在使用Python抓取网页信息时,你可能会遇到URL里包含特殊字符的情况。这时候,我们通常需要先执行解码操作,这样才能确保请求地址准确无误,顺利获取目标数据。接下来,我将带你一步步了解编码转换与数据抓取的完整过程。
1、首先,当然是要引入必要的库。在这个例子中,我们将使用urllib包下的两个核心模块,具体方法如下所示。
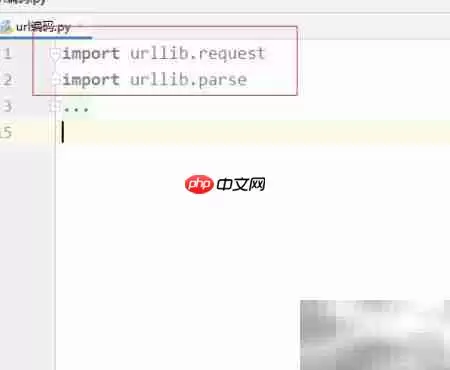
2、其中,request模块主要负责发起网络请求,而parse模块则专门用来处理URL的编码与解码任务,二者分工明确。
3、为了让你更清楚地理解,本文将以一个大家熟悉的汽车资讯平台作为实际案例来展开说明。
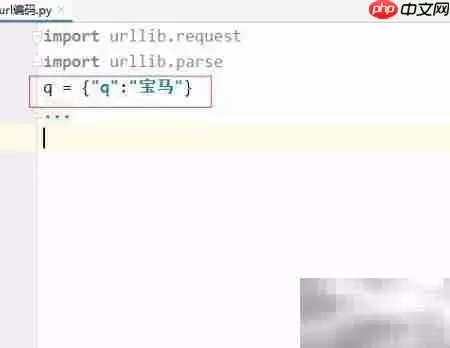
4、我们先创建一个字典q,将其键名设置为“q”,对应的值为“宝马”。这个小字典将作为我们传递参数的基础。
5、这样一来,搜索关键词“宝马”就作为键q的取值了,这就完成了参数的初始化配置,非常简单。
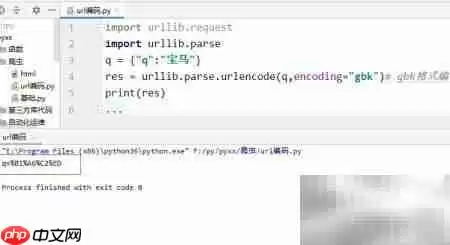
6、字典定义好后,我们需要对其中的value部分进行URL编码处理。因为我们的目标网站采用GBK字符集,所以你必须选择GBK编码方式来执行转义操作,这一点很重要。
7、对字典中q所对应的“宝马”字符串,使用GBK编码标准进行URL编码,这样才能生成合法且可传输的查询参数,避免乱码问题。
8、编码完成后的结果,效果如下图所示:
9、接下来,我们需要拼接完整的请求URL。由于本次目标是搜索结果页,所以我们额外定义一个整型变量i来表示当前页码,方便后续进行翻页抓取。
10、在基础URL模板中,将关键词占位符替换为已编码的res变量,而页码位置则由变量i动态填充,这样就能灵活生成不同页面的链接了。
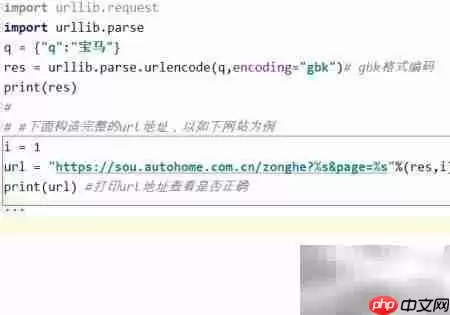
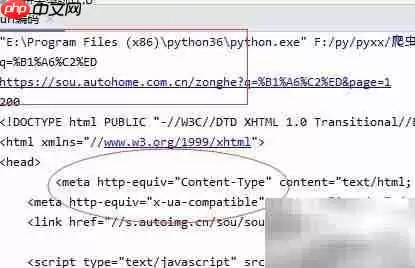
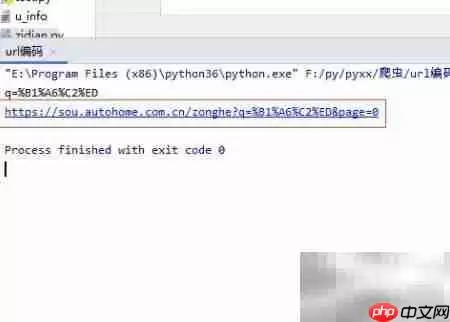
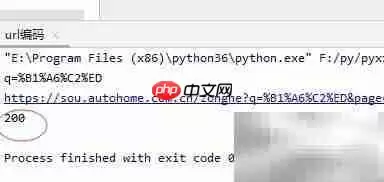
11、生成最终URL后,建议先打印输出,并手动复制到浏览器中打开,验证链接是否能正常跳转并展示预期内容。具体效果可参考下图:
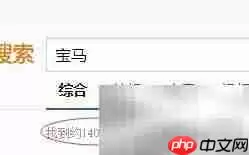
12、确认URL有效后,就可以调用request模块发送HTTP请求了。记得检查返回的状态码是否为200,以此判断网络连接是否成功建立。
13、向构建好的URL地址发起GET请求,接收服务器返回的响应对象,这个过程是所有爬虫操作的核心步骤。
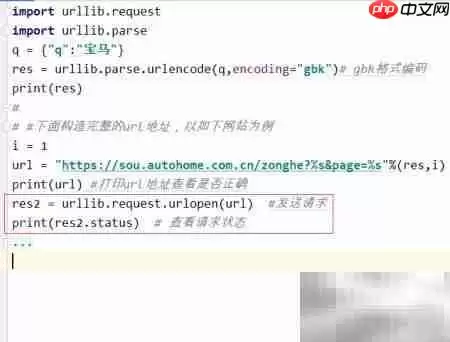
14、获取到响应内容后,你需要按照实际的编码格式(此处为GBK)进行解码,然后再输出原始HTML源代码。具体实现代码如下:
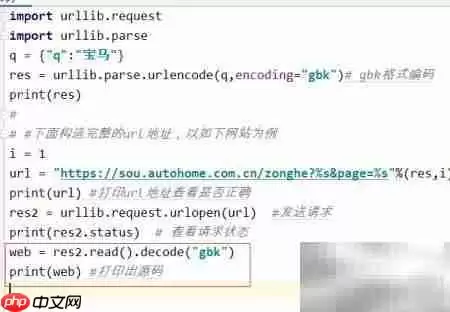
15、所有代码整合汇总及实际运行效果截图如下: