
新智元报道
编辑:LRST
【新智元导读】DeepSeek-OCR的视觉文本压缩(VTC)技术,能够通过将文本编码为视觉Token,实现高达10倍的压缩率,大幅降低大模型处理长文本的成本。然而,视觉语言模型能否真正理解压缩后的高密度信息?中国科学院自动化所等机构推出了VTCBench基准测试,旨在评估模型在视觉空间中的认知极限,涵盖了信息检索、关联推理和长期记忆三大核心任务。
近期,凭借其创新的“视觉文本压缩”(Vision-Text Compression,VTC)范式,DeepSeek-OCR引发了技术圈的广泛关注。这一范式以极少的视觉Token便实现了高效的文本信息编码,为长文本处理开辟了全新的技术路径。
这一突破性进展让大模型处理超长文档的成本大幅降低,但同时也引出了一个深层次的疑问:当长文本被高度压缩为二维图像后,视觉语言模型(VLM)真的能准确理解其中蕴含的内容吗?
为了探究这一问题,来自中国科学院自动化所、中国香港科学院创新研究院等机构的研究团队,联合推出了首个专门针对视觉-文本压缩范式的基准测试——VTCBench。

论文链接:https://arxiv.org/abs/2512.15649
VTCBench链接: https://github.com/Moenupa/VTCBench
VLMEvalKit链接:https://github.com/bjzhb666/VLMEvalKit
Huggingface链接: https://huggingface.co/datasets/MLLM-CL/VTCBench
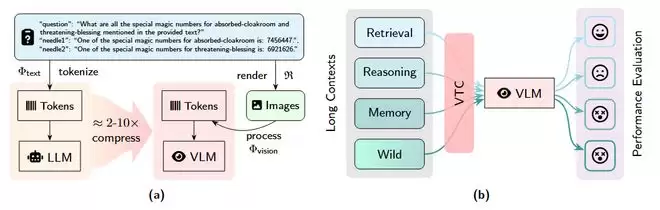
图 1:视觉-文本压缩 (VTC) 流程演示及VTCBench
与传统的纯文本处理方式不同,VTC范式(如DeepSeek-OCR)会先将长文档渲染(Rendering)为高密度的二维图像,再由视觉编码器将其转化为少量的视觉Token。这一技术能实现2到10倍的Token压缩率,显著降低了长文本处理时的计算与显存开销。
目前,VTCBench已在GitHub和Huggingface全面开源。其衍生版本VTCBench-Wild作为一个统一的、全方位评估模型在复杂现实场景下视觉文本压缩鲁棒性的工具,现已集成到VLMevalkit中。
核心使命
衡量“看得见”之后的“看得懂”
当前的VLM或许能出色地完成OCR识别任务,但在处理经过VTC压缩后的高密度信息时,其对长文本的深度理解能力仍有待验证。
VTCBench通过三大任务,系统性评估模型在视觉空间中的认知极限:
1. VTC-Retrieval (信息检索):在视觉“大海”中精准寻找特定事实的“针”(Needle-in-a-Haystack),检验模型对空间分布信息的捕捉能力。
2. VTC-Reasoning (关联推理):挑战模型在几乎没有文本重叠的情况下,通过上下文关联推理寻找事实,超越简单的词汇索引。
3. VTC-Memory (长期记忆):模拟超长对话场景,评估模型在视觉压缩框架下,抵御时间与结构性信息衰减的能力。
此外,团队同步推出了VTCBench-Wild,引入了99种不同的渲染配置(涵盖多种字体、字号、行高及背景),全方位检测模型在复杂现实场景下的鲁棒性。
揭秘视觉压缩背后的认知瓶颈
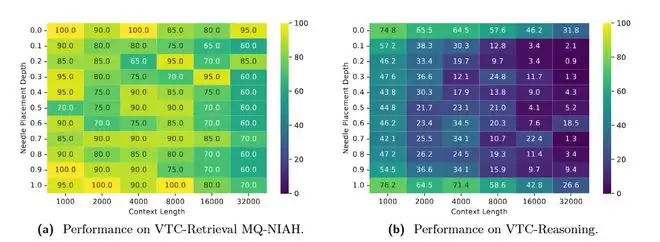
图 2:VTCBench针对模型在长图像中检索信息的热力图。横轴代表上下文长度,纵轴代表关键事实(Needle)在文档中的深度。展现了模型表现的“迷失”与“突破”。
测试结果呈现出显著的“U型曲线”现象:与纯文本模型类似,视觉语言模型(VLM)能够精准捕捉开头和结尾的信息,但对于中间部分的事实,其理解能力会随着文档变长而剧烈衰退。这证明即使在视觉空间,模型依然存在严重的“空间注意力偏见”,这将是未来VTC架构优化需要攻克的关键方向。
行业洞察
视觉压缩是长文本的终极答案吗?
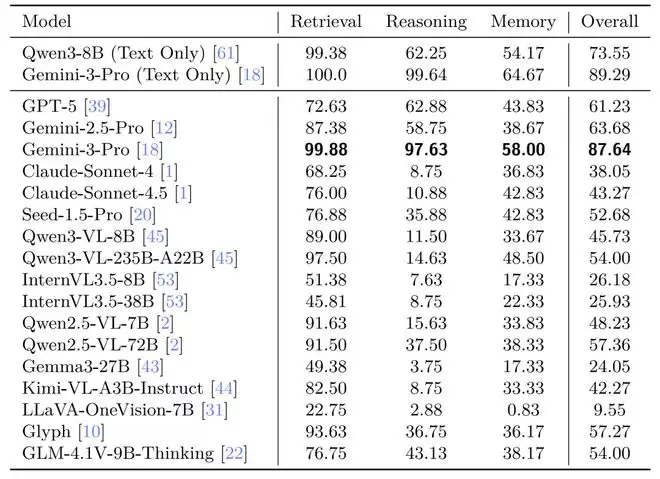
通过对GPT、Gemini、Claude、QwenVL、InternVL、Gemma、KimiVL、Seed1.5等十余种顶尖模型的深度评测,我们可以发现:
尽管VTC极大提升了效率,但现有VLM在复杂推理和记忆任务上的表现仍普遍弱于纯文本大模型;
消融实验证明,信息密度是决定模型性能的关键因素,直接影响视觉编码器的识别精度;
Gemini-3-Pro在VTCBench-Wild上表现惊艳,其视觉理解能力已几乎追平其纯文本基准,证明了VTC是实现大规模长文本处理的极其可行的路径!
总结
如果说传统的长文本处理是“逐字阅读”,那么DeepSeek-OCR所引领的VTC范式便是“过目成诵”式的摄影记忆。VTCBench的出现,正是为了确保模型在拥有这种“超能力”的同时,依然能够读懂字里行间的微言大义。
参考资料:
https://arxiv.org/abs/2512.15649
秒追ASI
⭐点赞、转发、在看一键三连⭐
点亮星标,锁定新智元极速推送!