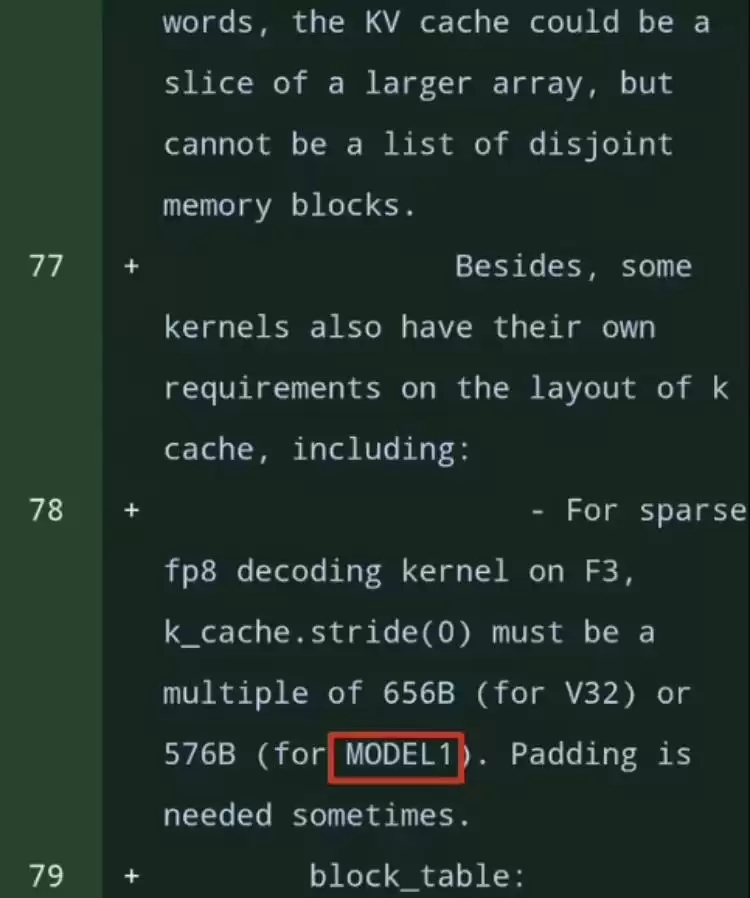
1月21日,有开发者在GitHub平台意外发现,DeepSeek近期悄然更新了一批与FlashMLA相关的代码。在一共涉及的114个文件中,有28处提到了一个此前未曾公开的“MODEL1”模型标识符,立刻引起了技术社区的广泛关注。这个神秘的标识符在代码中与已知的“V32”(即DeepSeek-V3.2)模型并列出现,很可能用于区分不同架构,似乎暗示着一款新型模型正在开发之中。
经过进一步分析,“MODEL1”在多个关键技术层面的实现方式与现有模型存在差异。它在键值缓存的布局结构、稀疏性处理机制以及对FP8数据格式的解码支持等方面,都展现出独特的实现思路。这些技术细节上的变化,暗示新模型或许在内存使用效率和计算性能上经过了专门优化,旨在进一步提升推理速度与硬件资源利用率。
这一发现恰好印证了近期业内的诸多传闻。多方消息显示,DeepSeek计划在今年2月中旬,也就是农历新年期间,正式发布新一代旗舰级人工智能模型DeepSeek V4。据传,该模型在代码生成与理解能力方面有望实现显著突破,内部测试结果表明,其表现很可能超越当前的主流同类产品。
此外,DeepSeek研究团队在过去一段时间内相继发布了两项重要的技术成果:一是提出了一种名为“优化残差连接(mHC)”的新型训练方法,目的是提升模型训练的稳定性与收敛效率;二是引入了“条件记忆”这一全新架构范式,并开源了配套的记忆模块Engram。业界普遍推测,即将推出的V4模型很可能会整合上述研究成果,从而进一步增强其长上下文处理能力与复杂任务推理性能。




