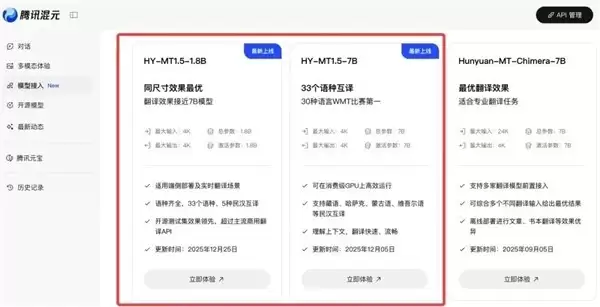
腾讯混元今天正式宣布,其翻译大模型1.5版本已全面开源。此次发布包含两个型号:Tencent-HY-MT1.5-1.8B 与 Tencent-HY-MT1.5-7B。这两款模型均已上线腾讯混元平台,并同步在Github和Huggingface等开源社区提供下载,供开发者免费使用与研究。
新版模型的能力覆盖范围得到显著拓展,它支持33种语言间的互译,并且特别优化了5种少数民族语言与汉语之间的翻译功能。除了中文、英文、日语等常见语种,其语言库还涵盖了捷克语、马拉地语、爱沙尼亚语、冰岛语等使用范围相对较小的语言,进一步增强了多语言服务的实用性与包容性。
其中,Tencent-HY-MT1.5-1.8B模型专为手机等移动终端进行了深度优化。经过量化处理后,它可以在本地设备上高效部署,完美支持离线状态下的实时翻译任务。该模型仅需1GB内存即可稳定运行,在极小参数量的条件下,其翻译质量已超越多数商业翻译接口。在效率方面优势尤其明显,处理50个token的平均响应时间仅为0.18秒,相比其他主流模型约0.4秒的耗时大幅缩短,展现出更高的推理效率和成本效益。
此外,最新公开的测试结果显示,该模型在实际翻译质量上也优于部分设备内置的离线翻译方案。
而 Tencent-HY-MT1.5-7B 模型则在前代基础上实现了显著的性能跃升,它是此前在WMT25赛事中赢得30个语种翻译冠军模型的进阶版本。本次升级重点优化了翻译的准确性与流畅度,有效降低了译文中出现冗余信息及语种混淆的问题,整体可用性得到进一步增强。
据悉,在实际应用场景中,结合使用1.8B与7B两个不同规模的模型,能够实现端侧与云侧的协同部署,从而提升系统在不同环境下的输出一致性与运行稳定性。




