IT之家1月13日消息,在互联网的通行规则里,编辑引用他人内容时,通常会附上信息来源,这既是对原创者的尊重,也为读者查验原文提供了便利。这种注明出处的做法,无形中为原始平台带来了访问流量,构成了互联网长期运行的隐性契约。
然而,在AI技术蓬勃发展的当下,这套固有的平衡机制正在迅速瓦解。如今,各大AI模型直接根据用户指令抓取海量网络数据,导致用户访问原始内容页面的意愿显著降低。与此同时,内容提供方却需要承担AI工具频繁抓取所带来的巨额流量消耗。
综合Cloudflare及外媒Business Insider的报道,自2025年起,Cloudflare开始系统性追踪这一失衡现象。他们通过统计大型科技公司网络爬虫的请求次数,以及对比这些公司最终为内容源带去的实际访问量,计算出一个“抓取回流比”。这个指标能直观反映平台从互联网“拿走”了多少价值,又“回报”了多少。例如,100:1的比例意味着平台每抓取内容100次,仅为原创者带来1次访问。
在Cloudflare的统计数据中,Anthropic的“抓取回流比”表现最差,其数据抓取量远高于它所能带来的实际访问量。OpenAI的情况也类似,其抓取与回流比同样不佳。这意味着,这两大平台正从互联网获取越来越多的价值,但反馈给内容生态的却越来越少。
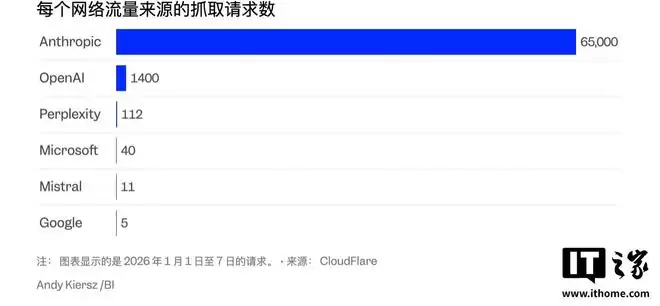
这一趋势与Business Insider在2024年末的调查相互印证。当时的报道指出,Anthropic和OpenAI的网络爬虫对部分网站的抓取频率“高到惊人”,甚至导致网站流量与云计算成本大幅上升。
一位开发者当时透露,仅仅几个月内,其客户的云服务账单就因为AI爬虫的暴增而翻了一倍。也就是说,AI公司不仅从互联网获取内容、减少流量回流,还在无形中将更高的运营成本转嫁给了所有内容提供者。




