(文/陈济深 编辑/张广凯)
长期以来,深度思考模型一直面临一个尴尬的“不可能三角”:想要推理逻辑严密,就得忍受龟速的解码速度和爆炸式的显存开销。
为了绕开这个难题,目前业界主流路径多采用 MoE(混合专家模型)架构,通过只激活部分参数来节省算力,诸多头部模型如以DeepSeek、Kimi、MiniMax均采用了这种架构。
如今,这个行业魔咒被蚂蚁集团找到了解法。
2月13日,蚂蚁集团正式开源了全球首个基于混合线性架构的万亿参数思考模型Ring-2.5-1T。该模型同时做到了三件过去被认为难以兼得的事:推理速度快、深度思考强、长程任务执行能力突出。
在评测中,Ring-2.5-1T在数学竞赛中拿到IMO金牌级别的35分(满分42),在CMO拿到105分远超国家集训队分数线,同时在32K以上长文本生成场景中将访存规模降至上一代的1/10,生成吞吐量提升超3倍。使得其在搜索、编码这些复杂任务上都能独当一面。
如何又快又好?
Ring-2.5-1T的速度优势来自其底层架构的根本性创新。它基于Ling 2.5架构,采用了混合线性注意力机制——具体来说,是以1:7的比例混搭MLA(多头潜在注意力)和Lightning Linear Attention两种注意力模块。
这一设计源自蚂蚁此前发布的Ring-flash-linear-2.0技术路线。
研发团队通过增量训练的方式,将原有架构中的GQA(分组查询注意力)层分别转化为Lightning Linear Attention和MLA:前者在长程推理中负责拉满吞吐量,后者则极致压缩KV Cache。为防止模型表达能力因架构改造而受损,团队还特别适配了QK Norm和Partial RoPE等特性。
经过这番改造,Ring-2.5-1T的激活参数量从上一代的51B提升至63B,但凭借线性时间复杂度的特性,其推理效率反而大幅提升。
与同为1T参数量级但仅有32B激活参数的Kimi K2架构相比,Ling 2.5架构在长序列推理任务中的吞吐优势十分显著,且随着生成长度增加,效率优势持续扩大。
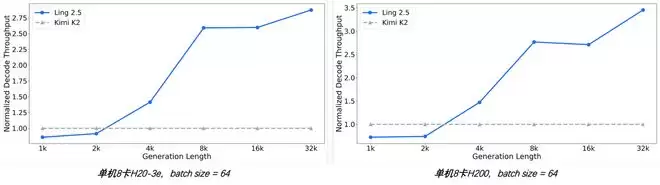
这意味着长程推理不再是“烧钱又烧显卡”的重资产操作,而变成了一种可以规模化部署的轻量级方案。从“做题家”到“实战派”跑得快只是一面,逻辑够不够硬才是深度思考模型的真正门槛。在思维训练层面,Ring-2.5-1T在RLVR(基于可验证奖励的强化学习)基础上引入了密集奖励机制。不同于只看最终答案对不对的传统方式,这套机制会逐步考察推理过程中每一个环节的严谨性,让模型在逻辑漏洞和高阶证明技巧上都获得了显著提升。
在此基础上,团队还引入了大规模全异步Agentic RL训练,大幅增强了模型在搜索、编码等长链条任务上的自主执行能力。这让Ring-2.5-1T从单纯的数学证明高手,进化为能在复杂实战场景中独当一面的智能体。
蚂蚁研究团队将Ring-2.5-1T与开源模型DeepSeek-v3.2-Thinking、Kimi-K2.5-Thinking以及闭源API GPT-5.2-thinking-high、Gemini-3.0-Pro-preview-thinking-high、Claude-Opus-4.5-Extended-Thinking等进行了对比。
结果显示,Ring-2.5-1T在IMOAnswerBench、AIME 26、HMMT 25、LiveCodeBench等高难度推理任务,以及Gaia2-search、Tau2-bench、SWE-Bench Verified等长时任务执行基准上,均达到了开源最优水平。在Heavy Thinking模式下,Ring-2.5-1T更是在多项数学竞赛和代码生成基准中超越了所有对比模型,包括上述闭源API。
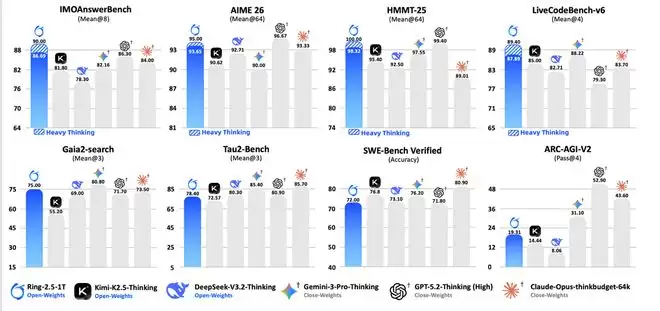
尤其值得一提的是,在IMO 2025(满分42分)中Ring-2.5-1T拿到35分达到金牌水平,在CMO 2025(满分126分)中获得105分,大幅超过金牌线78分和国家集训队选拔线87分。与上一代Ring-1T相比,新模型在推理逻辑的严谨性、高级证明技巧的运用和答案表述的完整性上都有明显进步。生态适配与开源落地Ring-2.5-1T已经适配Claude Code和OpenClaw等主流智能体框架,支持多步规划与工具调用。模型权重与推理代码已在Hugging Face、ModelScope等平台同步开放,最新Chat体验页和API服务也将在近期上线。
除Ring-2.5-1T外,蚂蚁集团同期还发布了扩散语言模型LLaDA2.1和全模态大模型Ming-flash-omni-2.0。前者采用非自回归并行解码技术,推理速度达到535 tokens/s,在HumanEval+编程任务上甚至达到892 tokens/s,还具备独特的Token编辑与逆向推理能力;后者则在视觉、音频、文本的统一表征与生成上实现了突破,打通了多模态的感知与创作能力,支持实时感官交互。
蚂蚁inclusionAI团队的目标很明确:将这些能力做成可复用的底座方案,为开发者提供统一的能力入口。据悉,后续团队还将继续在视频时序理解、复杂图像编辑和长音频实时生成等方向持续发力,推动全模态技术的规模化落地。
随着AI大模型应用从短对话向长文档处理、跨文件代码理解、复杂任务规划等场景延伸,深度思考模型面临的效率瓶颈愈发突出。Ring-2.5-1T通过底层架构的重构,给出了一条兼顾性能、成本与扩展性的技术路径。
当“又快又好又深”不再是不可能三角,深度思考模型的应用边界也将随之打开。




