1 月 27 日,DeepSeek 发布了《DeepSeek-OCR 2: Visual Causal Flow》论文,并同步开源新一代文档理解模型。这是该公司在 2026 年 1 月的第三次技术更新:月初完善了 R1 论文的技术细节,中旬开源了 Engram 记忆模块,月末又推出 OCR 2。如此密集的节奏,也让外界猜测春节前后可能亮相的 DeepSeek-V4 的轮廓逐渐成形。

图 | Deepseek 最新论文:视觉因果流(来源:GitHub)
在讨论 OCR 2 的更新前,不妨先回溯去年 10 月的初代版本。虽然名字里带着“OCR”(Optical Character Recognition,光学字符识别),但 DeepSeek 开源的初代模型瞄准的并非传统意义上的字符识别,而是想解决大模型长期面临的一个瓶颈:超长上下文带来的算力压力。
由于大语言模型的自注意力机制计算复杂度随序列长度呈平方级增长,当上下文从千级 token 扩展到万级,计算量可能暴增百倍。处理上百页的财报或整本书时,开发者往往陷入两难:要么切片分段输入,牺牲全局连贯性;要么硬扛长序列,付出高昂的计算成本与延迟。
DeepSeek 团队选择换了个思路:既然文本 token 太昂贵,能否用图像来“打包”同等信息?他们发现,将一页文档渲染为图像后,视觉编码器提取的视觉 token 数量远少于等效文本,却能完整保留文字与版式结构。这套“上下文光学压缩”(Contextual Optical Compression)技术,本质上是将一维的文本序列“折叠”进二维像素空间,借图像的天然空间结构实现高效压缩。
而 OCR 从图像中还原文本的任务效果,恰好可以成为验证压缩质量的理想标尺:还原越准,说明压缩越有效。
最后的成果确实令人瞩目。在 10 倍压缩率下,文本还原准确率仍达 97%;即便压缩至 20 倍,准确率也保持在 60%左右。一张 1,024×1,024 的文档图像,传统方案需数千 token,DeepSeek-OCR 仅用 256 个即可表征,效率奇高。
但初代 OCR 也存在明显短板。它的核心编码器 DeepEncoder 采用 SAM(Segment Anything Model,分割万物模型)加 CLIP(Contrastive Language-Image Pre-training,对比语言图像预训练)的双模块设计:SAM 负责局部细节感知,CLIP 负责全局语义理解,中间嵌入 16 倍压缩层。这套架构虽然高效,但在处理图像时遵循固定的空间顺序——无论文档内容如何,视觉 token 总是按从左上到右下的栅格排列。
也就是说,不管面对的是论文、发票还是漫画,模型都像扫描仪一样逐字逐行,从左到右地机械扫描。这显然和人类读文档的方式不同,我们会根据版面布局、语义结构进行自然跳转:先看标题,再看摘要,表格要整体理解,图注和正文有对应关系。
此次发布的 OCR 2 要解决的正是这个问题。新架构 DeepEncoder V2 做了一个关键改动:用一个小型语言模型(基于 Qwen2-0.5B,约 5 亿参数)替代了原有的 CLIP 模块,从而引入了“因果”机制。
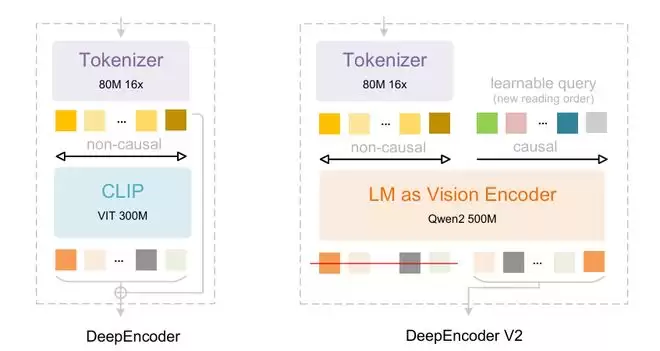
(来源:论文)
具体而言,V2 把视觉 token 分成了两组处理:第一组是原始视觉 token,它们之间可以互相“看到”,保证模型对整张图有全局视野;第二组是新引入的“因果流查询”(causal flow query),它们有严格的先后顺序。每个查询只能看到它前面的信息,就像人逐步阅读文档时,后面理解的内容会基于前面已读的内容来组织。
这种设计让模型可以根据图像内容动态调整“阅读顺序”。最终送入解码器的只有第二组 token,它们已经按语义逻辑重排过,而非机械的空间顺序。论文把这称为“视觉因果流”(visual causal flow)——让 2D 图像理解通过两级级联的 1D 因果推理来实现。
