今天,我们把“缓存穿透”这个技术难题彻底聊透了,从原理到危害,再到应对策略,一次讲明白。其实,它与缓存击穿、缓存雪崩并称“Redis缓存三大难题”——乍一看三者很像,但其核心原理和解决方案实则大相径庭,各有侧重。
在Redis的实际应用中,“缓存雪崩、击穿、穿透”这三大高频难题,咱们开发者应该都不陌生。前两者我们后续再细聊,今天先单拎出这个最容易被忽视、但破坏力极强的——缓存穿透。
很多人容易把它们搞混,其实分辨起来很简单:雪崩和击穿发生时,数据库里其实是有对应数据的,缓存只是暂时“挡不住”了,只要扛过那一阵,缓存恢复就没事了;但“缓存穿透”不一样,它是从根源上就无数据可查,属于典型的“无中生有”型灾难。

1. 什么是缓存穿透?
咱们不用看刻板的流程图,直接设想一个真实场景:
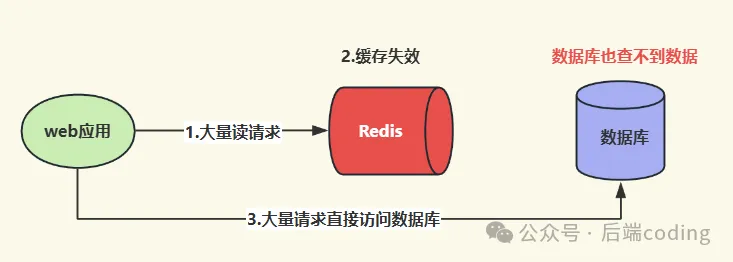
用户发起了一个查询请求,Web应用先去查Redis,发现没有数据;接着去查数据库,发现数据库里竟然也没有。因为数据库里根本没有这条记录,应用自然也就没办法把结果回写到缓存里。
这就导致了一个死循环:只要是查这条不存在的数据,Redis就永远拦截不住,所有请求都会直挺挺地打到数据库上。一旦遭遇恶意攻击(比如用不存在的ID疯狂请求)或者业务代码出现Bug,海量的无效请求瞬间就会把脆弱的数据库压垮。
2. 如何防御?三招致胜
针对这种“请求直通数据库”的顽疾,我们有三道防线,由浅入深,各有妙用。
(1) 第一道防线:把门看好,从源头拦截
最简单直接的方法,就是别让这些离谱的请求进门。很多穿透的诱因是恶意攻击,比如查询负数ID、或者格式极其怪异的参数。我们完全可以在API入口层就做严格校验。凡是参数不合规、或者请求频率异常高的,直接在网关或Controller层拒掉。连Redis都不用查,更别说数据库了。这是成本最低、效果最立竿见影的手段。
(2) 第二道防线:缓存空值,以此毒攻毒
如果请求合规,但数据确实不存在(比如查一个刚注销的用户),怎么办?这时候可以用“缓存空值”策略。既然数据库里没数据,那我就在Redis里存一个“空值”或者默认标记,并且给它设一个较短的过期时间(比如1分钟)。下次再有人查这个不存在的数据,Redis直接把这个“空值”甩给他,请求就不用走数据库了。
但这招有两个坑,实操时一定要注意:第一,必须设置过期时间。否则万一数据库里后来真有了这个数据,Redis里却还死守着那个“空值”,业务就乱套了。第二,警惕内存爆炸。如果攻击者太坏了,用海量随机且不同的ID来攻击(比如 `id=uuid`),Redis里会瞬间存入成千上万个“空值”键。所以,这招最好配合第一道防线一起用,且过期时间越短越好。
(3) 第三道防线:布隆过滤器,给数据装个“安检门”
如果说缓存空值是“兵来将挡”,那布隆过滤器就是“御敌于国门之外”,这是解决穿透最优雅的方案,特别适合大数据量场景。
它的原理像是一个极度节省空间的“黑白名单”。在数据写入数据库时,我们同步把数据的“指纹”存入布隆过滤器。当请求来的时候,先问问布隆过滤器:“这数据可能存在吗?”
如果它说“不存在”,那绝对是不存在,直接驳回,连Redis都不用查。如果它说“存在”,再去查Redis和数据库。使用布隆过滤器,你只需要接受它的两个小脾气:一是它有极低的误判率(它说存在,实际可能不存在),但这顶多是多漏几个请求去库里,无伤大雅;二是它删除数据很麻烦(标准版不支持删除),如果你的业务经常删数据,记得要定期重建过滤器,或者使用支持删除的“布谷鸟过滤器”或“RedisBloom”插件。
3. 系列预告:缓存难题未完待续
今天我们吃透了缓存穿透的原理、危害和解决方案,其实它和缓存击穿、缓存雪崩并称为“Redis缓存三大难题”——三者看似相似,实则核心差异很大,解决方案也各有侧重。
后续文章,我们会逐一拆解:
缓存击穿:缓存中某一热点数据失效,大量请求直达数据库的解决方案;缓存雪崩:大量缓存数据同时失效,数据库被瞬间压垮的应对策略。



