金磊 发自 凹非寺
量子位 | 公众号 QbitAI
是时候给Transformer的大动脉动刀子了。
因为即便它享有当下AI世界基石的地位,但自身问题也是非常明显:
一旦遇到复杂的数学题或者需要多步逻辑推理的时候,就开始一本正经地胡说八道了……

问题究竟出在了哪里?
答案就藏在Transformer的核心机制里——Attention。
传统Attention机制本质上像是一种配对比较:每个词只和另一个词直接发生关系,生成一个注意力权重。
这种架构虽然擅长捕捉长距离依赖,但在建模复杂、多跳、多点之间的逻辑关系时却显得力不从心了。
例如它能轻松理解“A认识B”,但如果要它理解“张三通过李四认识了王五”,即多跳、多点之间的复杂、间接关系,它的脑回路就显得不够深,推理能力的天花板瞬间触顶。
现在,这个天花板,被华为诺亚方舟实验室捅破了!
因为就在最近,团队祭出了一种全新架构,叫做Nexus,即高阶注意力机制(Higher-Order Attention Mechanism)。

它可以说是直接狙击了Attention机制的核心痛点,使用更高阶注意力,就能有效地建模多跳、多点之间的复杂关联。
并且从实验结果来看,效果也是有点惊艳在身上的。
只要换上Nexus这个新架构,模型在数学和科学等复杂推理任务上的能力,都能立马实现大幅飙升,而且还是参数零增的那种。
妙哉,着实妙哉。
接下来,就让我们一同来深入了解一下Nexus的精妙一刀。
高阶注意力机制砍出的精妙一刀
要理解高阶的意义,我们必须先回顾传统自注意力机制的根本缺陷。
标准的自注意力机制本质上是将输入序列X分别通过三个线性变换WQ,WK,WV生成Query(Q)、Key(K)、Value(V),再通过softmax计算注意力权重:

