经过三个多月的持续开发和优化,Apache Paimon 1.3 版本汇集了超过 500 项代码改进,为现代数据湖和 AI 应用场景带来了一系列关键能力提升,主要体现在以下五个核心方面。
Apache Paimon 1.3 版本凝聚了社区三个多月的开发心血,整合了 500 多项代码提交,显著增强了面向现代数据湖和 AI 应用的关键能力,具体体现在以下五大维度:
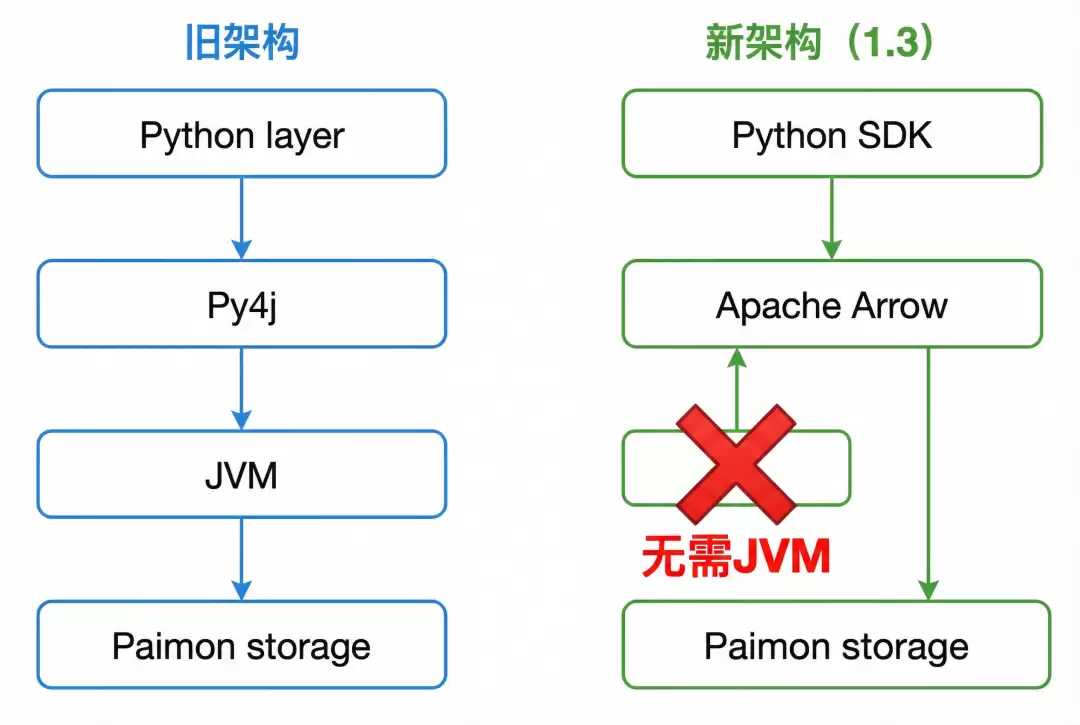
1.全新 PyPaimon:纯 Python SDK,摆脱 JVM 依赖
新版 Python SDK 进行了彻底重构,不再依赖 Py4j 和 JVM 环境,实现了完全原生的 Python 实现方案。
通过利用 Apache Arrow 的高效读写能力,新 SDK 在多数场景下的性能表现甚至优于 Java SDK。
