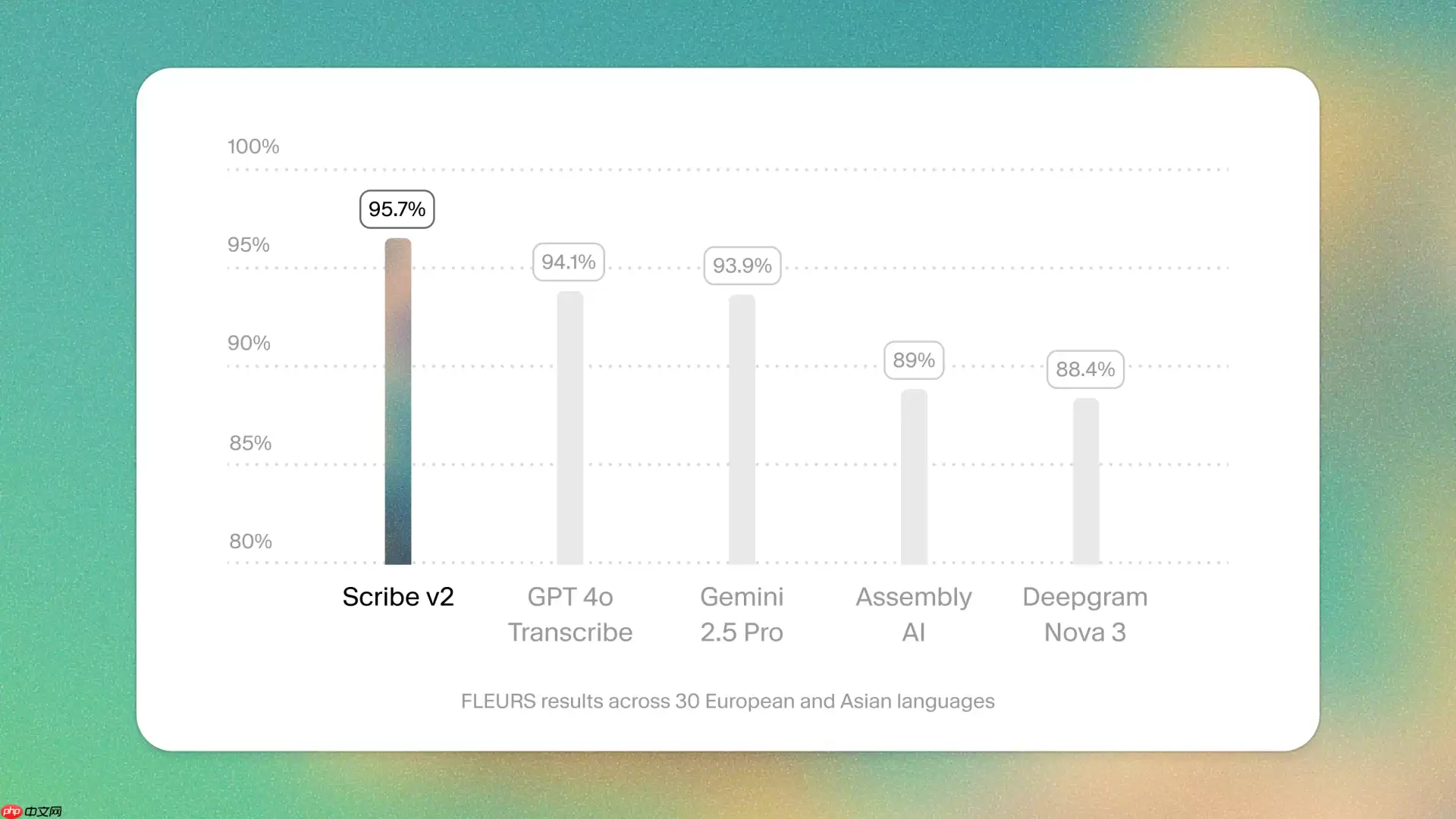
ElevenLabs正式推出第二代转录模型Scribe v2,该系统专为高效处理离线批量语音转写与自动生成字幕而设计。新版本在英语上的词误率已降至5%左右,并对包括印地语在内的全球超过90种语言保持了低于10%的识别错误率控制。

Scribe v2现已深度集成至ElevenLabs Studio平台,它能够处理单次时长超过10小时的超长音频文件,并全面符合GDPR、HIPAA等主流国际数据合规标准。其核心能力包括基于关键词引导的Keyterm Prompting功能,以及具备上下文感知能力的智能多说话人日志识别技术。
核心优势
- 面向大规模转录与字幕任务优化:Scribe v2专为高吞吐量语音转写、自动字幕生成及标题提取而优化,在稳定性与准确性方面显著优于前代Scribe v1,可稳健应对长时音频、自然停顿、语调起伏及长时间静音等复杂语音现象;原生支持超过90种语言,轻松覆盖多语言混合内容场景。
- 关键词引导式转录(Keyterm Prompting):用户最多可预设100个专业术语、品牌名称或技术词汇,模型将结合语境智能判断并精准还原这些关键表达,大幅提升垂直领域文本质量。
- 内置细粒度实体识别:支持识别涵盖个人身份、医疗健康、金融支付等在内的56类敏感实体,并为每个实体标注毫秒级时间戳,便于后续合规审查与内容编辑。
- 多语种无缝混识:无需人工切分或标注语种,即可自动识别并准确转录同一音频文件中交替出现的多种语言内容。
- 企业级增强能力:集成智能说话人分离、字级别精确时间轴、动态非语音事件标签(如笑声、脚步声、键盘敲击等),并通过SOC 2、ISO/IEC 27001、PCI DSS Level 1、HIPAA、GDPR等多项权威安全与隐私认证,支持零数据留存模式。
- 开箱即用与灵活接入:Scribe v2已上线ElevenLabs Studio用户界面,同时开放标准化API接口,供开发者快速集成至自有系统。
此外,为适配实时交互类应用场景(如AI Agent对话流处理),最新同步推出了Scribe v2 Realtime版本,针对极低延迟与流式语音输入进行了专项优化。
了解更多:
源码获取:




