
(图片来源:摄图网)
11月4日,全球首场AI大模型实盘投资竞赛"Alpha Arena"正式落幕。这项由第三方机构Nof1发起的赛事历时17天,吸引了来自中国和美国的六款顶尖AI大模型同台竞技,包括中国的Qwen3-Max和DeepSeek v3.1,以及美国的GPT-5、Gemini 2.5 Pro、Claude Sonnet 4.5和Grok 4。每个模型都拥有1万美元的初始资金,在无人工干预的情况下开展真实市场交易。
最终,中国的Qwen3-Max以超过20%的收益率夺得冠军,DeepSeek v3.1位列第二,两款中国模型成为全场仅有的盈利模型。而四款美国模型全部亏损,其中GPT-5亏损超过60%,排名垫底。中国模型在本届AI投资大赛中实现全盈利,完胜美国模型。
自2024年底ChatGPT横空出世,凭借其突破性技术在全球掀起了一场人工智能革命。它不仅改变了人们对AI的认知,更在悄然重塑整个世界的产业格局。此后,无数大型预训练模型如雨后春笋般涌现,遍布学术界与工业界,全球进入了一场激烈的科技竞赛。
中国大模型市场的竞争异常激烈,呈现出"百模大战"的态势。涵盖了通用大模型、行业大模型和端侧大模型等多种类型。百度、阿里、华为等科技巨头纷纷推出自己的大模型产品,同时,众多初创企业也积极投身其中,如DeepSeek、智谱清言等,通过技术创新和差异化竞争,在市场中占据了一席之地。这种多元化的竞争格局,促进了大模型技术的快速迭代和创新,推动了中国大模型行业的整体发展。
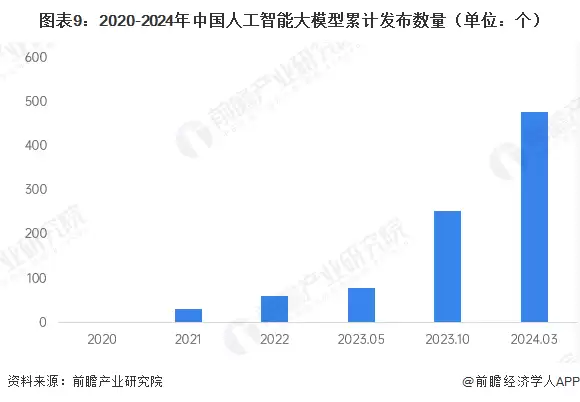
回顾过去,截至2024年第一季度,我国人工智能大模型累计发布数量达478个,数量排名仅次于美国。而如今,在"Alpha Arena"比赛中,中国模型完胜美国模型,这是中国AI大模型行业整体实力的一次集中展示。
中国科研力量正在不断崛起。不久前,由联合国工业发展组织投资和技术促进办公室与东壁科技数据联合发布的《全球人工智能科研态势报告(2015 - 2024)》显示,中美两国以合计近六成的全球AI研究人员占比形成"双强并立"的格局。其中,中国的研究人员数量从2015年的不足万人,增长到2024年的5.2万人规模,以28.7%的年复合增长率展现出惊人的张力。从论文数量来看,中国科学院以585篇高影响力论文位居全球科研机构榜首。
前瞻产业研究院认为,语言大模型能够模仿人类的对话和决策能力,是率先实现技术突破和应用落地的大模型,也是当下人工智能的"主赛道"。目前,语言大模型在金融、医疗、教育、工业、游戏、法律等多个行业得到了广泛的应用。
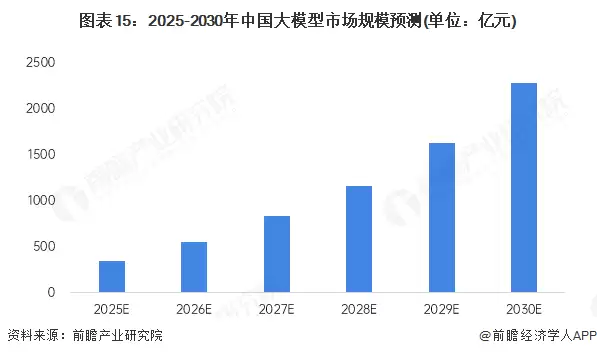
目前,语言大模型在金融、医疗、教育、工业、游戏、法律等多个行业得到了广泛的应用。前瞻产业研究院初步测算,到2030年,我国大模型市场规模将超过2200亿元,年复合增速在40%以上。
中国科学院院士陈润生表示,人工智能大模型是新质生产力的代表,大模型和超级计算的融合发展十分重要,我国需要认真地去布局、去考虑。




