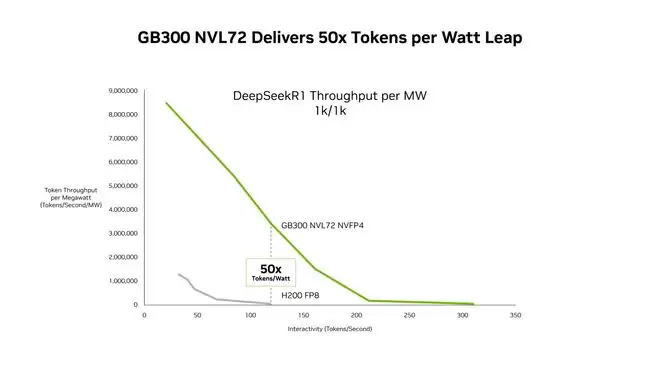
IT之家2月18日援引英伟达最新动态,该公司于2月16日通过官方博客宣布,其Blackwell Ultra AI架构(GB300 NVL72)在能效与成本控制方面实现重大突破。根据DeepSeek-R1模型测试结果显示,相较于前代Hopper GPU架构,新一代架构的每兆瓦吞吐量提升达50倍,处理百万tokens的成本降至原先的三十五分之一的水平。
值得注意的是,英伟达在公告中还预告了下一代Rubin平台的技术规划,预计其每兆瓦吞吐量将比Blackwell架构再提升10倍,持续推动AI基础设施的迭代升级。
IT之家技术解读:每兆瓦吞吐量(Tokens / Watt)是衡量AI芯片能效表现的核心指标,具体指消耗每瓦特电力所能处理的Token数量。该数值越高,代表芯片能效表现越优异,实际运营成本也相应降低。
英伟达在技术文档中强调,实现性能飞跃的关键在于架构层面的全面升级。Blackwell Ultra通过NVLink高速互联技术,将72个GPU连接为统一的计算单元,互联带宽高达130TB/s,远超Hopper架构时代的8芯片设计方案。此外,全新的NVFP4精度格式与极致协同设计架构相结合,进一步巩固了其在计算吞吐性能方面的领先地位。
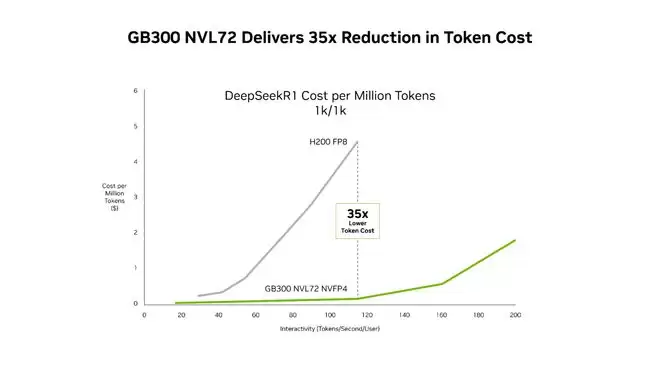
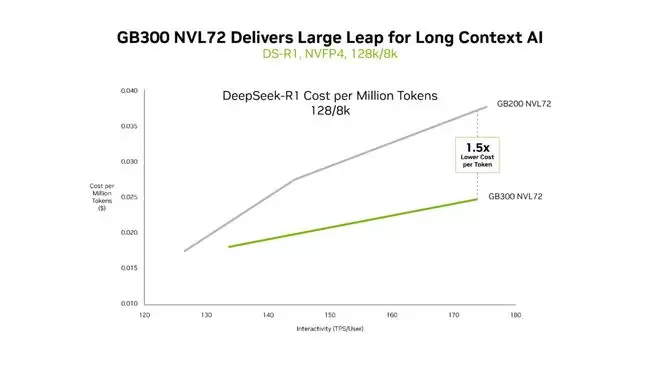
在AI推理成本方面,新平台相较Hopper架构实现显著优化,处理百万Token的成本降至原先的三十五分之一。即便是与同代Blackwell架构的GB200相比,GB300在长上下文任务中的Token成本也降低至1.5分之一,注意力机制处理速度实现倍数级提升,完美适配代码库维护等高负载应用场景。
OpenRouter发布的《推理状态报告》指出,与软件编程相关的AI查询量在过去一年中呈现爆发式增长,占比从11%攀升至约50%。这类应用通常要求AI代理在多步工作流程中保持实时响应,并具备跨代码库推理的长上下文处理能力。
为应对这一技术挑战,英伟达通过TensorRT-LLM、Dynamo等开发团队的持续优化,进一步提升了混合专家模型(MoE)的推理吞吐量。以TensorRT-LLM库的改进为例,使得GB200在低延迟工作负载上的性能在短短四个月内提升了5倍。




