据微信公众号“科创闵行”报道,北京时间12月19日,上海交通大学集成电路学院(信息与电子工程学院)图像通信与网络工程研究所的陈一耘课题组,在新一代算力芯片领域实现重大突破,成功研发出了首款支持大规模语义媒体生成模型的全光计算芯片。相关研究成果以“All-optical synthesis chip for large-scale intelligent semantic vision generation”(大规模智能语义视觉生成全光芯片)为题,发表在国际顶级学术期刊《科学》(Science)上。上海交通大学为论文的第一作者和通讯作者单位,陈一耘助理教授担纲第一作者及通讯作者。
随着深度神经网络和大规模生成模型的迅猛发展,人工智能正以前所未有的速度革新着世界。然而,生成模型规模的爆炸式增长,带来超高的算力与能耗需求,传统芯片架构的性能提升速度已难以跟上,形成了日益严峻的技术缺口。

为了突破算力与能耗的瓶颈,光计算等新型架构受到了广泛关注。但传统全光计算芯片主要局限于小规模和分类性任务,而采用光电级联或复用方案又会严重削弱光计算的速度优势。因此,“如何让下一代算力光芯片高效运行复杂生成模型”,成为了全球智能计算领域公认的核心挑战。
研究团队首次提出了名为LightGen的全光大规模语义生成芯片,这也是国际首次实现的大规模全光生成式AI芯片。它在一枚芯片上同时攻克了三个领域公认的瓶颈:百万级光学神经元的集成、全光维度的实时转换,以及无需真值的光芯片训练算法。
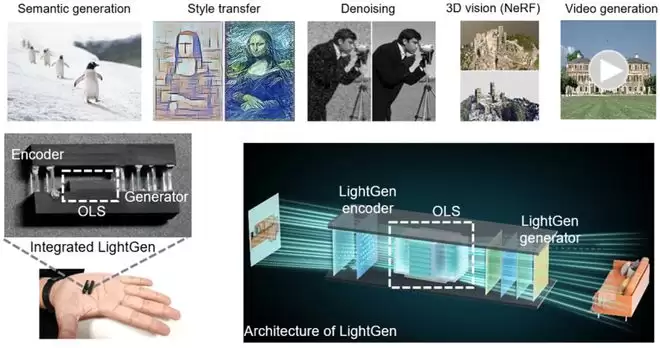
大规模全光生成计算芯片 LightGen
论文中的实验验证了全光芯片LightGen在多个大规模生成式任务上的能力,包括高分辨率(≥512×512)图像语义生成、3D场景生成(NeRF)、高清视频合成及语义调控、图像去噪、局部与全局特征迁移等功能。它不再依靠电信号辅助光生成,而是让光芯片完整地实现了从输入图像、语义理解、语义操控到全新媒体数据生成的端到端过程,真正赋予了光“理解”与“认知”语义的能力。
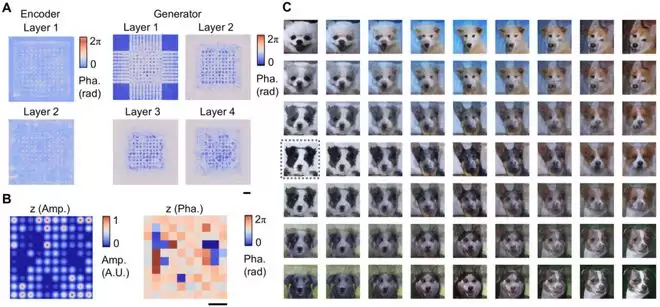
LightGen 生成的采样图像示例
此外,LightGen采用了极为严格的算力评价标准。在生成质量与电芯片上运行的Stable Diffusion、NeRF、Style Injection Diffusion等前沿电子神经网络相当的同时,它实现了全系统端到端耗时与能耗的显著降低。实测结果显示,即使采用性能较滞后的输入设备,LightGen相比顶尖数字芯片仍可实现两个数量级的算力与能效提升。而如果使用前沿设备消除信号输入瓶颈,理论上LightGen可实现算力提升7个数量级、能效提升8个数量级的性能跃升。这不仅直接展现了在不损失性能前提下替换现有顶尖芯片所能带来的巨大效能提升,也印证了在解决大规模集成、全光维度变换、无真值光场训练等关键技术难点后,全光片上实现大规模生成式网络具有里程碑式的重要意义。
该论文同时被《科学》(Science)最新一期选为高光论文重点报道。文中指出,生成式AI正加速融入生产生活,要让“下一代算力芯片”在现代人工智能社会中真正实用,关键就在于研制能够直接执行真实世界复杂任务的芯片——尤其是像大规模生成模型这类对端到端时延与能耗极为敏感的应用。面向这一目标,LightGen为新一代算力芯片助力前沿人工智能发展开辟了新路径,也为探索更高速度、更高能效的生成式智能计算提供了全新研究方向。
陈一耘博士长期致力于光计算领域的研究,专注于解决新一代算力芯片实现实际应用中的核心科学难点问题。其团队此前提出的全模拟光电芯片ACCEL(Nature 623 (7985), 48-57),在国际上首次通过实际测试验证了光计算在复杂智能任务中系统级算力的优越性,使光计算芯片的超高算力能效无损地融入成熟的数字社会。2024年,他们提出的PED(光编码解码器,Science Advances 9(7), eadf8437)光计算架构,更被《科学》子刊认证为“国际首个全光生成式神经网络”。基于上述研究积累,LightGen突破性地将全光芯片的适用边界拓展至大规模生成式神经网络领域,并已开始与工业界合作推动应用落地实践。
上海交通大学集成电路学院(信息与电子工程学院)陈一耘助理教授担任了论文的第一作者及通讯作者。翟广涛教授、张文军院士、博士生孙心瑶,以及清华大学硕士生谭龙涛、博士生姜一洲、博士后周银等研究人员均对本文做出了重要贡献。此项研究得到了多项国家级及上海市级科研项目的支持与资助。




