OpenAI 近日发布了最新的技术博客,深入探讨了公司如何对开源关系型数据库 PostgreSQL 进行深度定制与规模化改造,并成功支撑了 ChatGPT 及 OpenAI API 全球范围的高并发业务。这一实践更新了业界对传统关系型数据库扩展能力边界的认知。
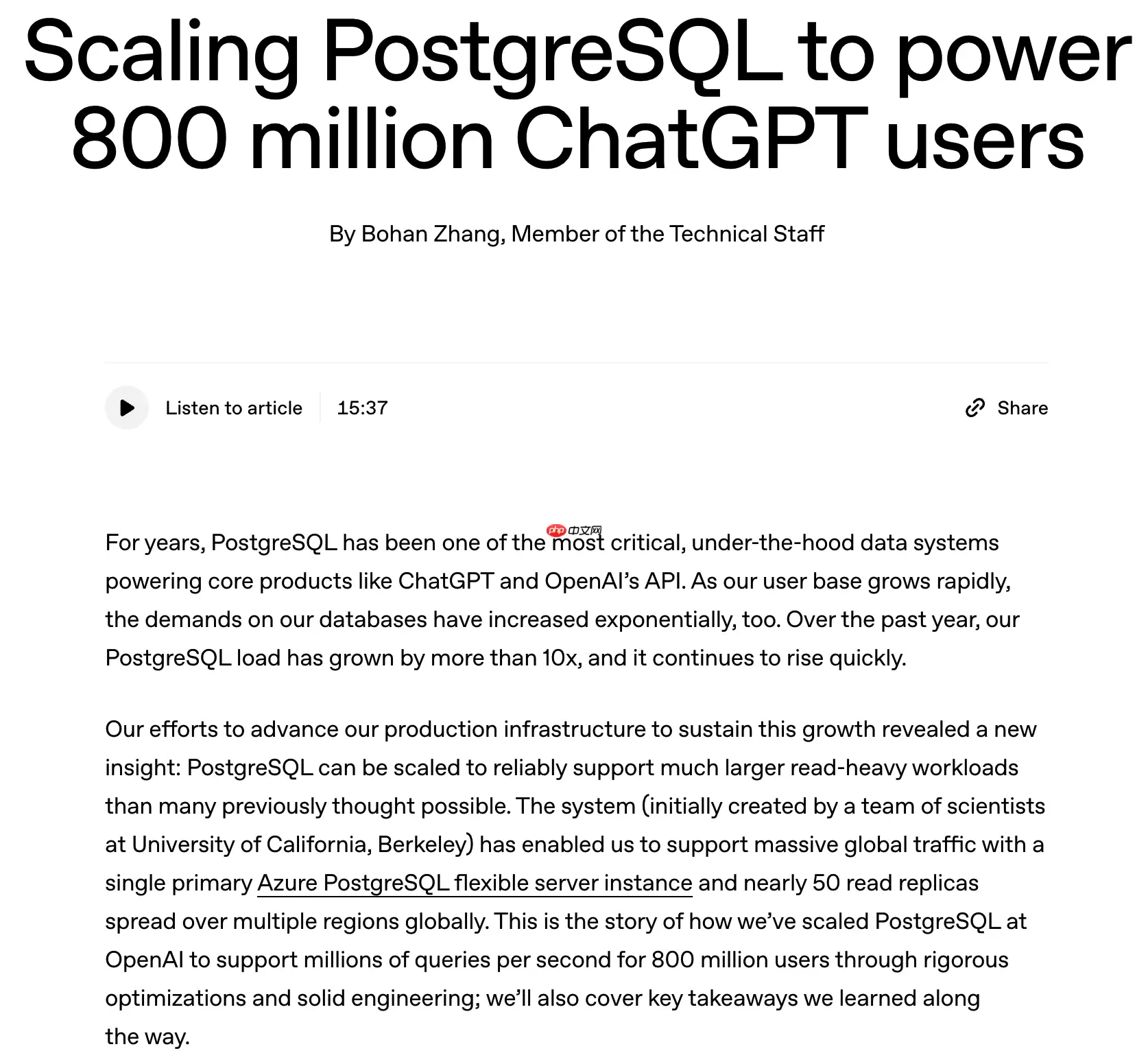
随着 ChatGPT 用户量持续攀升,OpenAI 在过去一年中观察到 PostgreSQL 集群的整体负载 增长了超过 10 倍。为了应对峰值高达数百万查询/秒的流量压力,并维持毫秒级响应延迟,团队在数据库架构、运维策略与应用协同层面实施了系统性升级。
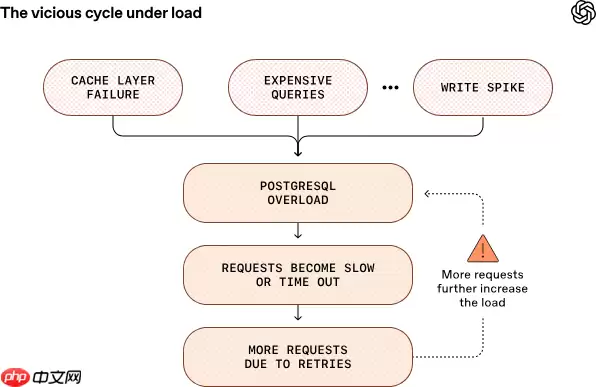
其整体架构仍沿用稳健的 单主节点模式,配合全球多个区域的只读副本来分担负载:所有写操作集中于主库,而由约 50 个地理分散的只读副本承担全球范围内的读取请求。这一设计避免了数据分片带来的复杂性与一致性挑战,同时能够高效支撑海量的读取场景。
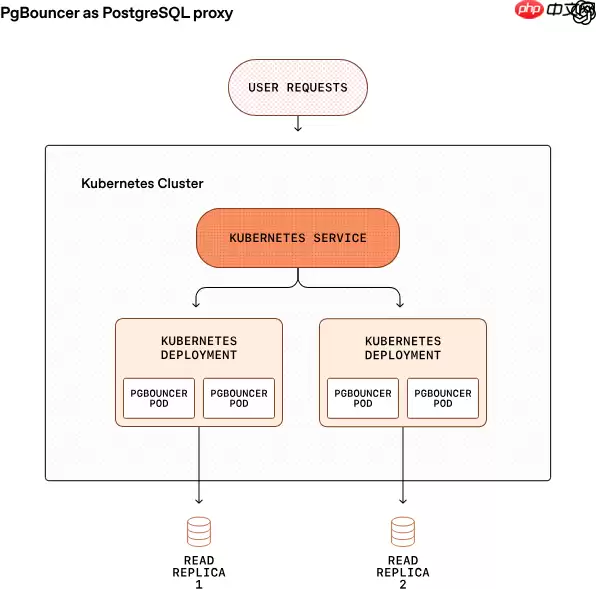
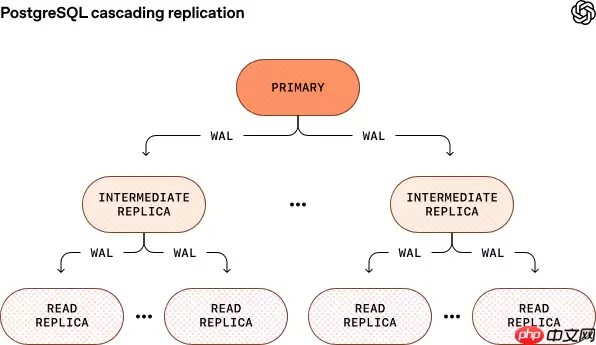
关键技术优化
1. 写负载剥离与精简
为缓解主库写入瓶颈,OpenAI 将部分高吞吐、可水平扩展的密集型任务迁移至专用分片存储,并在应用层主动收敛非必要写入,显著降低了主库的事务压力。
2. 全面推行读写分离
仅保留必须与写事务强绑定的读操作在主库执行;其余绝大多数读请求均由各地副本承接,有效分流了主节点资源消耗。