当前版本已支持 Append 表的完整读写功能,主键表暂时提供基础去重操作,后续将持续扩展更多高级功能,并计划实现与 Ray、Daft 等 AI/数据处理引擎的深度集成。
2.Row Tracking + Data Evolution:轻量级列更新机制
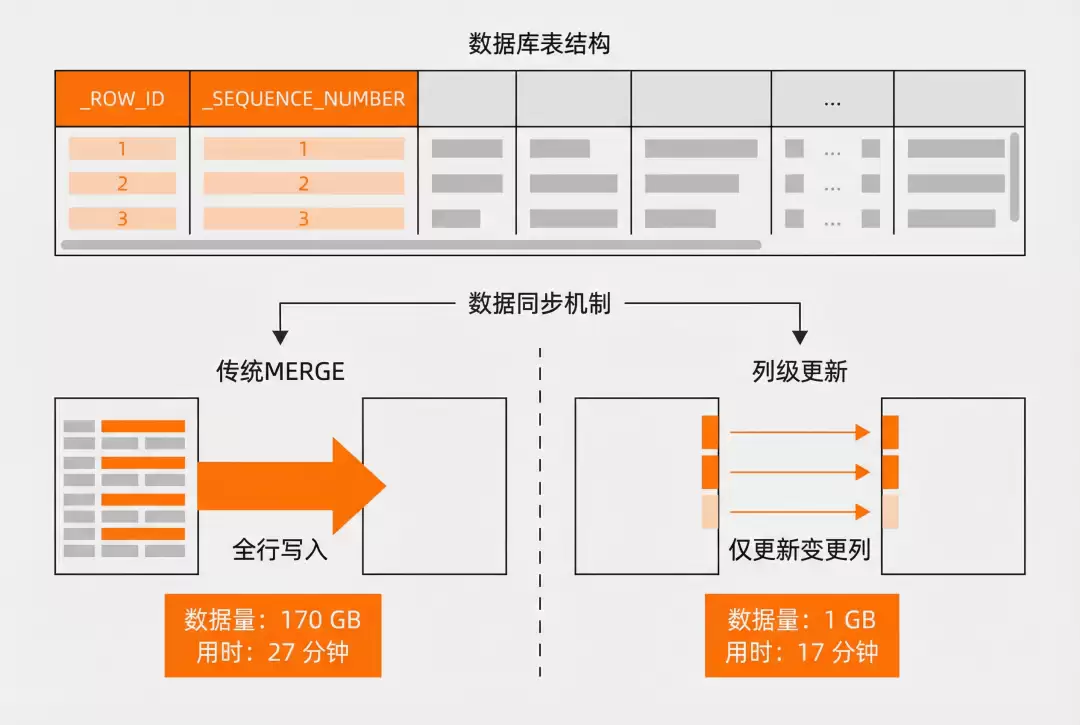
启用行追踪功能后,每一行数据会自动获得全局唯一的_ROW_ID和版本序列号_SEQUENCE_NUMBER,为后续高级功能奠定了坚实基础。
Data Evolution 机制允许在 Append 表中仅更新特定列数据,无需重写整行记录。例如执行 MERGE INTO 操作时只需写入变更字段,大幅降低了 I/O 开销与存储成本。
实际测试数据显示:MERGE 操作耗时从 27 分钟降至 17 分钟,存储占用从 170 GB 大幅缩减至 1 GB。
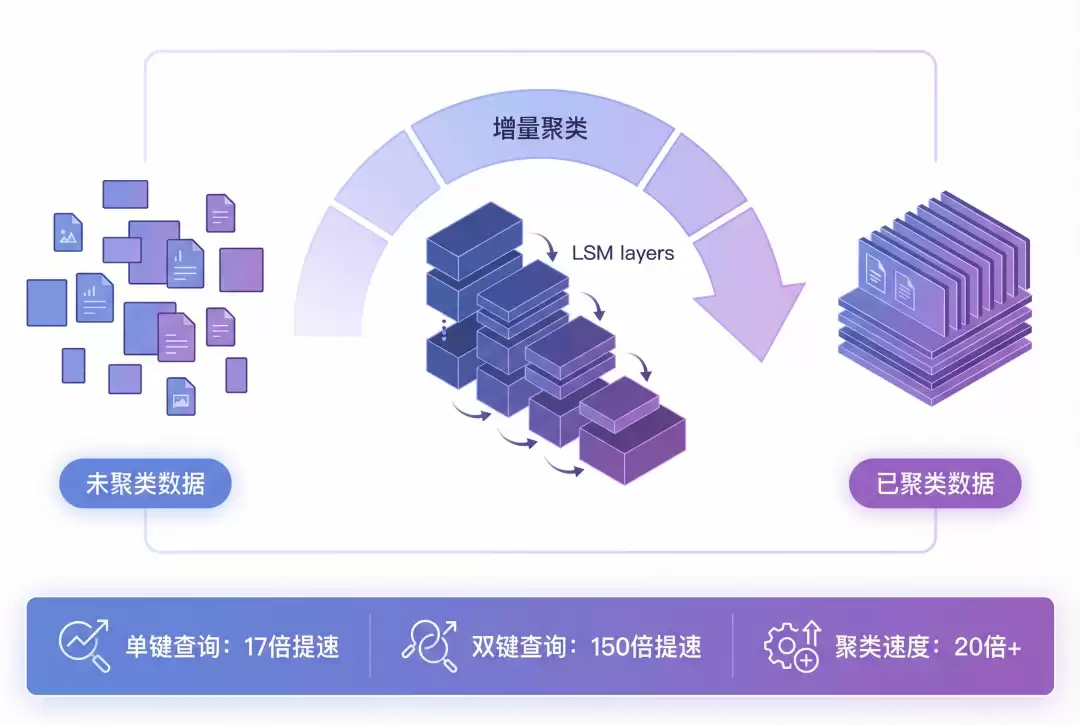
