作为全球领先开源模型的共同选择,KTransformers印证了底层框架的坚实技术实力。趋境科技与清华大学联合开源的这一项目,现已成为Qwen、Kimi、智谱AI等多个主流大模型发布首日推荐的推理引擎,其工程实践与兼容性已被多家一体机产品线采纳,成为开发者、厂商与开源社区广泛复用的共建式底层架构。
技术实力与生态认可双重印证:成功入选“计算机系统领域奥斯卡”SOSP 2025
KTransformers作为高性能异构推理框架,专注于高效调度底层GPU、CPU、内存等多样化算力资源,让大模型能够在更低算力消耗、更灵活硬件配置下高效运行。其研究论文《KTransformers: Unleashing the Full Potential of CPU/GPU Hybrid Inference for MoE Models》成功获选享有“计算机系统领域奥斯卡”美誉的SOSP 2025,这一顶会过去数十年见证了虚拟化、分布式文件系统等多项里程碑技术的首次亮相,此次入选标志着KTransformers的技术实力获得全球顶尖学术圈的认可。
11月6日,月之暗面发布Kimi-K2-Thinking模型后,KTransformers迅速完成全链路适配,支持用户在单张显卡环境下完成推理任务,双卡配置即可进行LoRA微调训练,大幅降低定制化部署门槛。同时,趋境科技已完成该模型在昇腾NPU上的全面适配,提供完善的国产化推理解决方案,进一步拓宽其应用场景。
推理与微调双高效:KTransformers+SGLang实现高性能部署方案
在推理部署层面,KTransformers与主流推理框架SGLang于10月达成深度合作,双方架构已合并至同一代码分支。在Kimi-K2-1TB模型推理任务中,用户只需简单安装SGLang与KTransformers CPU内核,下载最新模型及量化权重,即可通过一条命令启动服务,且仅需单张消费级GPU搭配CPU。这一合作融合了GPU+CPU异构推理创新模式与全GPU传统推理方案,推动大模型推理向更高性能、更低成本演进,迈向更广泛的产业落地。
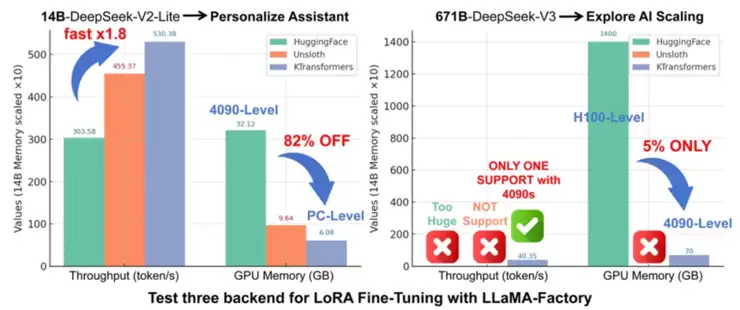
在微调部署层面,KTransformers与LLaMA-Factory完成深度集成,支持LoRA等轻量化微调方法,仅需约41GB显存与2TB内存,就能实现46.55 token/s的微调吞吐量。传统方案中,LoRA微调千亿模型成本高达数百万,而趋境的异构微调能力将资源需求降低到单张消费级GPU(如RTX 4090)即可满足,让高校、中小型实验室、初创公司甚至个人开发者都能参与大模型定制。该方案在DeepSeek-14B模型上展现了超越传统方案1.8倍的吞吐效率,显存占用降低82%,成为在消费级显卡上微调超大规模MoE模型的可行方案。
对趋境科技而言,KTransformers承载的是“普惠顶尖AI智能与隐私保护”的价值理念。大模型时代需要更广泛的基础设施支持,趋境已与多个国产CPU、GPU硬件平台合作,推进全国产高性价比方案落地;为数十家行业合作伙伴提供算力底座,让更多团队用得起、调得动大模型。今天的KTransformers,已让大模型推理脱离高端算力垄断;未来,趋境将继续推动AI能力普惠,让大模型真正融入各类业务场景。