3. 连接复用与智能缓存协同
引入 PgBouncer 作为连接池中间件,将平均连接建立耗时从约 50ms 优化至 5ms 以内;同时配合分级缓存机制,防止缓存失效风暴引发数据库瞬间过载。
4. 查询治理与资源分级管控
严格限制多表 JOIN 等高开销 SQL 语句的执行,将复杂关联逻辑前置至应用层处理;通过资源隔离策略,将后台分析、低优先级请求与核心在线服务进行物理隔离,杜绝了资源争抢带来的干扰。
5. 主库高可用与快速故障恢复
主库部署于高可用架构下,并配置实时热备节点,确保主节点异常时可在秒级内完成无缝切换,最大限度保障服务级别协议。
经过上述综合调优,OpenAI 的 PostgreSQL 集群实现了以下关键指标:
- 支撑 百万至数百万 QPS 的稳定读取吞吐
- 实现 全球各区域毫秒级访问延迟
- 达成 99.999% 的服务可用性
- p99 延迟控制在 数十毫秒以内
在最近十二个月的运行周期中,仅发生一次严重级别数据库事件,其起因是图像生成功能用户量激增导致的局部资源饱和。
这一实践有力印证了:在严谨的工程方法论与精细化架构设计支撑下,PostgreSQL 完全可胜任超大规模生产环境的核心数据存储角色。对于多数尚未面临强分片需求的团队而言,它提供了一条更具可控性、更成熟、性价比更高的技术演进路径。
后续,OpenAI 正在评估包括 PostgreSQL 原生数据分片方案、级联复制增强、以及异步复制链优化等方向,以进一步提升只读副本弹性与跨区域同步效率。
了解更多相关信息




