12月14日消息,最近两年AI技术的爆发式增长,不仅重塑了人工智能产业,实际上也悄然改变了芯片技术的发展轨迹。然而,这一转向对于高性能计算(HPC)和科学计算领域来说,却未必是个好消息。
究其原因,在于NVIDIA近年来已将AI性能视作一切的核心,计算精度实际上在不断降低。以往比较GPU性能时,FP64和FP32精度还是核心指标;但步入AI时代,FP16、FP8乃至FP4精度才是重点。
我们此前曾提到,NVIDIA新一代显卡会转向FP4标准。从Blackwell架构开始,虽然也支持FP4和MXFP4两种格式,但重点推广的是NVFP4。它与E2M1+FP4结构相似,精度损失却微乎其微。
GB300在支持FP4后,性能提升了50%,精度相较FP8几乎没有损失,内存占用大幅减少了2-3倍,能效更是实现了50倍的提升。
但在FP64性能上,近几年的显卡,尤其是顶级产品,不仅没有提升,反而在倒退。HPCWire对这几代显卡进行了对比,如下图所示:
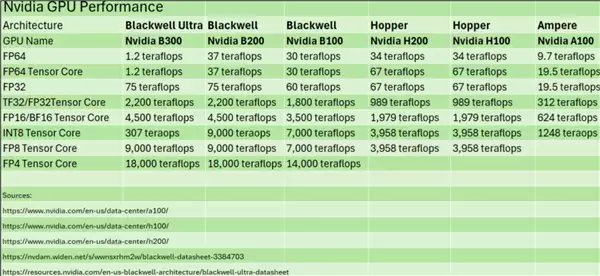
A100时代的FP64性能还有9.7 TFLOPS,H100和H200达到34 TFLOPS,B100、B200是30 TFLOPS,而B300则大幅降低到了1.2 TFLOPS。
这已经引发了学术界的抱怨。在SC25大会期间,TOP500发起人、田纳西大学教授Jack Dongarra就表示,NVIDIA从Hopper架构转向Blackwell时,并未实质性地提升FP64性能。
AI性能固然重要,但在科学计算领域,比如材料科学、气候建模、流体力学模拟等研究中,FP64性能是不可替代的。
对于这些质疑,NVIDIA负责HPC和AI超大规模基础设施解决方案的高级总监Dion Harris强调,他们并没有放弃64位计算,它依然是核心。
他提到十月份推出的cuBLAS,这是一个CUDA-X数学库,可以在矢量核心上模拟FP64计算,使用这个库可以让FP64性能提升1.8倍。
至于专业人士所期待的FP64性能硬件提升,Dion Harris提到NVIDIA未来的GPU会在核心底层提升FP64计算能力,但具体信息暂时不能透露。
明年三月份的GTC大会上,NVIDIA应该会公布下一代GPU架构了,或许在这方面会有所变化。