3.Incremental Clustering:Append 表的智能数据布局优化
引入增量聚类机制,在合并小文件的同时对数据按指定键进行排序,显著提升查询效率。
支持动态调整聚类键配置,无需全量重排;采用分层 LSM 结构有效控制写放大问题。
性能表现显著提升:单键过滤查询提速超过 17 倍;双键过滤查询性能提升高达 150 倍;聚类执行速度比全量排序快 20 倍以上。
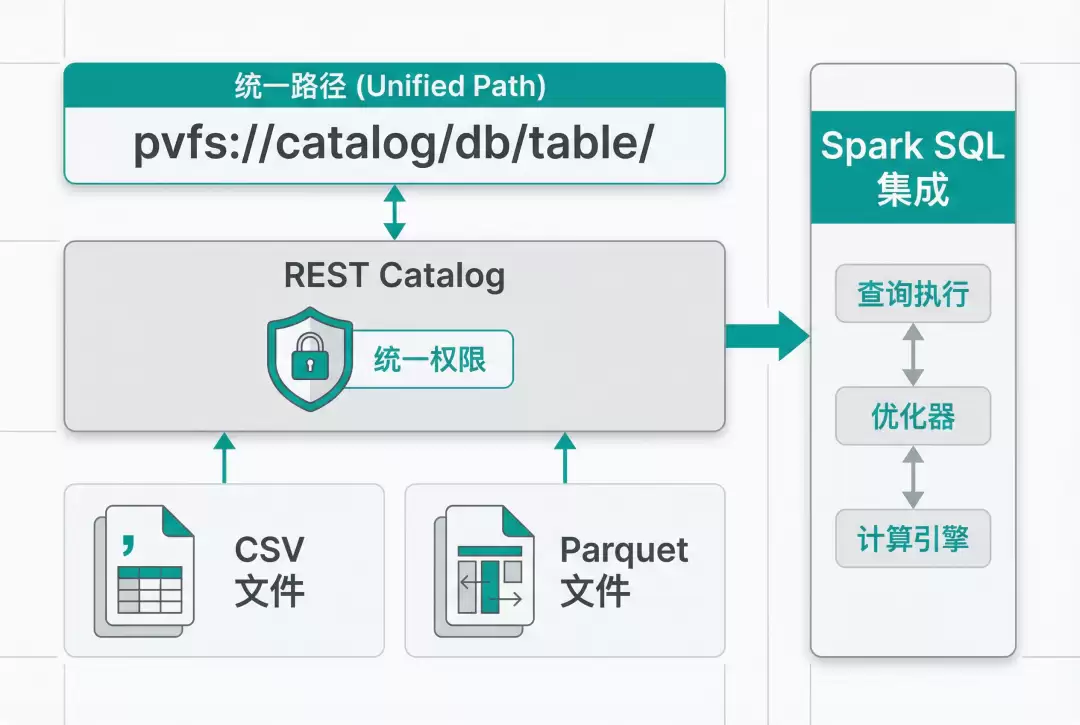
4.Virtual File System(PVFS):统一目录与权限管理
通过 pvfs://catalog/db/table/ 路径格式,用户可以直接访问 REST Catalog 管理下的底层文件(如 CSV、Parquet 等格式)。
所有访问操作均复用 Paimon 的权限管理体系,避免额外维护文件系统权限配置,既提升了安全性也增强了易用性。
