清华大学智能产业研究院(AIR)的蓝艳艳教授团队与生命科学院、化学系的科研力量协同创新,成功构建了一套由人工智能驱动的高通量药物虚拟筛选平台——DrugCLIP。这项突破性研究成果以《深度对比学习赋能全基因组尺度药物虚拟筛选》(Deep contrastive learning enables genome-wide virtual screening)为题,在线发表于国际顶级学术期刊《科学》(Science)。
在当前的药物研发领域,已有明确治疗靶点的药物仅覆盖了人类可成药靶点的大约10%。面对数以万计尚待深入探索的潜在靶点,如何在浩瀚的化学空间中高效识别出具有潜力的苗头化合物,已成为制约新药开发进程的核心瓶颈之一。
研究介绍显示,与传统虚拟筛选方法相比,DrugCLIP平台的计算速度实现了百万倍量级的提升,同时在预测精度方面也取得了跨越式的进步。依托该平台,研究团队首次实现了覆盖全人类基因组范围的系统性药物虚拟筛选,为原创性药物的发现开辟了一条全新的技术路径。
DrugCLIP首次打通了从蛋白质三维结构预测到候选药物识别的端到端流程,真正达成了基因组尺度的全景式虚拟筛选目标。
在硬件部署层面,仅需配置一个拥有128核中央处理器(CPU)与8张图形处理器(GPU)的单计算节点,DrugCLIP即可完成每日万亿量级的蛋白质结合口袋-小分子对的亲和力评分任务。其核心技术突破在于:将传统依赖物理力场的分子对接过程,重构为蛋白质口袋表征与小分子表征在统一向量空间中的高效语义匹配,从而在保持高预测精度的同时,将整体运算效率提升了百万倍。
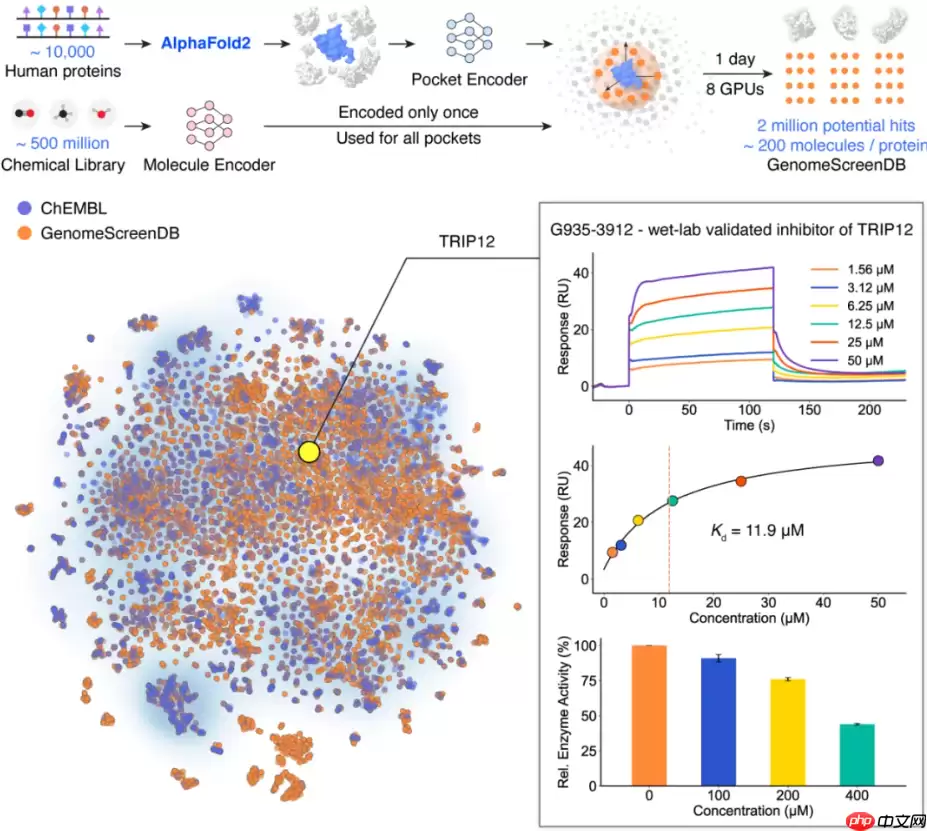
借助DrugCLIP平台,研究团队首次完成了面向人类全基因组的规模化药物虚拟筛选。整个流程涵盖了约1万个蛋白质靶标、2万个蛋白质结合口袋,并对超过5亿个具有类药性的小分子进行了系统评估,最终成功富集出逾200万个具备潜在生物活性的候选分子。由此构建的蛋白质-配体互作筛选数据库,是目前全球已公开的最大规模同类资源库,现已面向全球科研界免费开放共享。
源码地址:




