这项由上海交通大学EPIC实验室领导,联合阿里巴巴集团钉钉团队、威斯康星大学麦迪逊分校、伊利诺伊大学厄巴纳-香槟分校和Mila-魁北克人工智能研究所共同完成的研究,于2026年发表在预印本平台上。有兴趣深入了解的读者可以通过论文编号arXiv:2602.05400v2查询完整论文。
想象一下教小孩学说话的过程:你不会把所有的书籍都堆在孩子面前让他随便看,而是会精心挑选那些适合他当前水平、最有帮助的读物。这正是现在AI大语言模型训练面临的核心挑战——如何在海量的文本数据中选出最有价值的"食材"来喂养AI。
当前的AI训练就像是开设一家高级餐厅,但食材选择出现了问题。传统的做法要么是厨师提前把所有食材分好类(静态选择),要么是在烹饪过程中凭感觉随意抓取(动态选择)。然而,这两种方法都忽略了一个关键问题:不同的烹饪方法需要不同的食材处理方式,而现有的食材选择完全没有考虑到具体的烹饪工具和技巧。
研究团队发现,目前主流的AI训练优化器(相当于不同的烹饪方法)会对原始数据进行复杂的加工处理,就像用不同的刀法、火候来处理同样的食材。但现有的数据选择方法都假设所有食材都用同样的处理方式,这就像用适合煎蛋的标准去选择做红烧肉的食材一样荒谬。
为了解决这个问题,研究团队开发了一套名为OPUS的全新数据选择框架。这个名字代表"优化器诱导的投影实用性选择",听起来很复杂,但本质就是让数据选择过程充分考虑具体优化器的特性,就像为不同的烹饪方法量身定制食材选择标准。
一、传统方法的局限:为什么现有的数据选择像盲人摸象
在深入了解OPUS之前,我们先来看看现有方法的问题。目前AI训练中的数据选择主要有两大类:静态选择和动态选择。
静态选择就像在超市购物时,提前根据食材的外观、产地、价格等固定标准选好所有食材,然后回家无论做什么菜都用这些食材。比如FineWeb-Edu分类器会根据文本的"教育价值"给每个文档打分,分数高的就选中。这种方法的问题在于,它假设一个文档的价值是恒定不变的,完全不考虑AI模型在训练过程中的学习状态变化。
动态选择则更像是一边做菜一边挑选食材,会根据当前的烹饪状态来调整食材选择。比如GREATS方法会实时计算每个数据样本的"梯度"(可以理解为学习信号的强度),然后选择那些能产生最强学习信号的数据。
但这两种方法都有一个致命缺陷:它们都没有考虑到具体的"烹饪工具"特性。在AI训练中,优化器就相当于烹饪工具,不同的优化器会以完全不同的方式处理数据。就像同样的牛肉,用平底锅煎和用高压锅炖需要完全不同的切法和调料搭配。
现代AI训练主要使用两种先进的优化器:AdamW和Muon。AdamW就像一个智能的多功能厨师机,会根据每种食材的特性自动调整处理方式;Muon则更像一个专业的日式料理师傅,特别擅长精细的刀工处理。但现有的数据选择方法都假设使用的是最简单的菜刀(SGD优化器),这就导致了严重的不匹配。
研究团队通过大量实验发现,这种不匹配会导致训练效率大幅下降。就像用适合简单炒菜的食材搭配去做复杂的法式料理,结果自然不会理想。更糟糕的是,随着AI模型规模越来越大,训练成本越来越高,这种效率损失变得越来越难以承受。
二、OPUS的核心创新:让数据选择与优化器完美配合
OPUS的核心理念可以用一个简单的比喻来理解:它就像一个既懂食材又精通各种烹饪技法的顶级大厨,能够根据具体的烹饪方法来精确选择和处理食材。
传统方法在选择数据时,只看数据本身的"营养价值"(梯度大小),却忽略了不同优化器会如何"消化"这些数据。OPUS则不同,它会模拟每个优化器的具体工作方式,预测每个数据样本经过特定优化器处理后的实际效果,然后据此来选择数据。
具体来说,OPUS的工作流程就像一个精密的餐厅运营系统。首先,它会分析当前使用的"烹饪设备"(优化器)的特性,了解这种设备是如何处理原材料的。比如,AdamW优化器会对每个参数进行个性化的自适应调整,就像智能烤箱会根据不同食材的特性自动调节温度和时间。
然后,OPUS会构建一个"品质检验标准"(代理方向),这个标准来源于高质量的基准数据集。这就像米其林餐厅会有一套严格的出品标准,每道菜都要符合这个标准才能上桌。OPUS通过一种叫做"基准代理"(BENCH-PROXY)的技术,从训练数据中找出那些与高质量基准最相似的样本作为参考标准。
接下来是OPUS最精妙的部分:对每个候选数据样本,它会预测这个样本经过特定优化器处理后,能在多大程度上帮助模型朝着"品质标准"的方向改进。这个预测过程考虑了优化器的所有特性,包括它如何调整学习率、如何处理历史信息、如何应对不同类型的参数等等。
为了提高计算效率,OPUS还采用了两项关键技术。第一项叫做"幽灵技术"(Ghost Technique),它能够在不完全计算每个样本梯度的情况下获得足够的信息进行选择,就像经验丰富的厨师能够通过观察食材的外观、闻味道就知道它的品质,而不需要真正烹饪一遍。
第二项技术叫做CountSketch投影,它将高维的梯度信息压缩到低维空间进行处理,大大降低了计算成本。这就像用快速检测仪器替代复杂的化学分析,既保证了准确性又提高了效率。
三、让选择更加多样化:波尔兹曼采样的智慧
在数据选择中,还有一个容易被忽视但十分重要的问题:如何在选择高质量数据的同时保持多样性。这就像办一场成功的宴会,不能只准备一种再好吃的菜,而是要有合理的搭配。
传统的贪婪选择方法总是挑选当前看起来最好的数据,这就像只挑选最新鲜的鱼来做菜,却忽略了整桌菜的平衡。这种做法的问题在于,它可能会过度集中在某些类型的数据上,导致模型的学习出现偏向。
OPUS采用了一种更智慧的选择策略:波尔兹曼采样。这种方法的灵感来自物理学中的热力学原理,它不是简单地选择分数最高的数据,而是根据数据的质量分数给每个样本分配一个被选中的概率。
这种方法的巧妙之处在于,质量高的数据仍然有更大的被选中概率,但质量稍低但可能带来不同视角的数据也有机会被选中。这就像一个经验丰富的厨师,在选择主菜食材时会偏向最优质的,但同时也会选择一些能够提供不同口味层次的辅助食材。
为了进一步避免选择的同质化,OPUS还设计了一个"冗余惩罚"机制。当系统发现某个数据样本与已经选择的数据过于相似时,会降低其被选中的概率。这确保了选择出的数据集既有高质量,又有足够的多样性。
四、实验验证:在多个场景下的出色表现
研究团队在多个不同的场景下测试了OPUS的性能,结果令人印象深刻。这些测试就像在不同类型的餐厅中验证一套新的食材选择标准是否真的有效。
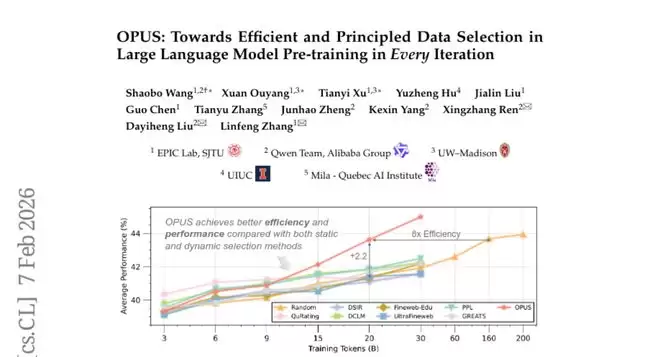
在从头开始训练GPT-2模型的实验中,OPUS展现出了显著的优势。研究团队使用了FineWeb和FineWeb-Edu两个大规模数据集,这相当于在两种不同质量的食材市场中测试采购策略。结果显示,OPUS在30B个训练token的预算下,平均比随机选择提高了2.2%的准确率,同时实现了8倍的计算效率提升。
更令人惊讶的是,OPUS训练的模型甚至能够超越使用全部200B token训练的传统方法。这就像用精心挑选的食材做出的菜肴,品质超过了使用大量普通食材制作的料理。
在一个特别严苛的测试中,研究团队让OPUS从相对低质量的数据池中选择样本,而让其他基线方法使用高质量数据。即使在这种不公平的对比中,OPUS仍然取得了最佳的性能。这证明了好的选择策略确实能够化腐朽为神奇,让普通食材发挥出超常的价值。
除了从头训练,研究团队还在继续预训练场景中测试了OPUS。他们使用Qwen3-8B-Base模型在SciencePedia科学数据上进行专业化训练。结果显示,OPUS仅使用0.5B个token就达到了传统方法使用3B token的效果,数据效率提升了6倍。
这个结果特别重要,因为它表明OPUS不仅在通用训练中有效,在专业领域的知识注入中也同样出色。这就像一套好的食材选择标准,不仅适用于家常菜,在制作专业料理时也能发挥重要作用。
五、技术细节:如何让复杂的算法变得可行
OPUS的成功不仅在于理念的创新,更在于技术实现上的巧思。研究团队面临的最大挑战是如何在保证选择质量的同时控制计算成本。
