D动画管道中长期存在的旋转顺序问题。
Box AI的企业评估数据更加直观:在医疗和生命科学领域,准确性从47%跃升至67%;在法律任务中,准确性从57%提升到74%。
这些不是实验室里的跑分游戏,而是真实商业场景中的能力验证。
02
AI竞争进入“推理纪元”
如果说过去一年的AI竞争是“谁更聪明”的比拼,那么Gemini 3.1 Pro的发布策略,可能正在把游戏规则拉向“谁更划算”。
在大多数基准测试中,Gemini 3.1 Pro都领先于Anthropic的Opus 4.6和OpenAI的GPT-5.2,但价格却是Opus 4.6的一半。这种性价比优势,对于大量使用AI API的企业客户来说,吸引力是致命的。
一位开发者在社区分享了一个令人印象深刻的案例:他用单个提示让Gemini 3.1 Pro构建了一个功能完整的Windows 11风格网络操作系统,包括文本编辑器、Python终端、代码编辑器、文件管理器、绘图应用和可玩游戏。
这种“一个提示解决复杂问题”的能力,正是推理模型的核心价值所在。
当然,Gemini 3.1 Pro也并非完美无缺。在GDPval-AA这个衡量真实世界经济任务的基准测试中,它的得分为1317分,明显低于Anthropic Sonnet 4.6的1633分。这提醒我们,即使是最先进的AI模型,在处理复杂现实问题时仍有局限性。

Gemini 3.1 Pro在设计上也更有“品味”了|图片
VentureBeat的分析师一针见血地指出:“Google加倍投入核心推理和ARC-AGI-2等专业基准,表明AI竞赛的下一阶段,将由能够思考问题的模型赢得,而不仅仅是预测下一个词。”
这句话道出了当前AI竞争的本质变化。
过去两年,我们见证了ChatGPT从“会聊天的AI”进化为“会推理的AI”,见证了Claude从“安全的助手”变成“深度思考的伙伴”。
现在,Google用Gemini 3.1 Pro告诉市场:推理能力,才是AI模型的核心护城河。
从技术角度看,Gemini 3.1 Pro与Google的新型代理开发平台Antigravity深度集成,开发者可以切换不同的“推理预算”,在速度和准确性之间找到平衡。这种灵活性,可能是未来AI应用开发的新范式。
从商业角度看,Google选择“性能翻倍、价格不变”的策略,实际上是在用规模经济对抗技术溢价。这背后的逻辑很简单:我有足够的资源和效率优势,可以用更低的成本提供更好的服务。
这场AI军备竞赛,正在从“技术炫技”回归到“商业本质”。
Gemini 3.1 Pro的发布,让我想起了那个曾经“不作恶”的Google——用技术改变世界,用创新降低门槛。虽然这家公司在过去几年经历了不少争议,但在AI这个关键战场上,它似乎正在找回自己最擅长的节奏。
当然,OpenAI和Anthropic不会坐以待毙。这场推理能力的军备竞赛才刚刚开始。
*头图




