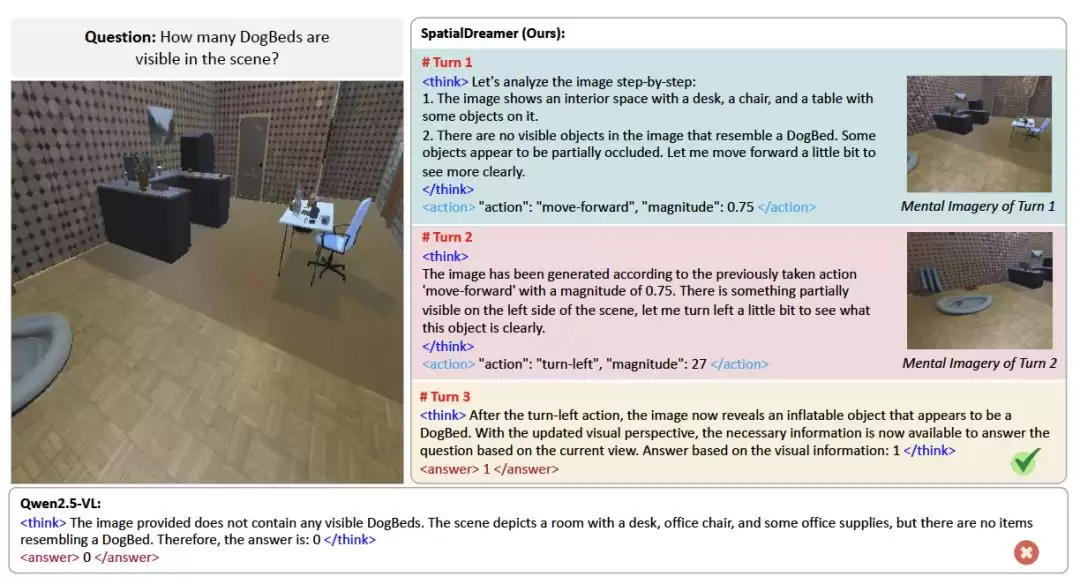
【导读】中山大学等研究机构推出的SpatialDreamer,凭借其主动心理想象与空间推理能力,显著提升了AI在复杂空间任务中的表现。该技术通过模拟人类主动探索、想象和推理的认知过程,有效解决了现有模型在视角变换等任务中因视角单一而推理受限的困境,为人工智能的空间智能发展开辟了新方向。
尽管多模态大语言模型在场景理解方面已取得长足进步,但在需要心理模拟的复杂空间推理任务上,其表现仍有明显局限。
现有方法多依赖于对空间数据的被动观察,缺乏人类在空间认知中所特有的主动想象与动态更新内部表征的能力。
例如,在需要变换视角以判断遮挡物体位置的任务中,现有模型常因视角固定而推理失败。
为此,MBZUAI与中山大学的研究团队提出了SpatialDreamer,这是一个基于强化学习的框架,旨在通过主动探索、视觉想象与证据融合的闭环过程,赋予MLLMs类人的空间心理模拟能力。

论文链接: https://arxiv.org/pdf/2512.07733
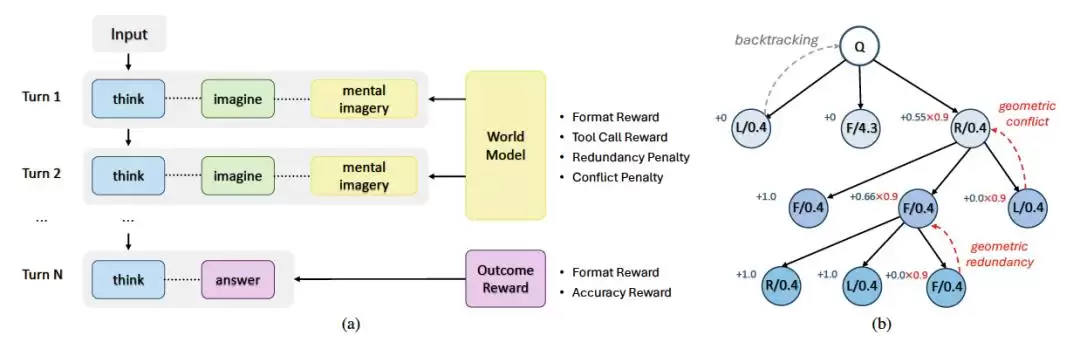
SpatialDreamer模拟人类的空间认知过程,构建了一个包含以下三个步骤的闭环推理流程:
1) 探索:模型根据当前场景推理出最优的自我中心动作(如“前进0.75米”或“左转45度”);
2) 想象:调用世界模型生成执行动作后的新视角图像;
3) 推理:整合所有累积的视觉证据,生成最终答案。
该过程使模型从“被动观察”转向“主动目标导向的想象”,实现在内部三维环境中自主决定“去哪儿看、看什么、如何推理”。
为解决长序列推理任务中奖励稀疏的问题,研究团队提出了GeoPO,一种结合树状采样结构与几何一致性约束的策略优化方法:
1) 树状采样:每步采样多个动作分支,支持回溯与多路径探索;
2) 多级奖励设计:融合任务级奖励与步级奖励,提供细粒度反馈;
3) 几何惩罚机制:对冗余或冲突动作施加惩罚系数,鼓励高效轨迹生成。
GeoPO在提升模型性能的同时,也显著加快了训练收敛速度。
为进一步引导模型学习“思考-想象-回答”的模式,团队构建了SpatialDreamer-SFT数据集,包括单轮推理数据以及反思式推理数据。其中反思式推理通过“错误注入 → 自我纠正 → 重建推理链”的方式构建。
实验结果
研究团队在多个空间推理基准上验证了SpatialDreamer的有效性:
1) SAT:在真实与合成图像中均达到SOTA,平均准确率分别达93.9%与92.5%;
2) MindCube-Tiny:整体准确率84.9%,较基线模型Qwen2.5-VL-7B提升超过55%;
3) VSI-Bench:在物体计数、相对方向、路径规划等任务中全面领先,平均准确率62.2%。
迈向具备空间想象能力的通用智能
SpatialDreamer的意义不仅在于提升空间推理准确率,更关键的是:它证明了MLLMs可以通过“想象力”增强推理能力,向人类般的空间智能迈出了重要一步。
参考资料:https://arxiv.org/pdf/2512.07733