传统的影响函数方法虽然理论上很完美,但计算成本高得离谱,就像要为每道菜都配备专门的营养师进行详细分析。OPUS通过几项关键的技术创新解决了这个问题。
首先是对不同优化器的数学建模。研究团队深入分析了AdamW和Muon两种主流优化器的数学原理,推导出了它们的线性化近似公式。这就像研究不同烹饪方法的科学原理,理解它们是如何改变食材的分子结构的。
对于AdamW优化器,研究团队发现它本质上对每个参数应用了不同的缩放因子,这些因子基于参数的历史梯度统计信息。对于Muon优化器,情况更加复杂,它使用了矩阵正交化技术,相当于对参数进行了更精细的几何变换。
为了高效地处理这些复杂的变换,OPUS采用了几项巧妙的近似方法。比如在处理验证梯度时,它使用了一阶泰勒展开来避免昂贵的二阶计算。在处理Hessian矩阵时,它使用了等向性近似来大幅简化计算。
CountSketch投影技术是另一个关键创新。这种技术能够将高维向量压缩到低维空间,同时保持内积运算的无偏估计。研究团队将sketch维度设置为8192,对于参数量达到千万级的模型来说,这相当于实现了1000多倍的压缩比。
六、效率分析:少量开销换来巨大提升
任何新技术的实用价值最终都要看它的成本效益比。OPUS在这方面表现得相当出色,它仅仅增加了4.7%的计算开销,却带来了显著的训练效果提升。
这个开销主要来自三个方面:代理方向的计算、候选样本的特征提取,以及CountSketch投影。研究团队通过精心的工程优化,将这些操作的成本控制在了最低水平。
相比之下,如果使用传统的动态选择方法进行同样精度的数据选择,计算开销可能会达到350%以上。这就像用手工方式做精细食材处理和使用专业设备的区别,效率相差悬殊。
更重要的是,OPUS带来的训练效果提升远远超过了这点额外开销。在某些实验中,OPUS训练的模型达到相同性能水平所需的数据量只有传统方法的1/8。考虑到大规模AI训练的数据处理成本,这种效率提升的经济价值是巨大的。
七、未来展望:数据选择的新时代
OPUS的成功标志着AI训练数据选择进入了一个新的阶段:从经验驱动转向科学驱动,从静态标准转向动态适应,从单一指标转向综合优化。
这项研究的意义不仅在于提出了一个新的数据选择方法,更重要的是它建立了一个新的研究范式。它表明,要真正优化AI训练过程,我们不能孤立地看待数据、算法和优化器,而是要将它们作为一个整体系统来考虑。
研究团队在论文中也指出了一些未来的研究方向。比如,如何将OPUS扩展到多模态数据(图像、音频等)的选择中,如何在更复杂的混合数据集上应用这种方法,以及如何进一步降低计算成本等。
随着AI模型规模的不断增长和训练成本的急剧上升,高效的数据选择技术将变得越来越重要。OPUS为这个领域提供了一个强有力的工具和一个新的思路。它不仅能够帮助现有的AI系统提高训练效率,更可能为未来更大规模、更智能的AI系统铺平道路。
说到底,OPUS的核心理念其实很简单:要想做出好菜,不仅要有好食材,还要了解你的烹饪工具,让食材和工具完美配合。这个简单的道理在AI训练中同样适用,而OPUS正是将这个道理转化为了可行的技术方案。对于那些正在为AI训练效率和成本头疼的研究者和工程师来说,OPUS无疑提供了一个值得尝试的新选择。
Q&A
Q1:OPUS数据选择方法与传统方法有什么本质区别?
A:OPUS的核心区别在于它会根据具体使用的优化器(如AdamW、Muon)来选择数据,而传统方法都假设使用最简单的SGD优化器。就像根据不同的烹饪方法来选择食材,而不是用统一标准选择所有食材。
Q2:OPUS如何在保证选择质量的同时控制计算成本?
A:OPUS通过幽灵技术避免完全计算每个样本的梯度,使用CountSketch投影将高维信息压缩到低维空间处理,这样只增加4.7%的计算开销就实现了高质量的数据选择。
Q3:OPUS适用于哪些AI训练场景?
A:OPUS既适用于从头开始训练大语言模型,也适用于在特定领域继续训练的场景。实验表明它在通用数据集FineWeb和专业数据集SciencePedia上都取得了显著的效果提升。