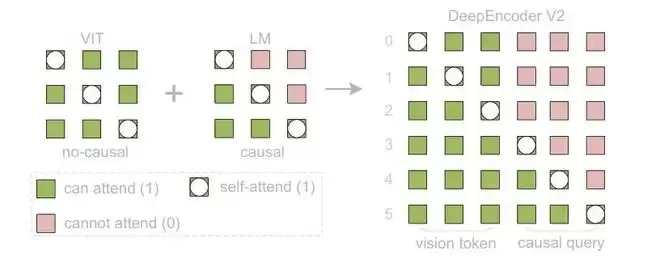
图 | 混合注意力掩码 (Attention Mask) 设计(来源:论文)
这种改变带来的提升是多维度的。
在 OmniDocBench v1.5 测试集上(涵盖杂志、论文、研究报告等 9 类文档),OCR 2 总体得分 91.09%,比前代提升 3.73 个百分点。更能说明新架构价值的是“阅读顺序”指标:编辑距离从 0.085 降到 0.057,意味着模型对文档结构的判断更准确。它确实在学着按语义而非空间来组织信息。
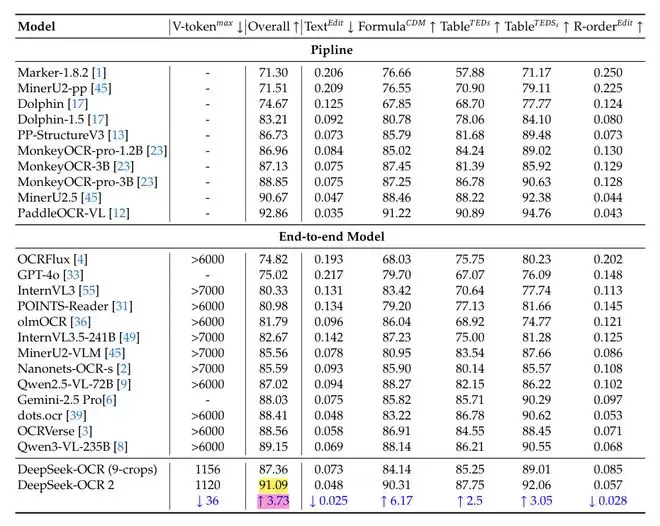
图 | OmniDocBench v1.5 核心评测结果(来源:论文)
同时,OCR 2 延续了前代的高压缩率优势,视觉 token 上限仅 256–1,120 个,而多数同类模型需要超过 6,000 个。在文本、公式、表格等细分类别上均有 2–6 个百分点的提升,与 Gemini-3 Pro 在相近 token 预算下的对比中(文档解析编辑距离 0.100 vs 0.115),OCR 2 也占据优势。
得益于此,OCR 2 拥有了更广泛的应用场景,它可以用来处理布局复杂、结构多变的文档。例如学术论文中多栏混排加公式表格、财务报表里数据图表与文字说明交织、杂志版面的图文混搭——这些曾经让初代 OCR 捉襟见肘的场景,现在恰恰是因果视觉流架构的用武之地。
不过,新架构并非完美。论文坦承,在报纸类文档上,OCR 2 的识别准确率仍有明显差距,甚至识别性能略低于一代模型。团队归因于两点:一是报纸版面密集、文字量大,当前 token 上限可能不足(可通过增加局部裁剪缓解);二是训练数据中报纸样本仅 25 万张,覆盖有限。这再次印证了端到端模型的通病:性能高度依赖训练数据的广度与质量。
此外,有研究者通过语义破坏实验发现,DeepSeek-OCR 系列的高分部分源于语言先验——模型有时是“猜”出内容,而非真正“看清”。当输入被刻意打乱时,性能会显著下滑。这意味着在识别生造词、严重污损的扫描件等边缘场景中,其鲁棒性可能仍不及传统管道式 OCR。
回看 1 月的三次技术更新,一条清晰的主线逐渐浮现:DeepSeek 正系统性地探索如何让模型在不同任务中“更聪明地工作”,而非一味堆叠计算量。
月初,团队将 R1 论文从 22 页大幅扩充至 86 页,揭示其推理能力的核心来源。并非依赖海量人工标注数据,而是通过强化学习在“做题-反馈-改进”的循环中自主学会思考与纠错。这为低成本训练强推理模型开辟了一条新路径。
中旬,梁文锋署名的 Engram 论文进一步延伸这一思路:既然人名、术语等静态知识无需每次重新思考,何不将其存为可检索的记忆表?实验表明,将约 20%的参数用于构建这类外部记忆、80%保留给动态计算,在知识问答、推理与代码任务上反而表现更优。
到了月末,OCR 2 则将这一哲学延伸至视觉领域。它不再让模型机械地按空间栅格扫描文档,而是引入因果机制,使其能像人类一样根据语义结构动态调整“阅读顺序”。
三次更新看似分别切入推理、记忆与视觉,实则共同回应一个问题:模型在哪些环节可以少算多查,或重组流程以提升效率?R1 证明复杂推理可借强化学习涌现,Engram 验证静态知识适合查表替代计算,OCR 2 则展示 2D 图像理解能通过因果排序适配 1D 语言模型的处理范式。这种结构优化的转向,或许正是 DeepSeek 为下一代模型铺就的底层逻辑。
如果传闻属实,计划于 2 月中旬春节前后发布的 DeepSeek-V4,或将首次整合这三条技术线索:融合 R1 的推理框架、Engram 的记忆架构与 OCR 2 的视觉理解能力,打造一个更高效处理文本、代码与复杂文档的多面手。不过最终体验如何,我们还需等待春节它的真正亮相。
1.https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
运营/排版:何晨龙




