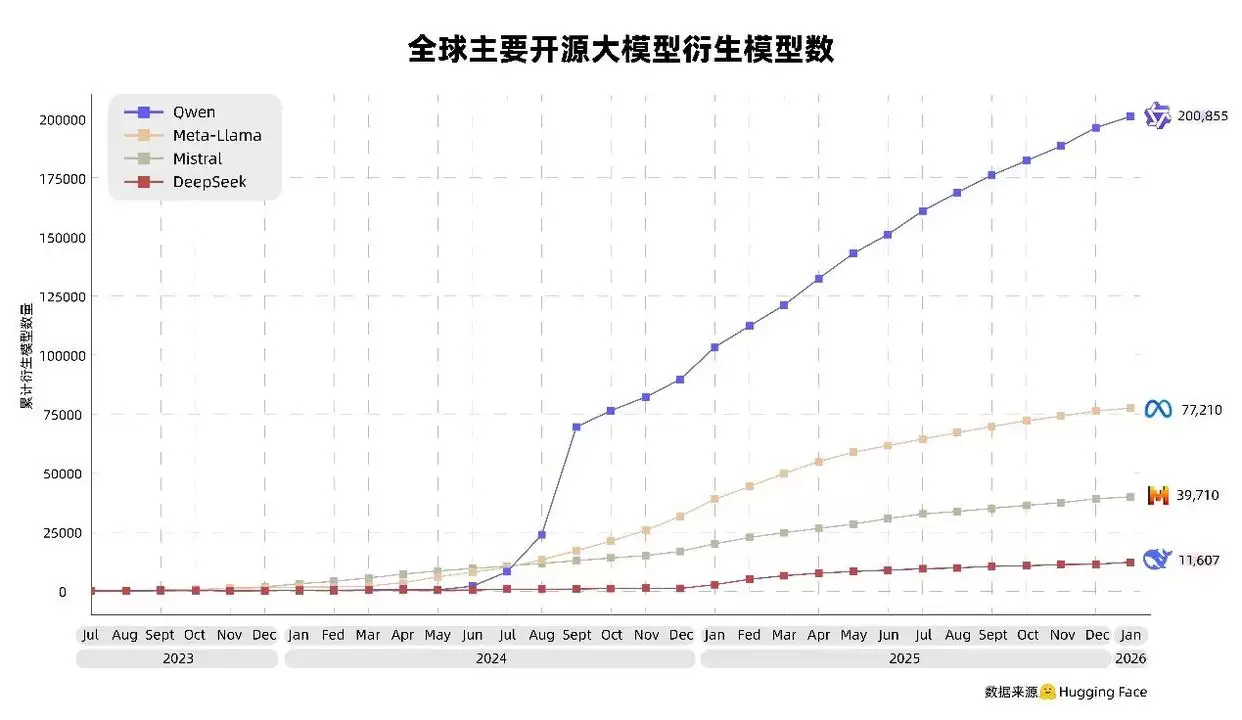
最新数据显示,阿里“千问”系列大模型的衍生模型数量已突破20万个,成为全球首个达成这一里程碑的开源大模型项目。这一成绩标志着其在开源生态中的影响力达到了新的高度,不仅刷新了纪录,也展现出强大生命力。同时,千问系列模型的累计下载量已超过100亿次,日均下载量高达110万次,整体表现已超越美国Llama系列,稳居全球开源大模型首位。
在开源生态里,衍生模型的数量常被视为衡量模型影响力的核心标准之一。2024年以来,阿里已陆续开源近400个大模型,极大地激发了全球开发者的二次开发热情,催生出大量的技术创新与应用场景。这些由社区孵化出的新模型也持续选择开源,从而形成了一个健康、活跃的良性循环。例如,斯坦福大学李飞飞团队就以千问为基础,训练出推理模型s1,显著推动了开源社区在AI推理领域的研究进展。
根据Hugging Face的统计,目前全球开发者平均每天基于千问新增的衍生模型超过200个,应用场景涵盖了机器人控制、代码生成、漫画后期处理、多语种翻译等多个热门领域,展现出极其丰富的生态活力。
另一方面,模型下载量则直接反映了开源成果在实际应用中的普及程度。千问系列开源模型覆盖了从0.5B到480B的全尺寸参数范围,支持文本、视觉等多模态任务,具备广泛的适用性。其中,千问3支持多达119种语言和方言,为小语种AI开发、多模态技术探索以及AI硬件部署提供了有力支撑,显著降低了全球范围内的技术使用门槛,让更多开发者能够便捷地利用前沿AI能力。




