12月24日消息,阿里对其语音模型家族Qwen3-TTS进行了全新升级,同时推出了两款重磅新品:支持音色创造的Qwen3-TTS-VD和专注音色克隆的Qwen3-TTS-VC。
在生成效果方面,这两款新模型的整体表现已经明显优于GPT-4o。
最新的Qwen3-TTS模型实现了用户自主设计声音和像素级音色模仿的强大能力,甚至连动物的“原声”也能被重现,开口说出人话。
其生成语音音色自然、效果稳定、效率极高,将有力推动语音大模型在有声小说、AI漫画、影視配音等多个专业领域的商业化应用。
其中,音色创造模型支持用户通过简单的自然语言描述,即可生成定制化的声音形象,具备极强的可控生成能力。
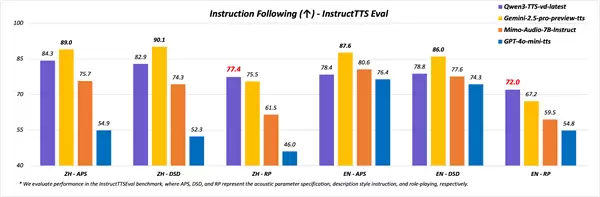
在指令遵循评测InstructTTS-Eval中,Qwen3-TTS的综合表现显著优于GPT-4o-mini-tts、Mimo-audio-7b-instruct等同类竞品。
而在强调表达一致性与沉浸感的角色扮演测试中,该模型的整体效果更是超越了Gemini-2.5-pro-preview-tts。
音色克隆模型则专注于“声音模仿”这一核心功能,仅需3秒的原始语音样本,便能精准复刻出原始声线。
在MiniMax TTS Multilingual Test Set测试集中,Qwen3-TTS-VC展现了其在多语言语音准确性与稳定性方面的显著优势。
其平均词错误率(WER)指标表现突出,整体结果全面优于MiniMax、ElevenLabs以及GPT-4o-Audio-Preview。

此外,Qwen3-TTS-VC还能自动生成英语、德语、意大利语、葡萄牙语、西班牙语、日语、韩语、法语、俄语等9种语言的语音。
更值得一提的是,它连动物的叫声也能复刻。用户只需录入家中宠物的原始叫声,就能利用模型让它“开口说人话”。
目前,两款模型均在阿里云百炼平台上架了Flash版本API,响应速度极快,完全能够满足工业级的语音合成需求。
千问语音生成模型系列Qwen3-TTS仍在持续升级,目前已支持50种音色、10大主流语言,以及闽南语、吴语、粤语、四川话、北京话、南京话、天津话、陕西话等8大方言,能够真实还原各地的口音特色与语言神韵。





