12月15日,通义大模型官方放出最新消息,宣布两款“百聆”语音模型正式开源,并迎来重磅升级。据介绍,只需录制3秒你的声音,就能让它无缝切换至不同语种、方言乃至情绪——无论是普通话、粤语、日语、英语的日常表达,还是开心、愤怒等情绪语调,它都能轻松驾驭,覆盖9种通用语言与18种方言。
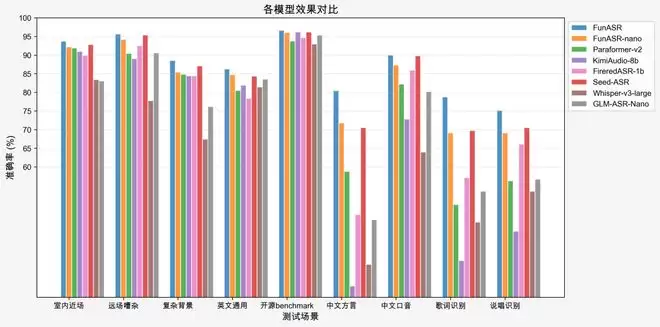
此次升级中,Fun-CosyVoice3模型实现了多方面能力提升:首包延迟降低了一半,中英文混合语音的识别准确率翻倍,并支持9种语言、18种方言口音、跨语种克隆及情感控制;Fun-ASR模型能力同样增强:在嘈杂环境下的识别准确率达到93%,新增歌词与演唱识别功能,可自由混说31种语言、覆盖多种方言口音,同时将其流式识别模型的首字延迟降至160毫秒。开源版本方面,Fun-CosyVoice3(0.5B)提供零样本音色克隆能力,支持本地部署与二次开发;Fun-ASR-Nano(0.8B)作为轻量化版本,推理成本更低,模型完全开源,支持本地部署与定制化微调。
根据我们获得的最新进展,本次Fun-CosyVoice3大模型完成了多项关键升级:
首包延迟降低50%,支持双向流式合成,真正实现“输入即发声”,适用于语音助手、直播配音、无障碍阅读等实时交互场景;中英文混合语音的词错误率相比之前大幅下降56.4%,无论是包含专业术语、大小写混排的文本,还是需要进行语码转换的句子,都能精准且自然地发音;在零样本语音合成评测中,内容一致性与音色相似度全面提升,复杂测试场景下的字符错误率相对降低26%,接近真人录音水平;支持9种通用语言、18种中文方言、9种情感控制,并具备跨语种音色复制能力——仅用一段普通话录音,即可生成粤语、日语、英语等其他语言的语音,且音色保持高度一致。
而此次开源的Fun-CosyVoice3-0.5B模型提供了零样本音色克隆功能,你只需提供一段3秒以上的参考音频,即可复刻其音色并合成新的语音,同时支持本地部署和二次开发。
Fun-ASR让AI真正“听得懂”。其基于数千小时真实语音数据训练,已在钉钉“AI听记”、视频会议等场景中大规模落地。最新版本重点优化了嘈杂环境鲁棒性、多语言自由混说、中文方言与口音覆盖、歌词识别、定制化能力,并将流式识别模型的首字延迟降低到160毫秒。
Fun-CosyVoice3-0.5B开源地址:
https://github.com/FunAudioLLM/CosyVoice(GitHub)https://funaudiollm.github.io/cosyvoice3/(GitHub.io)https://www.modelscope.cn/studios/FunAudioLLM/Fun-CosyVoice3-0.5B(体验 demo)https://modelscope.cn/models/FunAudioLLM/Fun-CosyVoice3-0.5B-2512(国内模型仓库)https://huggingface.co/FunAudioLLM/Fun-CosyVoice3-0.5B-2512(海外模型仓库)
Fun-ASR-Nano-0.8B开源地址:
https://github.com/FunAudioLLM/Fun-ASR(GitHub)https://funaudiollm.github.io/funasr/(GitHub.io)https://modelscope.cn/studios/FunAudioLLM/Fun-ASR-Nano/(国内体验 demo)https://huggingface.co/spaces/FunAudioLLM/Fun-ASR-Nano(海外体验 demo)https://modelscope.cn/models/FunAudioLLM/fun-asr-nano-2512(国内模型仓库)https://huggingface.co/FunAudioLLM/Fun-ASR-Nano-2512(海外模型仓库)