目前已支持 Spark SQL 等引擎的无缝集成体验。
5.其他关键优化
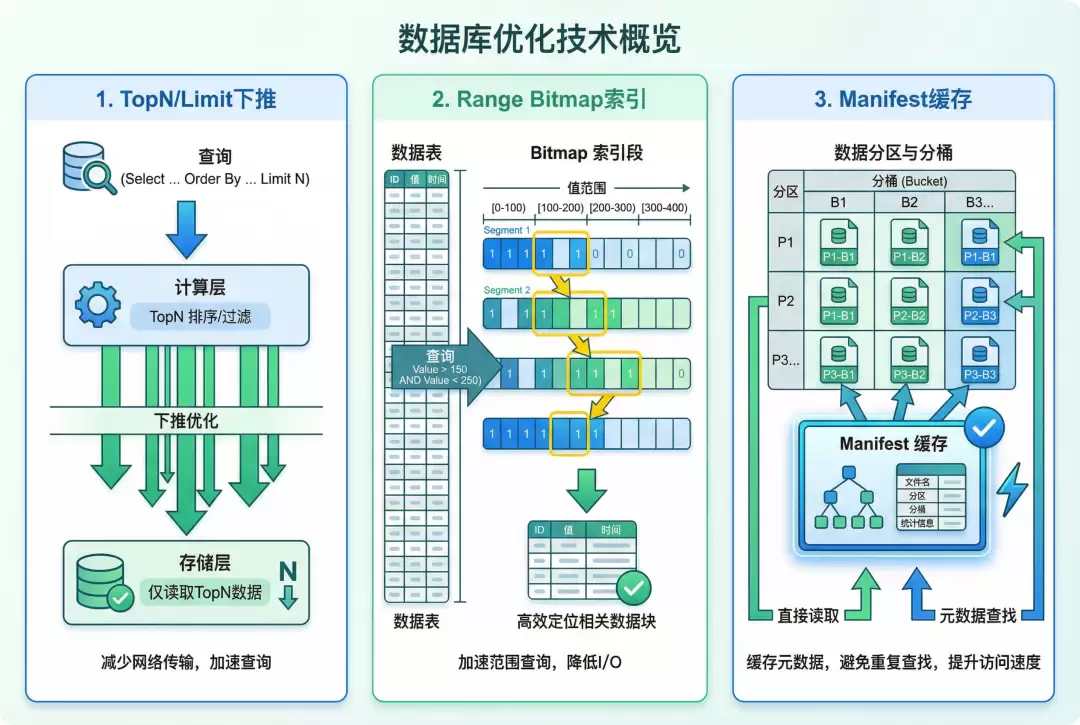
查询性能增强:支持 Spark 的 TopN 下推和 Limit 下推优化,引入高性能 Range Bitmap 索引。
清单文件缓存按分区和 Bucket 组织,加速 OLAP 查询响应速度。
修复了 MERGE INTO 与 COMPACT 并发执行时可能导致的数据一致性问题,特别是在 Deletion Vectors 模式下。
面向未来的方向
Paimon 正在积极拓展多模态数据湖能力,包括:
支持文本、图像、音视频等非结构化数据及其标签、向量的统一存储;开发 Blob 存储与全局索引(标量/向量/B树/Bitmap);深度集成 AI 生态,强化 Python SDK 与分布式训练/推理框架的协同能力。




