Z Lab 近日开源了全新的推测解码框架 DFlash,该框架创新性地采用轻量级的 Block Diffusion 模型来并行生成草稿序列,旨在攻克自回归大语言模型在推理过程中因串行化草稿生成而导致的性能瓶颈。
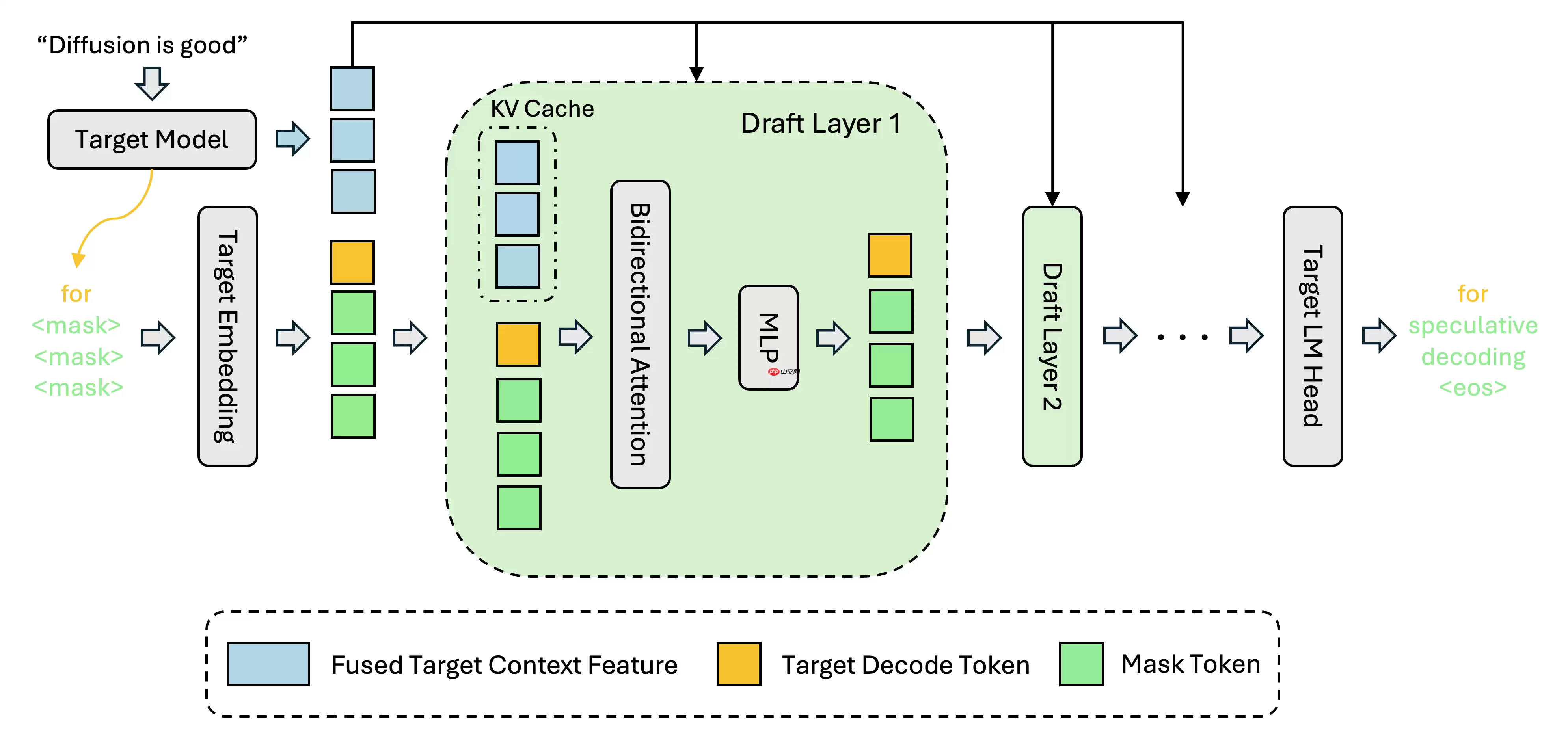
DFlash 的核心突破在于,它将目标模型的隐层特征巧妙地融入到草稿生成阶段,作为上下文条件进行建模,从而实现了高质量、高效率的并行草稿预测。
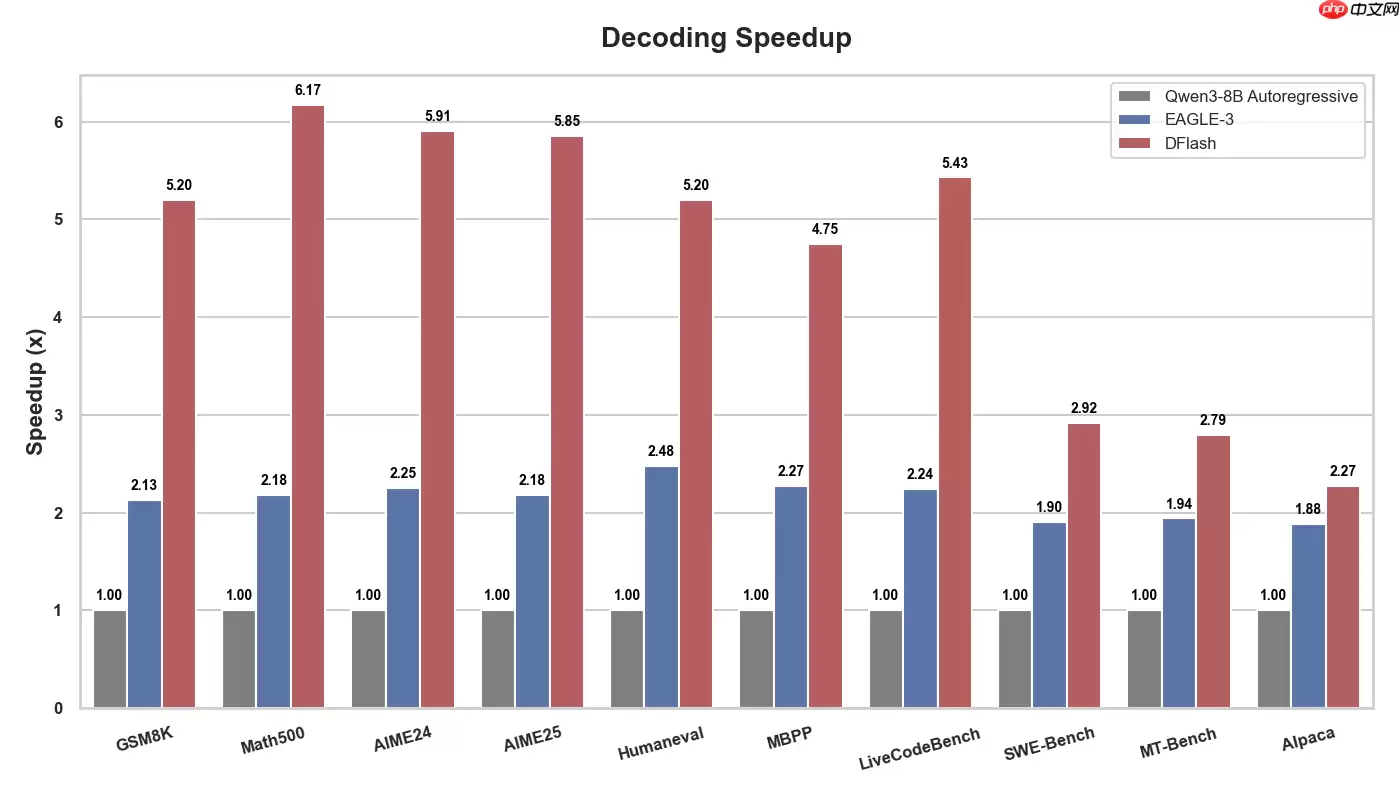
根据最新的测试数据,DFlash 在 Qwen3-8B 模型上实现了高达 6.17 倍的无损推理加速,其解码吞吐量相比当前最优的推测解码方案 EAGLE-3 提升了近 2.5 倍。目前该项目已在 GitHub 开源,并同步发布了适配 Qwen3-4B 与 Qwen3-8B 的预训练草稿模型。相关的技术论文正在整理中,即将正式对外发布。
研发团队透露,DFlash 正在紧锣密鼓地接入 vLLM 推理引擎,并且已经规划好对大规模混合专家(MoE)架构模型的完整支持路线图。
项目源码已公开发布。




