近日,英伟达研究团队正式发布了全新的全双工语音对话模型——PersonaPlex-7B-v1。该模型致力于突破传统AI语音助手“听一句、答一句”的机械交互模式,旨在打造更具人情味、更贴近真实人际交流的对话体验。
有别于以往需要依赖ASR(语音识别)、LLM(大语言模型)、TTS(文本转语音)多模块串行处理的复杂流程,PersonaPlex-7B-v1基于统一的Transformer架构,直接从输入语音到输出语音实现端到端映射,无需中间文本表示。
这种一体化的设计显著压缩了端到端延迟,同时赋予模型原生支持自然打断、多人语音交叠、实时响应等关键对话能力。换言之,AI在发声过程中始终处于“聆听状态”,用户中途插话或切换话题时,模型能即时调整回应,其行为逻辑高度拟人。
值得一提的是,模型支持“语音+文本”双通道角色设定:用户既可通过文字描述定义AI的人设、专业背景与表达风格,也可上传参考语音样本,精准调控其音色、语速、韵律乃至情绪倾向。
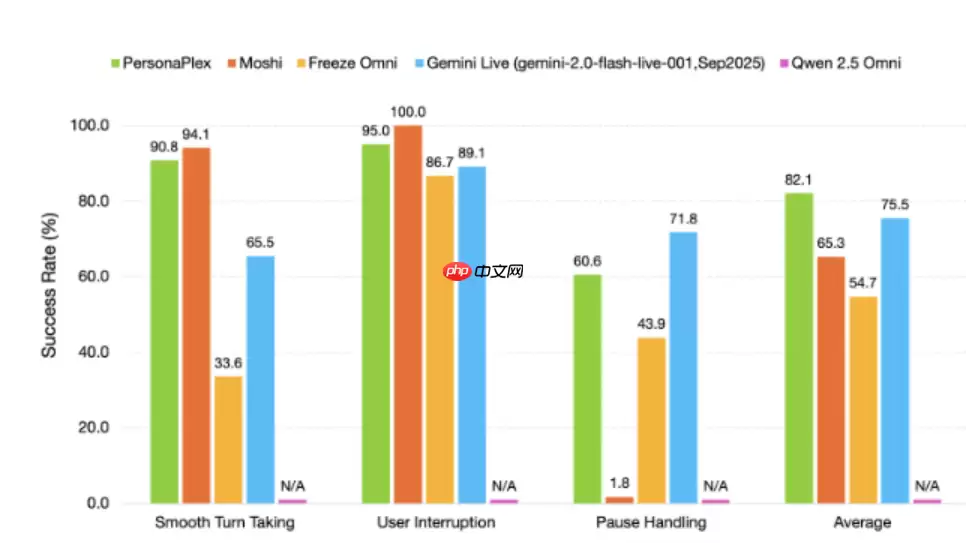
在训练阶段,英伟达融合大规模真实电话对话数据与高保真合成场景数据,兼顾语言自然性与行业合规性,使模型既能掌握日常对话的节奏与习惯,也能严守金融、医疗、客服等垂直领域的术语规范与服务规则。当前基准测试表明,PersonaPlex-7B-v1在对话连贯性、上下文一致性及任务完成率等核心指标上,全面超越主流开源及商业闭源语音对话系统。




