1月26日,阿里正式发布了全新的千问旗舰推理模型Qwen3-Max-Thinking,在多项权威评测中刷新了多项全球纪录。其性能表现足以媲美GPT-5.2与Gemini 3 Pro,成为迄今为止最接近国际顶尖水准的国内AI大模型。通过海量总参数、强化学习与推理计算的极致规模扩展,千问新模型实现了性能的大幅飞跃,一举刷新了科学知识(GPQA Diamond)、数学推理(IMO-AnswerBench)、代码编程(LiveCodeBench)等多项关键基准测试的全球最佳纪录。
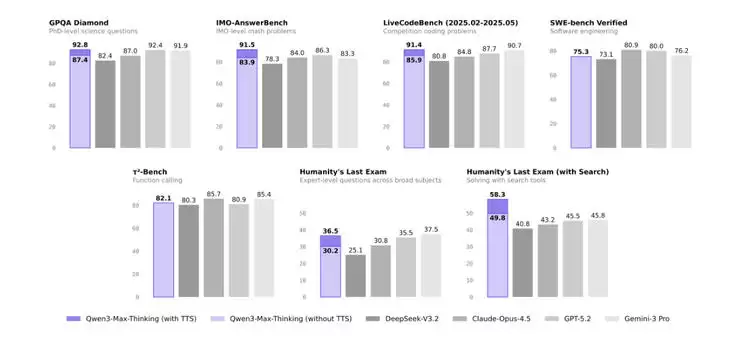
Qwen3-Max-Thinking是阿里目前规模最大、能力最强的千问推理模型,其总参数量超过万亿(1T),预训练数据量高达36T Tokens。此前,预览版Qwen3-Max-Thinking已斩获数学推理AIME 25和HMMT 25的双满分成绩,成为国内首个达成此成就的模型,其推理性能令人惊艳。在此基础上,阿里通义团队进行了更大规模的强化学习后训练,全面提升了正式版Qwen3-Max-Thinking的各项性能:在涵盖事实知识、复杂推理、指令遵循、人类偏好对齐、智能体能力等19个公认的大模型基准测试中,这款旗舰推理模型刷新了多项关键性能的最佳表现纪录,其综合性能已可媲美GPT-5.2-Thinking-xhigh、Claude Opus 4.5 以及 Gemini 3 Pro。
在关键的模型推理能力提升方面,千问新模型采用了一种全新的测试时扩展机制。这一创新机制能在提升推理性能的同时,实现更高的计算经济性。业界普遍的推理时计算,通常只是简单地增加并行推理路径,导致大量重复推导已知结论,造成计算资源浪费和推理效率低下。而千问采用的这一新机制,能够对先前的推理结果进行“经验提炼”式的提取与精炼,并据此进行多轮自我迭代,在相同的上下文语境中实现更高效的推理计算,从而获得更智能的推理结果。基于这一核心技术创新,千问模型的推理性能和效率均得到显著提升。例如,在启用了工具调用的“人类最后的测试”HLE中,千问取得了58.3分,大幅超越了GPT-5.2-Thinking的45.5分和Gemini 3 Pro的45.8分,获得了当前所有模型中的最高分数。
面向即将到来的智能体时代,Qwen3-Max-Thinking还大幅增强了自主调用工具的原生智能体能力。具体而言,在完成初步的工具使用微调后,通义团队对模型进一步在大量多样化任务上进行了基于规则奖励与模型奖励的联合强化学习训练,使得Qwen3-Max-Thinking拥有更智能地结合工具进行深度思考的能力。这种自适应工具调用能力可在QwenChat上完整体验。模型能自主选用搜索、个性化记忆和代码解释器这三个核心的智能体工具功能,提供的回答具有专业人士般的水准,更贴合用户心意、显得更智能、更流畅。同时,模型产生幻觉的概率也大为降低,为解决真实世界中的复杂任务奠定了坚实基础。
目前,开发者可在QwenChat上免费体验Qwen3-Max-Thinking模型。企业用户可通过阿里云百炼平台获取新模型API服务。普通用户也可以通过千问PC客户端及网页端试用新版模型。据了解,千问官方应用也即将接入新模型,届时所有用户都可免费体验千问的最强模型。




