12月8日,美团LongCat团队正式宣布开源其图像生成与编辑模型LongCat-Image。这款模型拥有60亿参数,其独特之处在于采用了一套统一的架构,能够同时处理文本生成图像和基于自然语言指令进行图像编辑的任务。
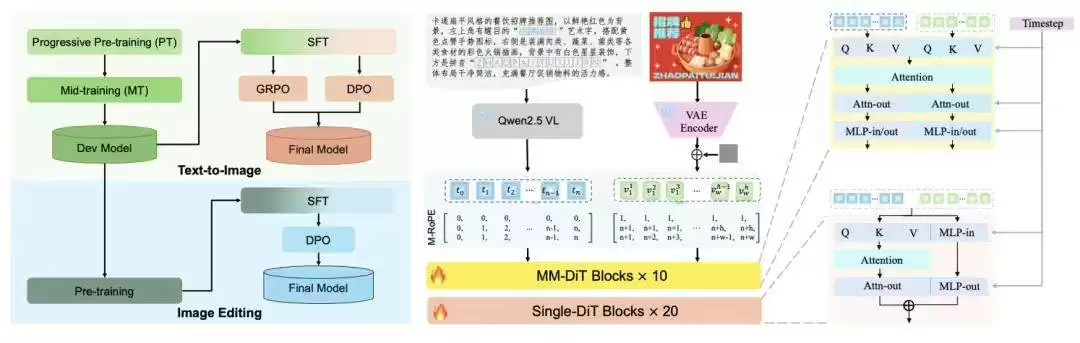
模型架构解读
根据介绍,LongCat-Image采用了图文生成与图像编辑同源的混合骨干架构(MM-DiT+Single-DiT),并整合了视觉语言模型条件编码器。它的核心技术创新点主要包括:
1. 生成与编辑合二为一:模型不仅能够根据文本提示生成图像,还可以通过自然语言指令对图像进行多轮精细编辑。官方列举了包括对象添加/移除、风格迁移、背景替换、文字修改在内的15类编辑任务,并声称在多轮编辑过程中能有效保持图像风格与光照的一致性。

风格迁移与属性编辑能力对比
2. 强大的中文文本渲染能力:该模型特别强调对中文文本生成的支持,宣称能够准确处理标准汉字、生僻字以及部分书法字体,并能根据场景自动调整字体、大小和排版。在技术实现上,模型通过预训练阶段学习字形轮廓,并在后续训练中引入大量真实世界的文本图像数据,以提升其泛化与应用能力。

文字生成效果对比
3. 高效的输出与优秀质量:通过模型结构轻量化与训练策略优化,该模型宣称可在消费级GPU上实现高效推理,并生成具备“摄影棚级别”丰富细节的高质量图像。

图像生成综合能力对比
在性能评估方面,官方公布了部分基准测试数据:
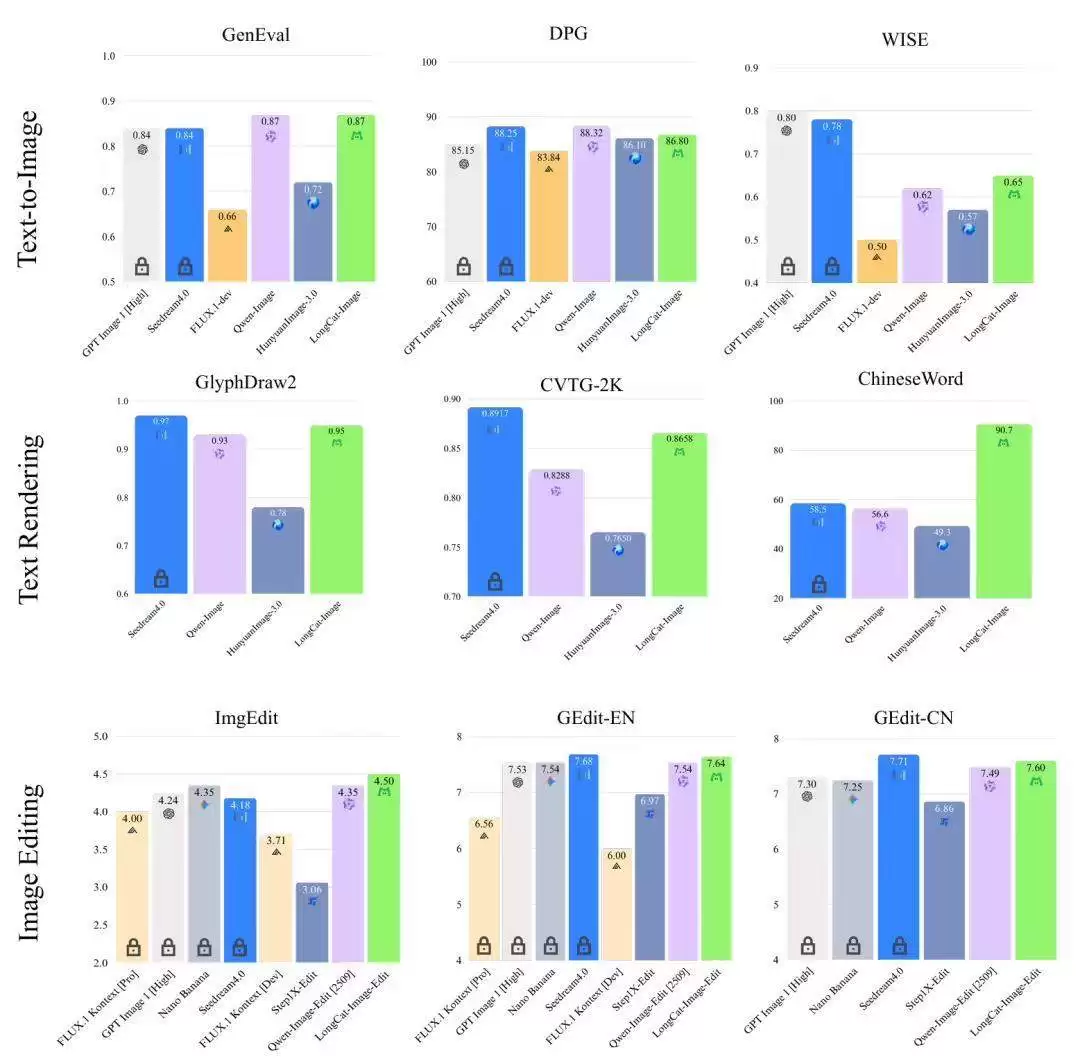
1. 在图像编辑基准测试GEdit-Bench和ImgEdit-Bench中,LongCat-Image得分分别为中英文综合7.60/7.64分以及专项4.50分,均达到了开源模型中的领先水平。
2. 在中文文本渲染专项测评ChineseWord中,其得分高达90.7分。
3. 在文生图基础能力测试GenEval和DPG-Bench中,其得分分别为0.87和86.8。
目前,该模型已在GitHub平台开源,用户可以通过LongCat APP或网页端(longcat.ai)体验其功能。团队表示,此次开源旨在支持从学术研究到商业应用的全流程探索,并诚挚邀请全球开发者社区参与共建。
此次开源动作,清晰地显示了美团在AIGC领域,尤其是针对中文市场及复杂图像编辑需求的技术布局。开源策略有助于其吸引开发者构建生态,并有望在快速发展的图像生成领域建立重要的影响力。