但这里就出现了一个关键的问题:Q和K都是静态的、与上下文无关的线性投影。
也就是说,某个token的Query向量仅由它自己决定,无法感知其他token的存在;这导致注意力权重只能反映两两之间的直接关系。
精妙第一刀:Q和K的革新
华为诺亚方舟实验室的第一个刀法,就精妙地砍在了这里:Nexus让Q和K的生成过程本身也变成一个注意力操作。
换句话说,token在计算最终的Q和K之前,会先进行一次“预推理”;这个过程,其实就是一个嵌套的自注意力机制。
Token首先通过这个内部循环,从全局上下文中聚合信息,形成一个更加精炼、更具上下文感知能力的表示,然后再用这个表示去计算最终的Q和K。
这就好比,在你问我答(Q和K计算Attention)之前,每个token都先在内部进行了深思熟虑,充分吸收了它在整个序列中的环境信息。
这样生成的Q和K,自然就摆脱了线性投影的僵硬,具备了捕捉复杂关系的动态性。
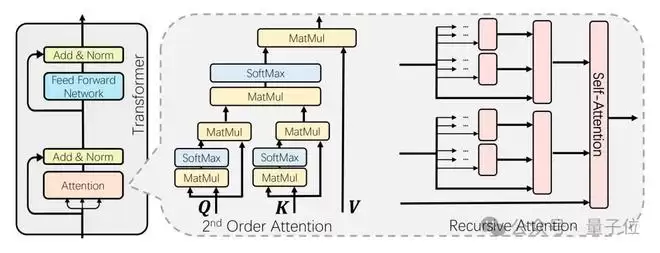
精妙第二刀:巧用递归框架
Nexus架构最精妙之处,还在于它的递归框架(Recursive Framework)。
这个内部注意力循环可以被递归地来嵌套。
如果我们将一层Attention视为一阶关系(A认识B),那么将Attention的输出作为下一层Attention的输入,就可以构建二阶关系(张三通过李四认识王五),乃至更高阶的关系。
在Nexus中,这种递归嵌套被巧妙地集成在一个单层结构中,形成了一个层次化的推理链。
论文进一步将上述过程递归化,定义第m阶注意力为:
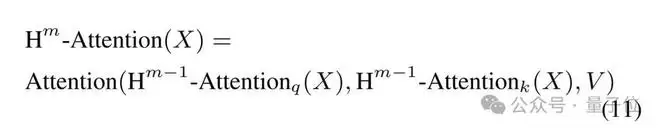
其中,m=1就是标准注意力;m=2表示Q和K由一次内层注意力生成;m=3表示Q和K由二阶注意力生成,相当于“注意力的注意力的注意力”。
这种结构天然支持多跳推理链,就像人在解一道数学题时,先理解题干中的关键变量(第1层),再思考它们之间的公式关系(第2层),最后验证整体逻辑是否自洽(第3层)。
精妙第三刀:不增参数
复杂架构往往意味着更高的计算开销和更多的参数量,但Nexus通过精巧的设计,完全规避了这些问题——权重共享策略。
具体来说,无论是内层还是外层的注意力模块,都复用同一组投影权重WQ,WK,WV。
这意味着,尽管计算路径更复杂,但模型参数量和原始Transformer完全一致。
这种设计背后有一个关键假设:无论处于递归的哪一层,将token投影为Query或Key的语义变换方式是相似的。
团队通过实验证明,这一假设是成立的。
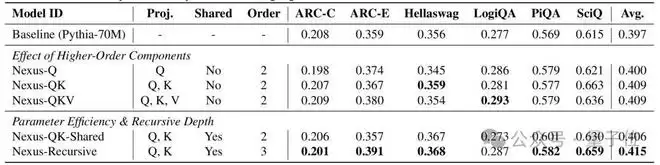
在Pythia-70M的消融实验中,使用权重共享的Nexus-QK-Shared版本,平均准确率仍比基线高出近1个百分点,而参数量毫无增加。
这就让Nexus成为了一种极其高效的表达密度提升器——用相同的参数,实现更强的推理能力。
只要换上Nexus,推理效果立竿见影
那么Nexus的效果到底如何?
论文在两个维度做了验证:从零训练的小模型,以及对已有大模型的架构改造。
小模型全面领先
研究团队在 Pythia 系列(70M 到 1B)上从头训练 Nexus,并在六个标准推理数据集上评估:ARC-C、ARC-E、HellaSwag、LogiQA、PiQA和SciQ。
结果非常一致:Nexus 在所有规模上都优于原始Transformer。
尤其在需要多步推理或科学常识的任务中提升显著。例如:
在SciQ(科学问答)上,70M模型准确率从61.5%提升至68.5%,提升7个百分点;在PiQA(物理常识推理)上,1B模型从62.5%提升至63.6%。
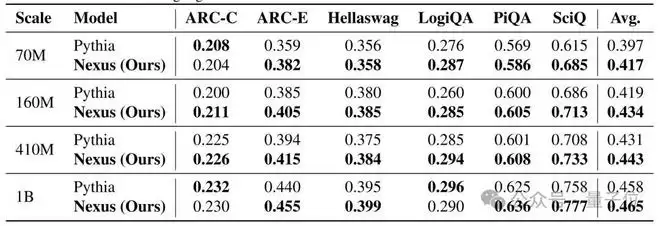
这说明Nexus特别擅长处理那些不能靠表面模式匹配解决的问题,是真的有在做推理。
大模型改装即用
面对规模更大的模型,Nexus还体现出了即插即用的能力。
团队将Qwen2.5的1.5B和7B版本的标准注意力层直接替换为Nexus结构,仅在SFT(监督微调)阶段进行训练,未改动预训练权重。
结果表明,在三个高难度数学推理基准上(MATH-500、AIME24、GPQA-Diamond),Nexus 均带来稳定提升:
Qwen2.5-1.5B在MATH-500上准确率从78.6% → 80.1%;Qwen2.5-7B在AIME24上从 45.2% → 47.5%。
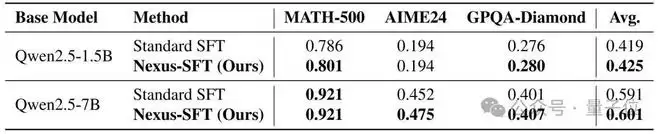
尤其值得注意的是AIME24的提升,因为这类题目要求严格的多步逻辑推导,错误一步就全盘皆输。Nexus 的改进说明,它确实在内部构建了更连贯的推理链。
从这一层面来看,Nexus不仅是一个新训练范式,还是一套架构升级套件。你不用重新训练一个千亿模型,只需在微调阶段替换注意力层,就能解锁更强的推理能力。
推理能力可内生于架构
虽然Nexus目前聚焦于语言模型,但其思想具有普适性。
高阶关系建模在视觉、图神经网络、多模态任务中同样关键;例如,在视频理解中,“A看到B打了C” 就是一个典型的三元关系,传统Attention难以直接捕捉。
华为诺亚团队表示,下一步将探索Nexus在视觉Transformer和多模态大模型中的应用,并优化其计算效率。
Transformer 的智商天花板,或许从来不在参数量,而在其注意力机制的表达能力。华为诺亚的 Nexus,用一种优雅而高效的方式,为这一核心模块注入了高阶推理能力。
它不靠堆料,不靠提示工程,而是从架构底层重构了模型的思考方式。
因此,Nexus也提醒了我们:有时候,聪明的架构比规模的大小更重要。
声明:包含AI生成内容